标签:
抢购钻石不稀奇,稀奇的是有钱赚不到,事情发生在2015年5月20日,大好的日子自然少不了商家的参与。即可为您还原现场,解决思路献给各位,请欣赏Show Time,everybody~
2014年5月20日下午三点四十接到对方不愿意透漏姓名的“王大锤”领导的电话,对方火急火燎的仅提供了网站访问慢一条信息,当时博主那个心里一万只XX奔腾而过,俗话说的好,酒肉穿肠过,拿人钱财必替人消灾。
对博主来说网站访问慢,首先不能乱了阵脚,先想到的就是看web、先看静态,如果静态ok就看动态,如果还不ok就看存储,再不行就看访问DB时长是否正常。此时原因就可以定位了。不会再有其他原因了。如果你太菜,那你可以把我的思路背过,相信对你来说是一个很好的帮助,此时一边与对方沟通更可能多的获得信息,可是对方一点都不懂,只好无能为力,与对方协商相关责任制后立即登录服务器(本人兼职XX钻世界集团技术顾问一职)。
凭借个人经验查看web负载并不高,静态访问速度正常,由于线上活动正在进行,晚一分钟对商家即是损失,此时无法进行许多系统的排查,直接则判断是否是后端DB的问题?随登录DB查看负载。发现DB负载不正常,就没有进行其他的判断(什么IO看一下啊,内存看一下啊,网卡看一下啊,再看公司都倒闭了。),紧急恢复问题就是最大化的恢复问题,找到问题所在即刻解决问题。此时判断数据库有慢查询。
1 ================2015年5月20日 13:38:08日负载如下:================ 2 [lcp@ZCdb01 ~]$ uptime 3 13:50:36 up 122 days, 21:51, 1 user, load average: 6.44, 5.76, 5.38 4 5 [lcp@ZCdb01 ~]$ uptime 6 13:51:38 up 122 days, 21:22, 1 user, load average: 8.01, 6.30, 5.58
随登录数据库show full processlist;此工具运维人员必备,干了几年的运维别说你不会。不会的话看了我的博客也应该会了。
连抓了两遍之后发现,这一堆东西不动啊,前面排着的update被锁定,想写还写不进去。select过多,读也读不出来。
1 mysql> show processlist; 2 +----+-------------+-----------+------+---------+------+-----------------------------------------------------------------------------+------------------+
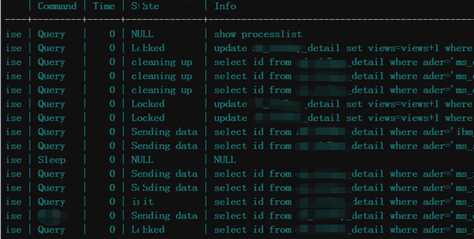
再返回来看后面的查询语句是通过三个条件进行查询的。于是定位了待优化的语句也就是下方的select出现次数最多的语句

↑↑↑查询语句如上↑↑↑
随后抓出一条命令explain,多次确认后加SQL_NO_CACHE不让其走缓存再反复确认,最终判断次语句没有建立索引或走索引,共查阅7万3千多条数据耗时惊人。
1 mysql> select SQL_NO_CACHE id from **_**_detail where ader=‘**_**-jazz_flash‘ and dateline=‘**_**‘ and pos=‘**_**‘;
此时看到可能走的索引和索引都是不存在的。独立奔跑在七万多条语句中
1 possible_keys:NULL 2 3 key:NULL 4 5 rows:71328 #接近全盘扫描
我记得这台机器是戴尔服务器2850很老的一台服务器,但这很明显不是硬件问题,随问对方的主管,有没有人对这台机器进行优化,一边电话询问一边进行查看,去证实自己的想法,使用show查看表结构show create table **_**_detai\G,果不其然,除了主键索引,一个索引都没有建立(为这台年老失修的服务器感到骄傲,它竟然扛了那么久授小弟一拜)。

扯淡归扯淡我们继续,此时已耗时3分钟,建立索引的规则相信大家也都清楚,此处不过多解释,一会看总结。得到以上结论后,查看哪一字段列的唯一值数量较多。使用select count(distinct XX)from **_**_detai;以上三个语句都使用次等命令查看,最后发现三列的数值为766/531/154都不高,原因是有一列是日期,它的唯一值是最少的,第二列看不懂。。
