标签:
以前总是追求新东西,发现基础才是最重要的,今年主要的目标是精通SQL查询和SQL性能优化。
本系列【T-SQL基础】主要是针对T-SQL基础的总结。
【T-SQL基础】01.单表查询-几道sql查询题
【T-SQL基础】02.联接查询
【T-SQL基础】03.子查询
【T-SQL基础】04.表表达式-上篇
【T-SQL基础】04.表表达式-下篇
【T-SQL基础】05.集合运算
【T-SQL基础】06.透视、逆透视、分组集
【T-SQL基础】07.数据修改
【T-SQL基础】08.事务和并发
【T-SQL基础】09.可编程对象
----------------------------------------------------------
【T-SQL性能调优】01.索引优化
【T-SQL性能调优】02.执行计划
【T-SQL性能调优】03.死锁分析
本篇主要是对SQL中事务和并发的详细讲解。
为单个工作单元而执行的一系列操作。如查询、修改数据、修改数据定义。
(1)显示定义事务的开始、提交
BEGIN TRAN
INSERT INTO b(t1) VALUES(1)
INSERT INTO b(t1) VALUES(2)
COMMIT TRAN
(2)隐式定义
如果不显示定义事务的边界,则SQL Server会默认把每个单独的语句作为一个事务,即在执行完每个语句之后就会自动提交事务。
(1)原子性Atomicity
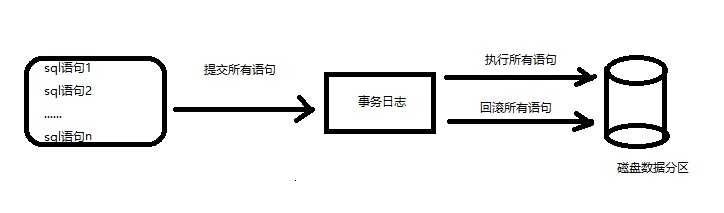
1.事务必须是原子工作单元。事务中进行的修改,要么全部执行,要么全都不执行;
2.在事务完成之前(提交指令被记录到事务日志之前),系统出现故障或重新启动,SQL Server将会撤销在事务中进行的所有修改;
3.事务在处理中遇到错误,SQL Server通常会自动回滚事务;
4.少数不太严重的错误不会引发事务的自动回滚,如主键冲突、锁超时等;
5.可以使用错误处理来捕获第4点提到的错误,并采取某种操作,如把错误记录在日志中,再回滚事务;
6.SELECT @@TRANCOUNT可用在代码的任何位置来判断当前使用SELECT @@TRANCOUNT的地方是否位于一个打开的事务当中,如果不在任何打开的事务范围内,则该函数返回0;如果在某个打开的事务返回范围内,则返回一个大于0的值。打开一个事务,@@TRANCOUNT=@@TRANCOUNT+1;提交一个事务,@@TRANCOUNT-1。
(2)一致性Consiitency
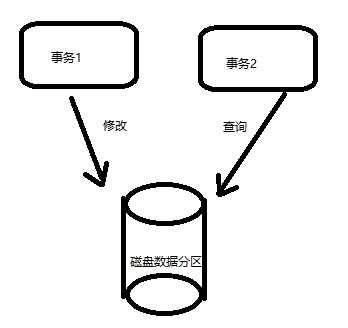
1.同时发生的事务在修改和查询数据时不发生冲突;
2.一致性取决于应用程序的需要。后面会讲到一致性级别,以及如何对一致性进行控制。
