标签:
公司使用angularJs(以下都是指ng1)框架做了互联网应用,之前没接触过seo,突然一天运营那边传来任务:要给网站做搜索引擎优化,需要研发支持。搜了下发现单页面应用做seo比较费劲,国内相关实践资料分享出来的也比较少,略懵,前后花了一番功夫总算完成了。在这里记录下来,做一个总结,也希望能够帮助在做类似工作的朋友少走一点弯路。还是建议需要seo的网站技术选型尽量不要使用angular react一类的单页面框架。如果你和我一样网站做完了发现需要seo,那么往下看吧。如果各位已有更优的方案欢迎拍砖交流。
单页面应用seo的困难在哪里?
做seo必须了解爬虫工作的基本原理。 搜索引擎能够搜到一个网页是因为对其做了索引,而在这之前需要爬虫抓取到网站页面存储为一个快照,快照的内容即页面的静态内容。一般来说,右键查看网页源代码看到的内容即爬虫所能抓取到的内容。爬虫拿到一个url后抓取其页面信息,查找页面中的a标签,拿到下一个url跳转地址,继续下一个页面抓取。seo的工作目的是增加搜索引擎对网站的索引量以及提升网页排名,传统的seo工作例如站内tdk的优化、网站url优化、外链增加都是为了达到这些目的。做到这些有一个共同的前提,就是网页内容能够被搜索引擎抓取到,而单页面应用seo的困难就卡在这里。
如果你的应用是angularjs这类单页面应用开发的,右键查看源代码你会发现网站没有动态数据。很遗憾、搜索引擎来抓取的页面也会是这样。这主要是因为两点原因:
路由、模板和ajax请求
angular实现单页面的方案是利用了路由机制配合模板引擎。通过自定义模板,一个应用只有一个主页面,通过路由切换不同的状态,嵌套对应的模板引擎。而模板中的动态数据,都是通过ajax请求从后端拿到的。这从路由跳转到渲染出完整页面的过程,除了主页面基本的静态数据,其他的全靠js来完成。
爬虫不执行js
第一条明白之后看到这里也就很明显了。很遗憾,爬虫不执行js脚本,这个也不难理解,搜索引擎每天都有海量的页面要抓取,执行js会大大降低效率;另外搜索引擎执行js脚本也存在着巨大的安全隐患。
搜索引擎拿到一个url后,获取,结束,仅仅拿到主页面中了了的几行静态信息。angular框架维护的路由、主页面,以及前端像后端发起的ajax请求等等js完成的工作,搜索引擎一概不会处理。
url优化
可抓取方案放到下面,先说说url优化。用过angularjs的都知道,ng的url是靠#来标识一个状态。含#类似符号的url对于seo是非常不友好的,而且据同事反应(本人没有验证),搜索引擎在访问url的时候并不会带着#后的内容去访问。总之,url优化是单页面应用seo绕不开的一个工作,而我们的目的,是把url优化成如同 www.xxx.com/111/222/333 目录结构的url,它是爬虫最喜欢的形态。
如何去除ng框架url中的#,google和百度都能够搜到不少资料。如:http://blog.fens.me/angularjs-url/
简单来说,去除#只需要在路由中配置$locationProvider.html5Mode(true); 开启html5模式,url会自动去除#以及.html后缀达到最优。但这时存在问题:f5刷新会404找不到页面,原因是f5会把url提交到后端获取资源,而html5模式优化后的url在后端并不存在这样一个资源,直接访问这个链接会连主页面都找不到,自然就会404。以上链接给出的方案是nodejs后端的方案,我们的方案是用springMVC后端,不过原理都是类似的:后端不认识这个链接,我们就把这个错误的连接重定向到原本带#的连接,对于后端来说就是一个正常的访问,而url中的#在浏览器端会再次被html5模式给去除。
重定向的工作可以放在后端springMVC的过滤器中解决,也可以在容器中解决。我们的框架是后端用nginx做负载均衡,我将重定向放在nginx.conf中,对每个路由状态的url都做了对应的原始url重定向,问题解决。无论如何刷新、访问,页面都是简单舒适的目录结构url。
两种可抓取解决方案
url优化之后,继续往下看。说白了我们要做的就是单页面应用的可抓取方案,即:如何让搜索引擎能够获取到完整内容的页面信息。我调研了现有的一些解决方案,思路都是类似的。搜索引擎不执行js,我们改变不了,那么我们只有像照顾婴儿一样,自己将js执行,拿到模板以及动态数据渲染出一个完全静态的页面,交给爬虫。我调研过git上的两个方案,做一个分享,如果大家有更好的方案也欢迎分享。
方案一、
https://github.com/johnhuang-cn/AngularSEO,这是一个java后端的解决方案。主要分为两块:服务端过滤器,本地爬虫。服务端过滤器有两个作用:一是为了拿到url,二是识别搜索引擎请求并重定向到本地快照;本地爬虫是为了渲染页面为本地快照。工作流程大致如下:
