标签:
以下内容参考自鱼C论坛,并进行了修改,原帖【排序技术哪家强,各种排序算法。】http://bbs.fishc.com/thread-56352-1-1.html
1. 选择排序。
每次选择最小的一项放到最前面。
效率 : 需要的次数是取决于列表的长度。
2. 冒泡排序。
每两个数比较,互换。每轮选出最大的数放到最顶端。
效率: 因为不会一次性换完,效率最小会是列表长度的平方。(慢。)
改进了两个版本,具体见代码
3. 插入排序。
对于一个确定的数i,统计比i小的数的个数,然后将i插入到该索引位置。
效率: 最差应该是列表长度的平方,但是比冒泡要好(至少我试的是这样)。
插入排序又分两种,一种是直接插入,一种是二分插入,见代码。
4. 快速排序。
从待排序数列中任选一个数,将其余数与之比较,比它大的插到右边,小的插到左边,这样就确定了该数在数列中的位置;然后对左右两边各进行上述方法。
效率: 高,要不怎么叫快速排序~,人品不好也只能是列表长度的平方了。
5.堆排序。
感觉不会用二叉树,所以就不研究这个了,哈哈。
6. 归并排序。
就是把两个已经有序的数列合到一起,构成一个新的有序数列。效果图。(代码就不写了)
7. 各个方法比较。
随机生成了5个乱序数组,其长度为10,100,1000,10000,20000。每种方法的执行时间如下,其中buildin是python数组内建的排序方法,尼玛效率怎么这么高?(*注:执行时间已经进行了开50次方,便于作图)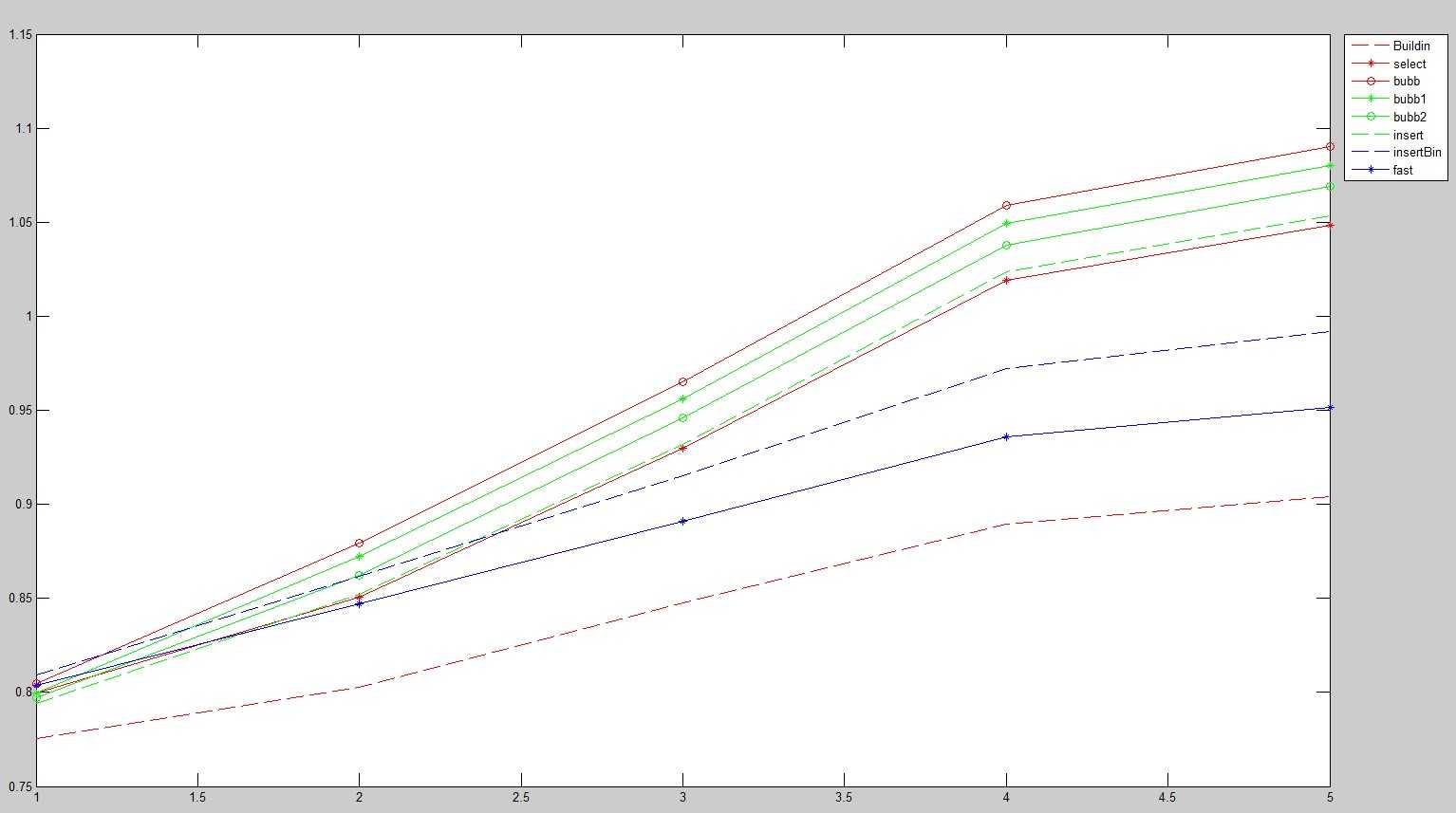
具体的执行时间如下
Buildin =[0.000003,0.000017,0.000257,0.002901 ,0.006495];
select =[0.000014,0.000311,0.025999,2.574872 ,10.566038];
bubb =[0.000019,0.001603,0.168447,17.437580,74.291987];
bubb1 =[0.000014,0.001091,0.105978,11.102826,46.860289];
bubb2 =[0.000012,0.000610,0.062345,6.379967 ,28.134702];
insert =[0.000010,0.000335,0.029598,3.235186 ,13.360413];
insert_bin =[0.000025,0.000588,0.012024,0.245504 ,0.664790];
fast =[0.000018,0.000249,0.003099,0.036436 ,0.082707];
代码如下:
import random
import time
# def Gen_sequence_disorder(a = 0, b = 10 ,num = 10):
# """generate a series integer num\n(a,b){num}"""
# seq = []
# for i in range(num):
# seq.append(random.randint(a,b))
# return seq
def Gen_sequence_disorder(a = 0, b = 10 ,num = 10):
seq = [random.randint(a,b) for i in range(num)]
return seq
def compare(lsta = [], lstb = []): #两个列表进行比较,不全等则返回True,用于测试排序算法是否正确
for i in range(len(lsta)):
if lsta[i] - lstb[i]:
return True
return False