(3)隔离性Isolation
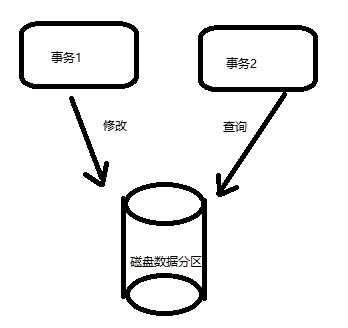
1.用于控制数据访问,确保事务只访问处于期望的一致性级别下的数据;
2.使用锁对各个事务之间正在修改和查询的数据进行隔离。
(4)持久性Durability
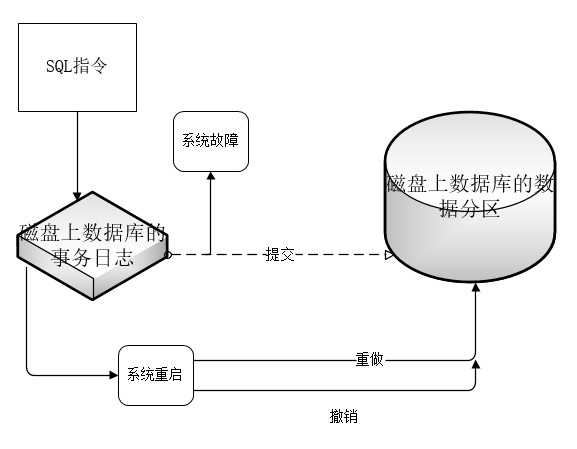
1.在将数据修改写入到磁盘上数据库的数据分区之前会把这些修改写入到磁盘上数据库的事务日志中,把提交指令记录到磁盘的事务日志中以后,及时数据修改还没有应用到磁盘的数据分区,也可以认为事务时持久化的。
2.系统重新启动(正常启动或在发生系统故障之后启动),SQL Server会每个数据库的事务日志,进行回复处理。
3.恢复处理包含两个阶段:重做阶段和撤销阶段。
4.前滚:在重做阶段,对于提交指令已经写入到日志的事务,但数据修改还没有应用到数据分区的事务,数据库引擎会重做这些食物所做的所有修改。
5.回滚:在撤销阶段,对于提交指令没有写入到日志中的事务,数据库引擎会撤销这些事务所做的修改。(这句话需要research,可能是不正确的。因为提交指令没有写入到数据分区,撤销修改是指撤销哪些修改呢???)
(1)SQL Server使用锁来实现事务的隔离。
(2)事务获取锁这种控制资源,用于保护数据资源,防止其他事务对数据进行冲突的或不兼容的访问。
(1)排他锁
a.当试图修改数据时,事务只能为所依赖的数据资源请求排他锁。
b.持有排他锁时间:一旦某个事务得到了排他锁,则这个事务将一直持有排他锁直到事务完成。
c.排他锁和其他任何类型的锁在多事务中不能在同一阶段作用于同一个资源。
如:当前事务获得了某个资源的排他锁,则其他事务不能获得该资源的任何其他类型的锁。其他事务获得了某个资源的任何其他类型的锁,则当前事务不能获得该资源的排他锁。
(2)共享锁
a.当试图读取数据时,事务默认会为所依赖的数据资源请求共享锁。
b.持有共享锁时间:从事务得到共享锁到读操作完成。
c.多个事务可以在同一阶段用共享锁作用于同一数据资源。
d.在读取数据时,可以对如何处理锁定进行控制。后面隔离级别会讲到如何对锁定进行控制。
(1)如果数据正在由一个事务进行修改,则其他事务既不能修改该数据,也不能读取(至少默认不能)该数据,直到第一个事务完成。
(2)如果数据正在由一个事务读取,则其他事务不能修改该数据(至少默认不能)。
RID、KEY(行)、PAGE(页)、对象(例如表)、数据库、EXTENT(区)、分配单元(ALLOCATION_UNIT)、堆(HEAP)、以及B树(B-tree)。
RID: 标识页上的特定行
格式: fileid: pagenumber: rid (1:109:0 )