web.xml中配置上过滤器,第一次访问网站的时候过滤器抓取到url,交给本地爬虫。这个爬虫是一个拥有动态数据抓取能力的爬虫,主要利用了selenium+phantomjs框架,关于这两个框架可以自行google,其中phantomjs是一个webkit内核。它能够抓取动态数据的原因就在于它可以获取dom元素执行事件以及相关js。在获取到完整的页面信息后,它会将形如:http://abc.com/#/about的url对应静态存储到本地命名为http://abc.com/_23/about 的快照。也就是说,我们需要等待本地爬虫将每个url渲染出本地快照,然后爬虫来访问时,过滤器重定向到对应的快照页面。过滤器如何识别爬虫呢?是通过http包头中的userAgent,每个搜索引擎拥有自己的userAgent,在过滤器内配置上即可。
优点:这个方案有几个优点。1、部署相对简单,对于java应用来说,配置相对方便简单。2、搜索引擎访问效率较快,由于快照已经被保存好了,搜索引擎来抓取后直接会返回静态页面。
弊端:这个方案同样存在几个弊端。1、本地爬虫抓取速度慢,对于我们拥有海量动态数据的如资讯模块,保存快照是个耗时的工作。2、实时性,框架通过配置本地爬取频率来更新快照,意味着搜索引擎抓取页面的实时性受限于更新频率。3、稳定性,不知道现在是否还存在这些问题,可能由于当时该框架还不很成熟,我在试用中,本地爬虫的激活不够稳定,另外phantomjs进程出现过无法退出的现象,导致后台开启大量phantomjs内存耗尽。4、分布式部署问题,我们利用nginx负载均衡做了后端集群,搜索引擎来了之后按规则分配到不同后端,导致使用此框架需要在每个后端部署,引来一系列不便和问题。
由于以上弊端,此方案最终被我放弃了。
方案二、prerender.io
该方案是我调研过程中找到的相对成熟的解决方案,较为完美的解决了我的需求。原理图如下,可参考:http://www.cnblogs.com/whitewolf/p/3464555.html
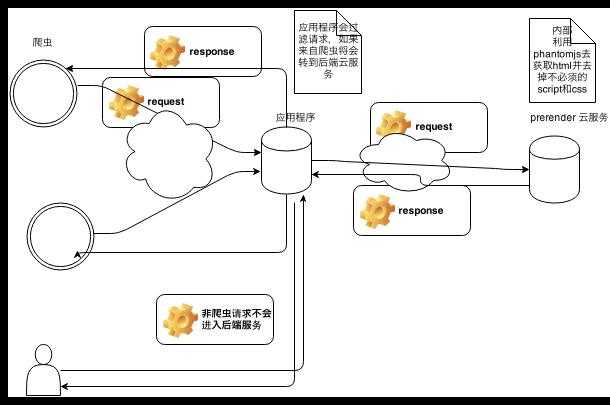
prerender.io也分为两块,客户端以及服务端prerender服务,客户端的工作是识别搜索引擎请求并做重定向(和方案一类似),除了userAgent它还会通过escaped_fragment做搜索引擎识别,这是谷歌的一套可抓取方案,详情可见:Google‘s ajax crawling protocol。如果你的站点主要是做国内浏览器的优化基本可以忽略,单使用userAgent足够了。prerender服务端负责接收客户端重定向过来的请求,拿到请求后再次去向web后端做请求,同样,prerender后端集成了phantomjs,来执行js获取动态数据。拿到完整的页面数据之后,prerender后端将完整页面返回给搜索引擎。
prerender的客户端现在拥有很多种技术实现,基本可以满足各类技术方案。服务端拥有两种选择:1、使用官方提供的prerender.io云服务 2、搭建自己的prerender后端服务。官网上的介绍推荐使用云服务,不过官网需要FQ,而且使用别人的服务稳定性总是令人担忧的,我选择了自己部署prerender服务。它其实就是个单独在跑的nodejs进程,使用forever指令跑起来之后还是很稳定的。
优点:1、高实时性,通过上面分析可以明白prerender服务是实时拿到搜索引擎请求去做页面渲染的,这意味着一次部署后如果站点没有大的改动便没有了后续工作,搜索引擎得到的每一次返回内容和用户访问的一样都是最新的数据。2、分布式部署,prerender服务是完全和web应用分离的一个进程,不管后端有多少集群都和部署互不影响。3、稳定性,框架已经相对成熟,缓存机制、黑白名单体验起来都很不错。prerender服务用forever守护进程跑起来之后基本上没有遇到不稳定的问题。
缺点:1、搜索引擎抓取效率,页面是实时渲染的,搜索引擎抓取起来自然会慢一些,不过这个我们并不很关心。
比较两个方案我自然选择了prerender的方案,部署实践的过程也遇到过一系列问题,如果需要我后续会写prerender部署实践文章。
总结
总的来说,单页面应用可抓取的最大问题就在于搜索引擎不执行js,解决方案无非就是我们自己做动态数据渲染然后喂给爬虫。确定了这些,即使自己去完成这样一个框架也不是一件困难的事了。
基于angularJs的单页面应用seo优化及可抓取方案原理分析
标签:
原文地址:http://www.cnblogs.com/ideal-lx/p/5625428.html