标签:
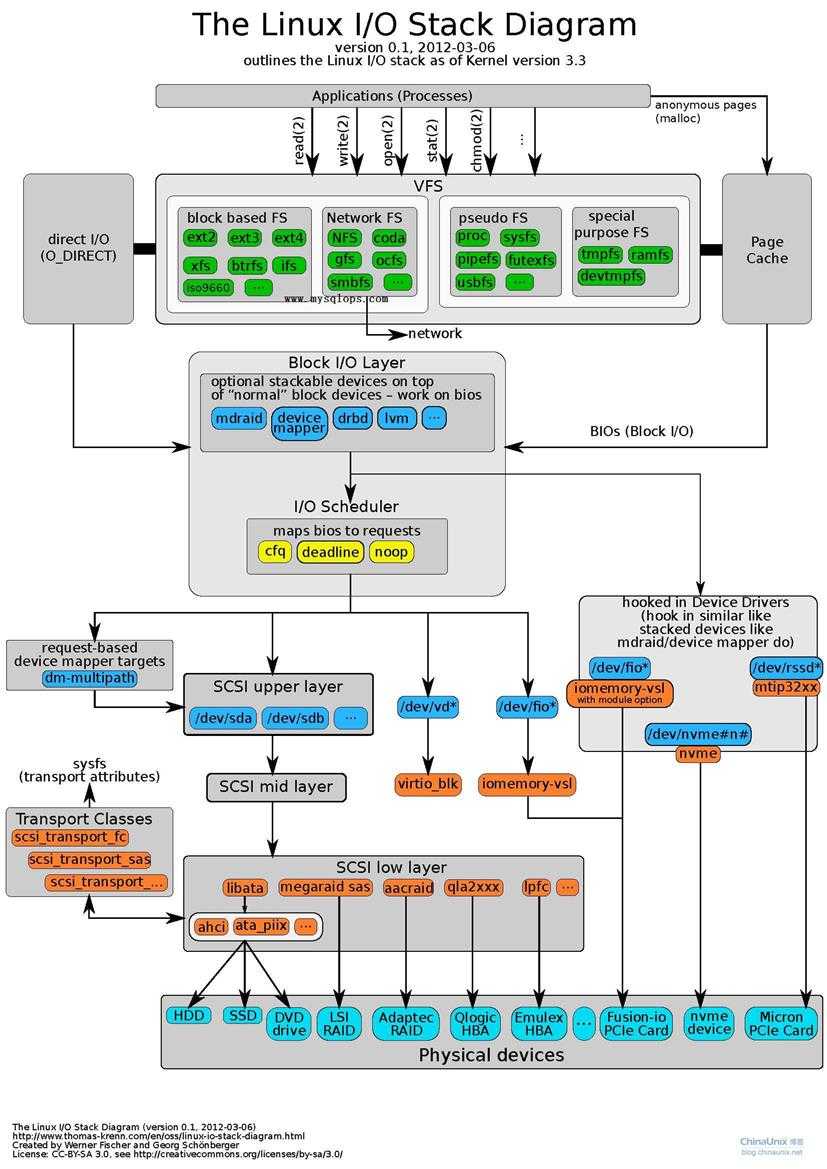
下图清晰地说明了Linux I/O层次结构:
写文件过程
写文件的过程包含了读的过程,文件先从磁盘载入内存,存到cache中,磁盘内容与物理内存页间建立起映射关系。用于写文件的write函数的声明如下:
其中fd对应进程的file结构, buf指向写入的数据。内核从cache中找出与被写文件相应的物理页,write决定写内存的第几个页面,例如"echo 1 > a.out"(底层调用write)写入的是a.out文件的第0个位置,write将写相应内存的第一页。
write函数修改内存内容之后,相应的内存页、inode被标记为dirty,此时write函数返回。注意至此尚未往磁盘写数据,只是cache中的内容被修改。
那什么时候内存中的内容会刷到磁盘中呢?
把脏数据刷到磁盘的工作由内核线程flush完成,flush搜寻内存中的脏数据,按设定将脏数据写到磁盘,我们可以通过sysctl命令查看、设定flush刷脏数据的策略:
以上数值单位为1/100秒,“dirty_writeback_centisecs = 500”指示flush每隔5秒执行一次,“dirty_expire_centisecs = 3000” 指示内存中驻留30秒以上的脏数据将由flush在下一次执行时写入磁盘,“dirty_background_ratio = 10”指示若脏页占总物理内存10%以上,则触发flush把脏数据写回磁盘。
flush找出了需要写回磁盘的脏数据,那存储脏数据的物理页又与磁盘的哪些扇区对应呢?