其中fileid标识包含页的文件, pagenumber标识包含行的页,rid标识页上的特定行。
fileid与sys.databases_files 目录视图中的file_id列相匹配
例子:
在查询视图sys.dm_tran_locks的时候有一行的resource_description列显示RID 是1:109:0 而status列显示wait,
表示第1个数据文件上的第109页上的第0行上的锁资源。
SQL Server可以先获得细粒度的锁(例如行或页),在某些情况下将细粒度锁升级为更粗粒度的锁(例如,表)。
例如单个语句获得至少5000个锁,就会触发锁升级,如果由于锁冲突而导致无法升级锁,则SQL Server每当获取1250个新锁时出发锁升级。
当多个事务都需要对某一资源进行锁定时,默认情况下会发生阻塞。被阻塞的请求会一直等待,直到原来的事务释放相关的锁。锁定超时期限可以限制,这样就可以限制被阻塞的请求在超时之前要等待的时间。
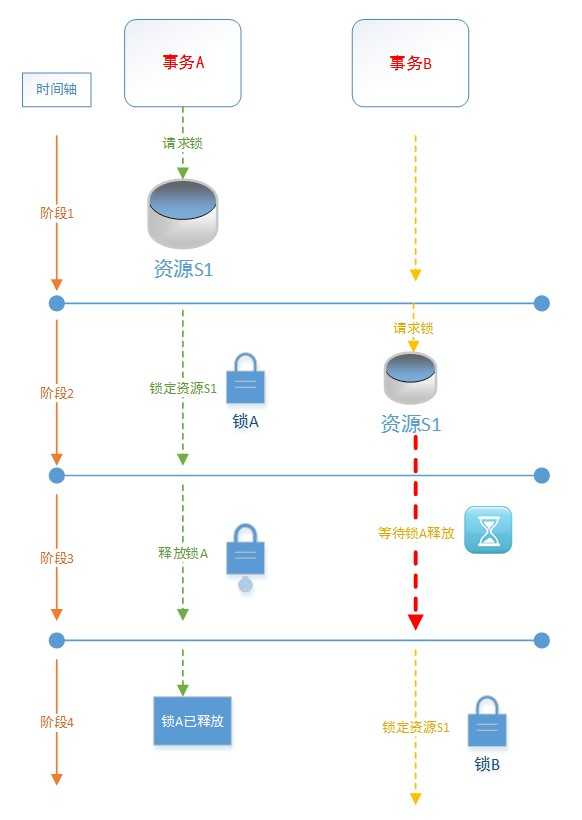
阶段1:事务A请求资源S1,事务不对资源S1进行操作
阶段2:事务A用锁A锁定资源S1,事务B请求对资源S1进行不兼容的锁定(锁B),锁B的请求被阻塞,事务B将进入等待状态
阶段3:事务A正在释放锁A,事务B等待锁A释放,
阶段4:事务A的锁A已释放,事务B用锁B锁定资源S1
2.排除阻塞
例子:
(1)准备工作:
1.准备测试数据
--先创建一张表Product作为测试。id为表的主键,price为product的价格
CREATE TABLE [dbo].[myProduct](
[id] [int] NOT NULL,
[price] [money] NOT NULL
) ON [PRIMARY]
GO
--插入一条数据,id=1,price=10
INSERT INTO [TSQLFundamentals2008].[dbo].[myProduct]([id],[price])VALUES(1,10)
2.模拟阻塞发生的情况
在SQL Server中打开三个查询窗口Connection1、Connection2、Connection3,分别按顺序执行表格中的执行语句。
--Connection1
BEGIN TRAN
UPDATE dbo.myProduct SET price = price + 1 WHERE id=1
--Connection2
SELECT * FROM dbo.myProduct WHERE id=1
--Connection3
SELECT request_session_id AS 会话id ,