再使用select count(*) from **_**_detail;命令查看一下总数量达到了七万多条的数量。
根据以上的情况,而且查询语句里面也很特殊都是等号。这种情况下建立索引就容易走索引。这种情况下考虑走联合索引。根据以上信息及咨询研发经理其他语句的情况下,创建如下索引:
1 mysql> create index d_a_p on **_**_detail(dateline,daer(20),azz(10),pos(20));
语句的查询顺序是询问的研发经理,因为联合索引有前缀生效的特性,所以此时确定了索引之后并没有直接创建,而是与研发经理协商,此时需要杀掉几个读的请求。在前面选几个。show proacesslist;update根据业务需求去考虑。谨慎使用至于杀掉的方法..kill+id相信没几个不会的吧。
索引建立完成再使用explain查看索引是否生效,然后同样还是使用select+SQL_NO_CACHE参数不走缓存查询语句。发现此时仅扫描了12条语句,查询时间更是少之又少。
再次使用show proacesslist;查看mysql线程,几乎看不到了。说明效果很明显。
优化之后的负载,已经从之前的6.x、8.x慢慢下降为2.x,1.72,五分钟后降到了0.07、0.21的正常值
1 [lcp@ZCdb01 ~]$ uptime 2 13:59:09 up 120 days, 21:29, 2 users, load average: 2.40, 4.62, 5.09 3 [lcp@ZCdb01 ~]$ uptime 4 13:59:29 up 120 days, 21:29, 2 users, load average: 1.72, 4.32, 4.98 5 [lcp@ZCdb01 ~]$ uptime 6 13:59:30 up 120 days, 21:29, 1 users, load average: 1.66, 4.26, 4.95 7 [lcp@ZCdb01 ~]$ uptime 8 14:05:27 up 120 days, 21:35, 1 users, load average: 0.07, 1.39, 3.42 9 [lcp@ZCdb01 ~]$ uptime 10 14:05:35 up 120 days, 21:36, 1 users, load average: 0.21, 1.38, 3.40
问题判断+解决时长10分钟以内
优化判断+后期观察15分钟左右
此次问题解决总用时25分钟左右
此次问题由于对方对mysql数据库优化不到位,此公司并无相关技术人员,日常维护工作无法正常开展,导致突发状况访问异常。为保证以后服务器正常工作,优化完成后在配置文件(my.cnf)下添加如下参数记录慢查询语句。
1 long_query_time =2 #<==超过2秒,记录到LOG里。 2 3 log_queries_not_using_indexes #<==没有走索引的语句,记录到LOG里。 4 5 log-slow-queries = /data/3306/slow.log #<==LOG文件
但是建立索引的前提是,生产场景,表中数据多的情况下及高峰期不能建立索引,例如:300万记录。由于此次问题解决中使用的是联合索引,联合索引的特性是前缀生效,这也是有别于其他索引,所以创建时更为谨慎,需要与开发共同商议创建规则。否则索引无效。
关于mysql的优化从此次解决问题的过程中得出以下几个结论:
1、紧急情况抓慢查询SQL语句:
登录数据库
show full prcesslist;
2、未雨绸缪:重要不紧急:分析慢查询日志。(生成日志方法在上述总结中有具体参数)
分析慢查询SQL语句,每天定时发邮件给相关工作人员,核心开发、高级运维或DBA
每天切割慢查询日志,去重分析后发给大家。
切割方法:
1)mv ,relaod进程。2)cp,>清空
2)利用定时任务
以上分享内容到此结束,如有疑问欢迎发送邮件到lcp779401@cntv.cn探讨交流,希望对大家有所帮助。
标签:
原文地址:http://www.cnblogs.com/Vanos-lcp/p/5642097.html