物理页与扇区的对应关系由文件系统定义,文件系统定义了一个内存页(4KB)与多少个块对应,对应关系在格式化磁盘时设定,运行时由buffer_head保存对应关系:
文件系统层告知块I/O层写哪个设备,具体哪个块,执行以下命令后,我们可以在/var/log/messages中看到文件系统层下发到块层的读写请求:
块I/O层使用struct bio记录文件系统层下发的I/O请求,bio中主要保存了需要往磁盘刷数据的物理页信息,以及对应磁盘上的扇区信息。
块I/O层为每一个磁盘设备维护了一条I/O请求队列,请求队列在内核中由struct request_queue表示。每一个读或写请求都需经过submit_bio函数处理,submit_bio将读写请求放入相应I/O请求队列中。该层起到最主要的作用就是对I/O请求进行合并和排序,这样减少了实际的磁盘读写次数和寻道时间,达到优化磁盘读写性能的目的。
使用crash解析vmcore文件,执行"dev -d"命令,可以看到块设备请求队列的相关信息:
执行以下命令,可以查看sda设备的请求队列大小:
如何对I/O请求进行合并、排序,那就是I/O调度算法完成的工作,Linux支持多种I/O调度算法,通过以下命令可以查看:
块I/O层的另一个作用就是对I/O读写情况进行统计,执行iostat命令,看到的就是该层提供的统计信息:
其中rrqm/s、wrqm/s分别指示了每秒写请求、读请求的合并次数。
task_io_account_read函数用于统计各个进程发起的读请求量, 由该函数得到的是进程读请求量的准确值。而对于写请求,由于数据写入cache后write调用就返回,因而在内核的层面无法统计到一个进程发起的准确写请求量,读时进程会等buff可用,而写则写入cache后返回,读是同步的,写却不一定同步,这是读写实现上的最大区别。
再往下就是设备层,设备从队列中取出I/O请求,scsi的scsi_request_fn函数就是完成取请求并处理的任务。scsi层最终将处理请求转化为指令,指令下发后进行DMA(direct memory access)映射,将内存的部分cache映射到DMA,这样设备绕过cpu直接操作主存。
设备层完成内存数据到磁盘拷贝后,该消息将一层层上报,最后内核去除原脏页的dirty位标志。
以上为写磁盘的大致实现过程,对于读磁盘,内核首先在缓存中查找对应内容,若命中则不会进行磁盘操作。若进程读取一个字节的数据,内核不会仅仅返回一个字节,其以页面为单位(4KB),最少返回一个页面的数据。另外,内核会预读磁盘数据,执行以下命令可以看到能够预读的最大数据量(以KB为单位):
下面我们通过一段systemtap代码,了解内核的预读机制:
以上代码指示当dd命令读写inode号为5234的文件、经过内核函数submit_bio时,输出inode号、操作方式(读或写)、文件所在设备名、读写大小、扇区号信息。执行以下代码安装探测模块:
之后我们使用dd命令读取inode号为5234的文件(可通过stat命令取得文件inode号):
以上命令故意将bs设为1,即每次读取一个字节,以此观察内核预读机制。执行该命令的过程中,我们在终端中可以看到以下输出:
由以上输出可知,预读从16384字节(16KB)逐渐增大,最后变为524288字节(512KB),可见内核会根据读的情况动态地调整预读的数据量。
由于读、写磁盘均要经过submit_bio函数处理,submit_bio之后读、写的底层实现大致相同。
直接I/O
当我们以O_DIRECT标志调用open函数打开文件时,后续针对该文件的read、write操作都将以直接I/O(direct I/O)的方式完成;对于裸设备,I/O方式也为直接I/O。
直接I/O跳过了文件系统这一层,但块层仍发挥作用,其将内存页与磁盘扇区对应上,这时不再是建立cache到DMA映射,而是进程的buffer映射到DMA。进行直接I/O时要求读写一个扇区(512bytes)的整数倍,否则对于非整数倍的部分,将以带cache的方式进行读写。
使用直接I/O,写磁盘少了用户态到内核态的拷贝过程,这提升了写磁盘的效率,也是直接I/O的作用所在。而对于读操作,第一次直接I/O将比带cache的方式快,但因带cache方式后续再读时将从cache中读,因而后续的读将比直接I/O快。有些数据库使用直接I/O,同时实现了自己的cache方式。
异步I/O
Linux下有两种异步I/O(asynchronous I/O)方式,一种是aio_read/aio_write库函数调用,其实现方式为纯用户态的实现,依靠多线程,主线程将I/O下发到专门处理I/O的线程,以此达到主线程异步的目的。
另一种是io_submit,该函数是内核提供的系统调用,使用io_submit也需要指定文件的打开方式为O_DIRECT,并且读写需按扇区对齐。
Reference: Chapter 14 - The Block I/O Layer, Linux kernel development.3rd.Edition
标签:
原文地址:http://www.cnblogs.com/zengkefu/p/5635058.html