resource_type AS 请求锁定的资源类型 ,
resource_description AS 描述 ,
request_mode AS 模式 ,
request_status AS 状态
FROM sys.dm_tran_locks
| 查询窗口 |
服务器进程标识符SPID |
执行语句 |
结果 | 说明 | ||
| Connection1 | 52 |
|
 |
为了更新id=1这一行数据,会话必须先获得一个排他锁。事务处于一直打开状态,没有提交,所以事务一直持有排他锁,直到事务提交并完成。 |
||
| Connection2 | 56 |
|
 |
事务为了读取数据,需要请求一个共享锁,但是这一行已经被其他会话持有的排他锁锁定,而且共享锁和排他锁不是兼容的,所以会话被阻塞,进入等待状态 |
||
| Connection3 | 57 |
|
|
(2)分析阻塞
★ 1.sys.dm_tran_locks 视图
(1)该动态视图可以查询出哪些资源被哪个进程ID锁了
(2)查询出对资源授予或正在等待的锁模式
(3)查询出被锁定资源的类型
上面的查询语句3已经用到了这个视图,可以参考上图中的分析说明。
★ 2.sys.dm_exec_connections 视图
(1)查询出该动态视图可以查询出进程相关的信息
(2)查询出最后一次发生读操作和写操作的时间last_read,last_write
(3)查询出进程执行的最后一个SQL批处理的二进制标记most_recent_sql_handle
| 查询窗口 |
服务器进程标识符SPID |
执行语句 |
结果 | 说明 | |
| Connection3 | 57 |
|
|
★ 4.sys.dm_exec_sessions 视图
(1)会话建立的时间login_time
(2)特定于会话的客户端工作站名称host_name
(3)初始化会话的客户端程序的名称program_name
(4)会话所使用的SQL Server登录名login_name
(5)最近一次会话请求的开始时间last_request_start_time
(6)最近一次会话请求的完成时间last_request_end_time
| 查询窗口 |
服务器进程标识符SPID |
执行语句 |
结果 | 说明 | |
| Connection3 | 57 |
|
|
★ 5.sys.dm_exec_requests 视图
(1)识别出阻塞链涉及到的会话、争用的资源、被阻塞会话等待了多长时间
| 查询窗口 |
服务器进程标识符SPID |
执行语句 |
结果 | 说明 | |
| Connection3 | 57 |
|
|
★ 6.Lock_TIMEOUT 选项
(1)设置会话等待锁释放的超时期限