def sel_sort(lst = []):#选择排序,每轮选出待排序中最小的数
newlist = []
for i in range(len(lst)):
newlist.append(min(lst))
lst.remove(min(lst))
return newlist
def bubb(lst = []):#冒泡排序,每轮选出最大的数放到最顶端
for i in range(len(lst)):
for j in range(len(lst) - 1):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
def bubb_1(lst = []):#冒泡排序改进,每轮选出最大的数放到最顶端,由于每经过一轮后,最顶端的几个数顺序已确定,因此不需要再遍历
for i in range(len(lst)):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
return lst
def bubb_2(lst = []):#冒泡排序改进,每轮选出最小的数放到最底端,由于每经过一轮后,最底端的几个数顺序已确定,因此不需要再遍历
for i in range(len(lst)):
for j in range(len(lst) - 1, i, -1):
if lst[i] > lst[j]:
lst[i], lst[j] = lst[j], lst[i]
return lst
def insert(lst = []):#插入排序,对于一个确定的数i,统计比i小的数的个数,然后将i插入到该索引位置
for i in range(1, len(lst)):
j = 0
while lst[i] > lst[j]:
j += 1
results = lst[i]
lst.pop(i)
lst.insert(j, results)
return lst
def insert_bin(lst = []):#插入排序,插入的时候使用二分法查找待排序的位置
def bin_lookup(num, a = 0, b = 1):
if a < b - 1:
if num > lst[(a + b) // 2]:
return bin_lookup(num, (a + b) // 2, b)
elif num < lst[(a + b) // 2]:
return bin_lookup(num, 0, (a + b) // 2)
else:
return (a + b) // 2
else:
if num < lst[a]:
return a
else:
return b
for i in range(1,len(lst)):
lst.insert(bin_lookup(lst[i], 0, i), lst[i])
lst.pop(i + 1)
return lst
def fast(lst = []):#快速排序
if len(lst) <= 1:
return lst
else:
temp1 = [i for i in lst[1:] if i < lst[0]]
temp2 = [i for i in lst[1:] if i >= lst[0]]
return fast(temp1)+ lst[:1] +fast(temp2)
def heap(lst = []):#堆排序
pass
def merge(lst = []):#归并排序
pass
if __name__ == "__main__":
a, b, c = 0, 500000, 20000
seq = Gen_sequence_disorder(a, b, c)
t1 = time.clock() #内置排序
