标签:
博客中的文章均为meelo原创,请务必以链接形式注明本文地址
描述一个网页
现在的世界处于一个信息爆炸的时代。微信、微博、新闻网站,每天人们在大海捞针的信息海洋里挑选自己感兴趣的信息。我们是如何判断哪条信息可能会感兴趣?回想一下,你会发现是标题、摘要和缩略图。通过标题、摘要和缩略图,就能够很好地猜测到网页的内容。打开百度搜索引擎,随便搜索一个关键字,每一条搜索结果也正是这三要素构成的。

那么一个自然的问题是搜索引擎是如何找到网页的标题、摘要和缩略图的呢。
寻找网页的标题其实是一个非常简单的问题。这要从网页的原理说起了。网页其实是一个特殊的文件,和熟悉的Word文档是类似的。Word文档里有标题,有正文,文字可以有不同的字体、颜色,网页也是类似的。不过网页的设计更加自由,他不是由可视化的界面来设计的,而是通过一种专门的编程语言,HTML(Hyper Text Markup Language)来编写的。基本上HTML就是一系列标记,每一个标记由一个开始标记,和一个结束标记组成。比如<title>表示这是标题的开始,</title>表示这是标题的结束,没错结束标记只比开始标记多一个反斜杠。每一个网页都要求必须包含一个标题,这是非常合情合理的,这个标题也许不是你在网页里看到的那个标题,但一定会是和网页内容相关的。
那么如何去寻找缩略图呢。网页的标准并没有规定必须要包含缩略图,所有无尽的麻烦就开始了。不同的地方有不同的解决方案。
Facebook的解决方案是,规定一个新的标准,在网页里新定义一系列标签,来标记网页的缩略图、关键字,这个计划叫做“开放图谱计划”。Facebook启动这个计划的时候是在Facebook最高级的F8开发者大会上,当时可谓盛世号大。但是一个公司定义的标准难以被所有人接受,事实是在中国“开放图谱计划”普及率非常低。
要从根本上解决这个问题,要么定义一个被普遍接受的标准,这几乎不可能,要么另辟蹊径。
此时把眼光投向机器学习。如果你稍微关注一点科技的话,你应到了解最近机器学习很火,火到什么程度呢,连跳广场舞的大妈都在谈论那个打败曾经围棋世界冠军的AlphaGo。AlphaGo的背后就是神秘的机器学习算法,曰深度增强学习。这不是我们关注的重点,计算机从襁褓中出来,到战胜人类经历了一个漫长的过程。但是最基本的原理却是十分简单的。机器学习需要解决的一个基本问题就是预测未来。
机器学习解密
假设我们想要预测北京市一处房屋的价格。对于机器学习来说,首先要采集大量已知房屋的价格,当然需要数据表示房屋的情况,比如房子的面积,卧室的数量,距离市中心的距离,建筑的年限。如果想要尽可能准确地预测,对房屋的描述要尽可能的全面,尽可能地考虑到实际影响房屋价格的因素。在机器学习的术语中,描述房子的数据叫做特征(feature),需要预测的房屋价格叫做目标(target),事先采集的特征及对应的目标叫做训练数据(training data)。从数学的角度来说,通过机器学习得到的是一个函数,输入是特征,输出就是目标,这个函数有时也叫做模型(model)。不同的机器学习算法会得到不同的函数,没有一种算法是最优的,在不同的情形下会选择不同的算法,这不是本文介绍的重点。最简单的一种机器学习算法是最小二乘法(least square),也许很早你就再别处听说过最小二乘法,但你也许没有意识到它的强大。
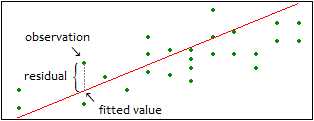
机器学习算法得到的函数尽可能地使训练数据的误差尽可能低。根据机器学习的一个原则“可扩展性”,“可扩展性”好意味着对于新的数据同样能够得到误差很低的预测值。
如此以来寻找缩略图就可以变成一个机器学习的问题了。在此之前需要明确一下什么是缩略图,一个网页里面平均有几十张图片,其中有那么几类,比如新闻的配图这可以作为缩略图、网站的LOGO、二维码、广告等等。这个问题和之前预测房屋的价格还有些差异,即目标不再是连续的值,而是离散的两类,与网页内容相关的可以作为缩略图的图片,和无关的图片。
问题的难点
有一个笑话说,机器学习工程师的主要任务是“特征工程”。如果你不知道什么是特征工程,特征工程其实就是寻找能够预测目标的特征。预测房屋的价格,如果漏掉了房子的面积,肯定预测的结果是非常不准确的。
对于本问题也是一样,特征是决定成败的关键。不过寻找特征更不容易,首先,提取特征的过程必须是一个通过程序自动完成的,而不是人工统计;其次,能够直接提取的特征非常少,图片最明显的特征不过是宽度和高度;最后,网页的标准HTML非常灵活,图片可以有注释也可以没有。
特征工程没有什么好的办法解决。只能使用最直接的方法,分析相关图片的HTML代码。比如我找到很好的一个特征是是图片的面积,网页的LOGO和二维码相较于新闻的配图会比较小,因此图片的面积越到越有可能是相关图片。
在搜寻特征过程中得到的另外一个启示是图片的特征不仅仅有图片本身决定,还与图片周围的环境有关,这能够解决图片本身特征很少的问题。我找到的另外一个很好的特征是图片是否在大段文字当中。图片夹在大段文字里,意味着图片是在网页的正文里,说明很高的可能性是一个相关图片了。在大段文字当中在HTML代码中的体现是,图片的附近有很多表示段落的标签<p>。
HTML非常灵活,其实没有什么完美的解决方案。我只能分析主流的网站,使提取特征的代码覆盖尽可能多的情况。还是拿判断图片是否在大段文字中为例,这个特征其实是一个数值,表示图片周围表示段落的标签<p>的个数。图片有时与<p>标签在同一级,有时在<p>标签的直接子树中,有时在<p>标签子树的子树中。
有了每一个特征的描述,编写程序并不是一个太大的问题。其中用到的一个技术是文档对象模型(Document Object Model),HTML其实是一个文本文档,直接操作非常不易,有一个专门的程序将HTML转换成DOM。通过DOM可以方便地定位到每一张图片,获取图片的父标签,获取图片的子标签。
体验一下吧
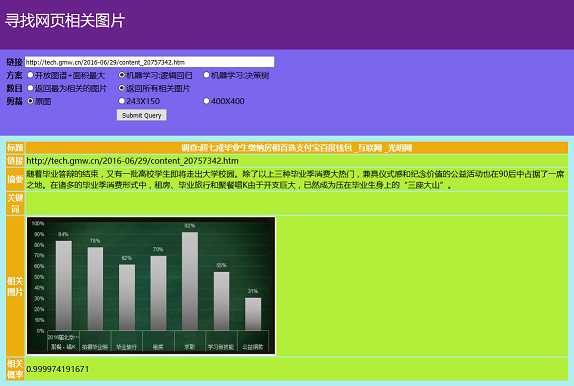
最终得到的是一个完整系统,输入一个图片的链接,网页就能返回预测的最相关的图片。有几个选项可以选择,首先是选择哪种机器学习算法,本文并没有详细介绍,可以使用的两种算法是逻辑回归和决策树;然后是选择返回所有的相关图片还是最为相关的一张图片。所有返回的图片都会有一个预测相关的概率。系统可以在网页上体验。
标签:
原文地址:http://www.cnblogs.com/meelo/p/5628261.html