(2)默认情况下会话不会设置等待锁释放的超时期限
(3)设置会话超时期限为5秒, SET Lock_TIMEOUT 5000
(4)锁定如果超时,不会引发事务回滚
(5)取消会话超时锁定的设置,SET LOCK_TIMEOUT -1
如果超时,将显示以下错误:

★7.KILL <spid> 命令
(1)杀掉会话52,KILL 52
(2)杀掉会话,会引起事务回滚,同时释放排他锁
(1)隔离级别用来做什么
a.隔离级别用于决定如何控制并发用户读写数据的操作
(2)写操作
a.任何对表做出修改的语句
b.使用排他锁
c.不能修改读操作获得的锁和锁的持续时间
(3)读操作:
a.任何检索数据的语句
b.默认使用共享锁
c.使用隔离级别来控制读操作的处理方式
(1)未提交读 (READ UNCOMMITTED)
(2)已提交读(READ COMMITTED)(默认值)
(3)可重复读(REPEATABLE READ)
(4)可序列化(SERIALIZABLE)
(5)快照(SNAPSHOT)
(6)已经提交读快照(READ_COMMITTED_SNAPSHOT)
(1)设置整个会话的隔离级别
SET TRANSACTION ISOLATION LEVEL <isolation name>;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
(2)用表提示设置查询的隔离级别
SELECT ... FROM <table> WITH (<isolation name>);<br>
SELECT * FROM dbo.myProduct WITH (READCOMMITTED);
注意:
1.设置会话选项的隔离级别时,隔离级别中的每个单词之间需要用空格分隔
2.用表提示的隔离级别时,隔离级别中的每个单词之间不需要用空格分隔
3.表提示的隔离级别有同义词,如:NOLOCK->READUNCOMMITTED,HOLDLOCK->REPEATABLEREAD
4.隔离级别的严格性:1.未提交读<2.已提交读<3.可重复读<4.可序列化
5.隔离级别越高,一致性越高,并发性越低
6.基于快照的隔离级别,SQL Server将提交过的行保存到tempdb数据库中,当读操作发现行的当前版本和它们预期的不一致时,可以立即得到行的以前版本,从而不用请求共享锁也能取得预期的一致性。
★ 1.未提交读 (READ UNCOMMITTED)
打开两个查询窗口,Connetion1,connection2
Step1: 执行Connection1的阶段2的SQL 语句,然后执行connection2的SQL语句
Step2: 执行Connection1的阶段3的SQL 语句,执行connection2的SQL语句