seq_sortedByBuildin = sorted(seq[:])
t2 = time.clock()
print(‘%-25s%f‘%(‘Buildin sort time : ‘,(t2 - t1)))
t1 = time.clock() #选择排序
seq_sortedBySel = sel_sort(seq[:])
t2 = time.clock()
if compare(seq_sortedBySel, seq_sortedByBuildin):
print(‘seq_sortedBySel‘)
print(‘%-25s%f‘%(‘select sort time : ‘,(t2 - t1)))
t1 = time.clock() #冒泡排序
seq_sortedBybubb = bubb(seq[:])
t2 = time.clock()
if compare(seq_sortedBybubb, seq_sortedByBuildin):
print(‘seq_sortedBybubb‘)
print(‘%-25s%f‘%(‘bubb sort time : ‘,(t2 - t1)))
t1 = time.clock() #冒泡排序1
seq_sortedBybubb_1 = bubb_1(seq[:])
t2 = time.clock()
if compare(seq_sortedBybubb_1, seq_sortedByBuildin):
print(‘seq_sortedBybubb_1‘)
print(‘%-25s%f‘%(‘bubb1 sort time : ‘,(t2 - t1)))
t1 = time.clock() #冒泡排序2
seq_sortedBybubb_2 = bubb_2(seq[:])
t2 = time.clock()
if compare(seq_sortedBybubb_2, seq_sortedByBuildin):
print(‘seq_sortedBybubb_2‘)
print(‘%-25s%f‘%(‘bubb2 sort time : ‘,(t2 - t1)))
t1 = time.clock() #插入排序
seq_sortedByinsert = insert(seq[:])
t2 = time.clock()
if compare(seq_sortedByinsert, seq_sortedByBuildin):
print(‘seq_sortedByinsert‘)
print(‘%-25s%f‘%(‘insert sort time : ‘,(t2 - t1)))
t1 = time.clock() #插入排序2
seq_sortedByinsert_bin = insert_bin(seq[:])
t2 = time.clock()
if compare(seq_sortedByinsert_bin, seq_sortedByBuildin):
print(‘seq_sortedByinsert_bin‘)
print(‘%-25s%f‘%(‘insert_bin sort time : ‘,(t2 - t1)))
t1 = time.clock() #插入排序2
seq_sortedByfast = fast(seq[:])
t2 = time.clock()
if compare(seq_sortedByfast, seq_sortedByBuildin):
print(‘seq_sortedByfast‘)
print(‘%-25s%f‘%(‘fast sort time : ‘,(t2 - t1)))
标签:
原文地址:http://www.cnblogs.com/christsong/p/5629559.html