Step3: 执行Connection1的阶段4的SQL 语句,执行connection2的SQL语句
| 查询窗口 | 事务 | 执行语句 | ||
| Connetion1 | A |
|
||
| Connection2 | B |
|
两个事务的流程图:
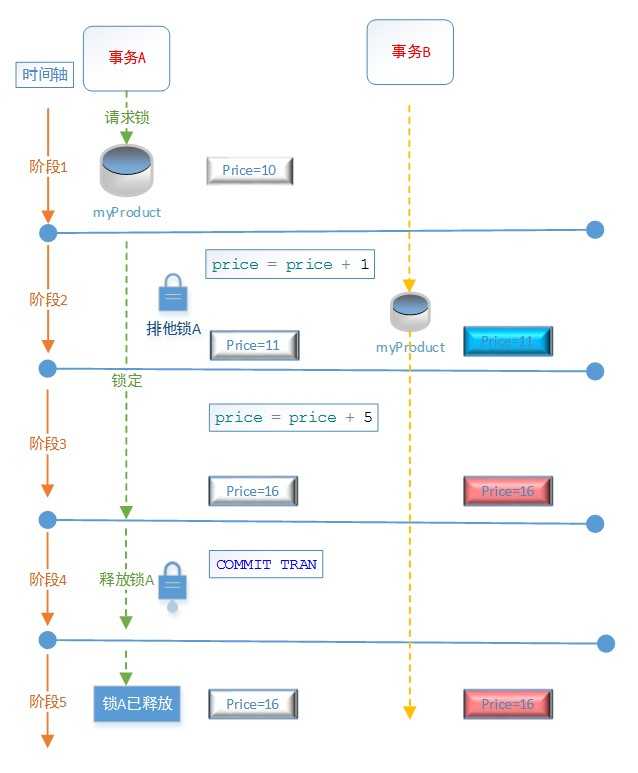
阶段1:Price=10,事务A对myProduct表请求排他锁
阶段2:事务A对myProduct表使用了排他锁,更新price = price + 1,然后事务A查询price的价格: price=11。事务B不请求任何锁,事务B在A更新Price之后进行查询,price=11
阶段3:事务A更新price = price + 5,然后事务A查询price的价格,price = 16。事务B查询price的价格: price=16
阶段4:事务A释放排他锁
阶段5:事务A中查询price的价格:price = 16。事务B查询price的价格: price=16
大家可以看到事务B有两种结果,这就是“未提交读 (READ UNCOMMITTED)”隔离级别的含义:
(1)读操作可以读取未提交的修改(也称为脏读)。
(2)读操作不会妨碍写操作请求排他锁,其他事务正在进行读操作时,写操作可以同时对这些数据进行修改。
(3)事务A进行了多次修改,事务B在不同阶段进行查询时可能会有不同的结果。
★ 2.已提交读(READ COMMITTED)(默认值)
打开两个查询窗口,Connetion1,connection2
Step1: 执行Connection1的SQL 语句
Step2: 执行Connection2的SQL 语句
| 执行语句 | 执行语句 | |||
| Connetion1 | A |
|
||
| Connection2 | B |
|
两个事务的流程图:
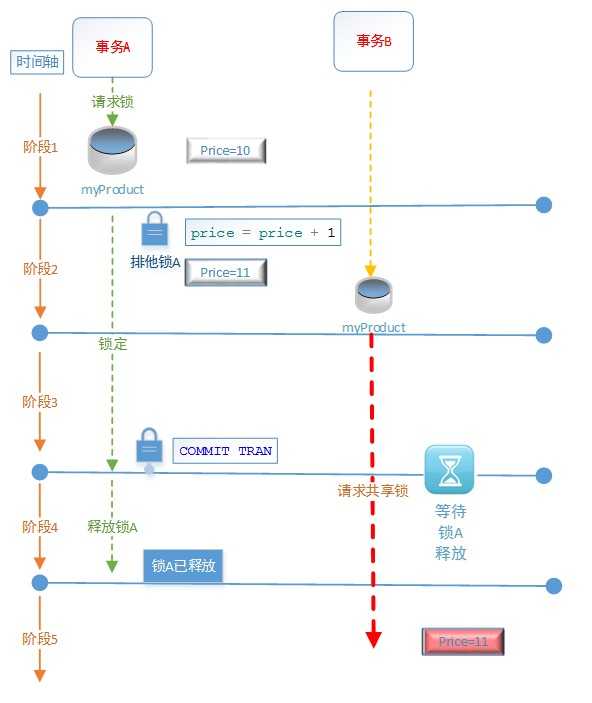
阶段1:Price=10,事务A对myProduct表请求排他锁
阶段2:事务A对myProduct表使用了排他锁,更新price = price + 1,然后事务A查询price的价格: price=11。然后事务B请求共享锁进行读操作,查询price,
由于在当前隔离级别下,事务A的排他锁和事务B的共享锁存在冲突,所以事务B需要等待事务A释放排他锁后才能读取数据。
阶段3:事务A提交事务(COMMIT TRAN)
阶段4:事务A提交完事务后,释放排他锁
阶段5:事务B获得了共享锁,进行读操作,price=11
“已提交读 (READ UNCOMMITTED)”隔离级别的含义:
(1)必须获得共享锁才能进行读操作,其他事务如果对该资源持有排他锁,则共享锁必须等待排他锁释放。
(2)读操作不能读取未提交的修改,读操作读取到的数据是提交过的修改。
(3)读操作不会在事务持续期间内保留共享锁,其他事务可以在两个都操作之间更改数据资源,读操作因而可能每次得到不同的取值。这种现象称为“不可重复读”
★ 3.可重复读(REPEATABLE READ)
打开两个查询窗口,Connetion1,connection2
Step1: 执行Connection1的SQL 语句
Step2: 执行Connection2的SQL 语句
| 执行语句 | 事务 | 执行语句 | ||
| Connetion1 | A |
|
||
| Connection2 | B |
|
两个事务的流程图:
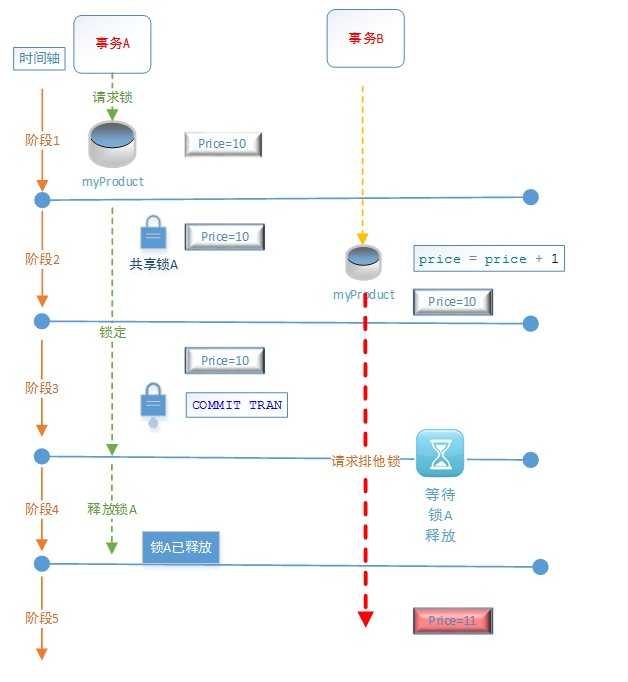
阶段1:Price=10,事务A对myProduct表请求共享锁
阶段2:事务A对myProduct表使用了共享锁,事务A查询price的价格: price=10,事务A一直持有共享锁直到事务A完成为止。然后事务B请求排他锁进行写操作price=price+1,
由于在当前隔离级别下,事务A的共享锁和事务B请求的排他锁存在冲突,所以事务B需要等待事务A释放共享锁后才能修改数据。
阶段3:事务A查询price, price=10, 说明事务B的更新操作被阻塞了,更新操作没有被执行。然后事务A提交事务(COMMIT TRAN)
阶段4:事务A提交完事务后,释放共享锁
阶段5:事务B获得了排他锁,进行写操作,price=11
“可重复读 (REPEATABLE READ)”隔离级别的含义:
(1)必须获得共享锁才能进行读操作,获得的共享锁将一直保持直到事务完成之止。
(2)在获得共享锁的事务完成之前,没有其他事务能够获得排他锁修改这一数据资源,这样可以保证实现可重复的读取。
(3)两个事务在第一次读操作之后都将保留它们获得的共享锁,所以任何一个事务都不能获得为了更新数据而需要的排他锁,这种情况将会导致死锁(deadlock),不过却避免了更新冲突。
★ 4.可序列化(SERIALIZABLE)
打开两个查询窗口,Connetion1,connection2
Step1: 执行Connection1的SQL 语句
Step2: 执行Connection2的SQL 语句
| 执行语句 | 事务 |
|
||
| Connetion1 | A |
|
||
| Connection2 | B |
|
两个事务的流程图:
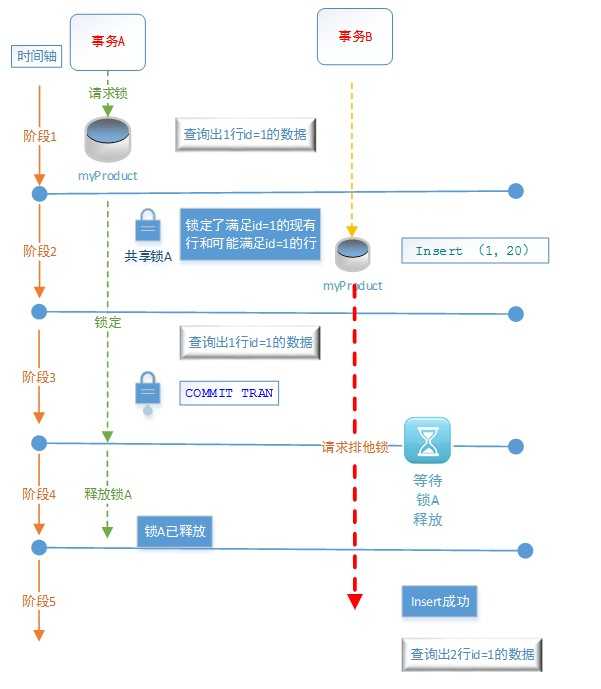
阶段1:Price=10,事务A对myProduct表请求共享锁
阶段2:事务A对myProduct表使用了共享锁,事务A查询id=1的price的价格:1行记录,price=10,事务A一直持有共享锁直到事务A完成为止。然后事务B请求排他锁进行插入操作id=1,price=20,
由于在当前隔离级别下,事务B试图增加能够满足事务A的读操作的查询搜索条件的新行,所以事务A的共享锁和事务B请求的排他锁存在冲突,事务B需要等待事务A释放共享锁后才能插入数据。
阶段3:事务A查询出id=1的数据只有1行,说明事务B的插入操作被阻塞了,插入操作没有被执行。然后事务A提交事务(COMMIT TRAN)
阶段4:事务A提交完事务后,释放共享锁
阶段5:事务B获得了排他锁,进行插入操作,插入成功,查询出id=1的数据有两条
“可序列化(SERIALIZABLE)”隔离级别的含义:
(1)必须获得共享锁才能进行读操作,获得的共享锁将一直保持直到事务完成之止。
(2)在获得共享锁的事务完成之前,没有其他事务能够获得排他锁修改这一数据资源,且当其他事务增加能够满足当前事务的读操作的查询搜索条件的新行时,其他事务将会被阻塞,直到当前事务完成然后释放共享锁,其他事务才能获得排他锁进行插入操作。
(3)事务中的读操作在任何情况下读取到的数据是一致的,不会出现幻影行。
(4)范围锁:读操作锁定满足查询搜索条件的整个范围的锁
| 隔离级别 | 是否读取未提交的行 | 是否不可重复读 | 是否丢失更新 | 是否幻读 | 共享锁持续时间 | 是否持有范围锁 |
| 未提交读 READ UNCOMMITTED | Y | Y | Y | Y | 当前语句 | N |
| 已提交读 READ COMMITTED | Y | Y | Y | Y | 当前语句 | N |
| 可重复读REPEATABLE READ | N | N | N | Y | 事务开始到事务完成 | N |
| 可序列化SERIALZABLE | N | N | N | N | 事务开始到事务完成 | Y |
死锁是指一种进程之间互相永久阻塞的状态,可能涉及两个或更多的进程。
打开两个查询窗口,Connetion1,connection2
Step1: 执行Connection1的SQL 语句
Step2: 执行Connection2的SQL 语句
| 执行语句 | 事务 | 执行语句 | ||
| Connetion1 | A |
|
||
| Connection2 | B |
|
两个事务的流程图:
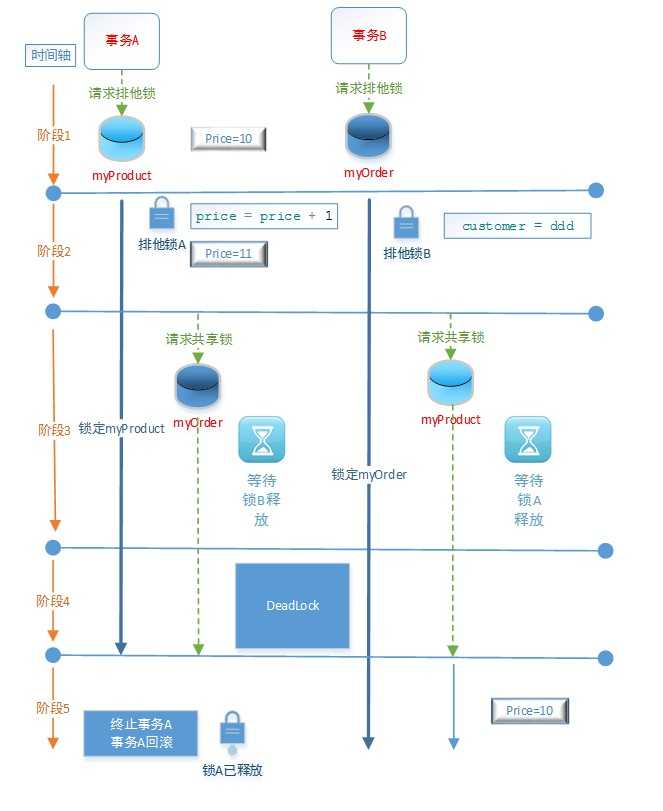
阶段1:Price=10,事务A对myProduct表请求排他锁。Customer = aaa,事务B对myOrder请求排他锁
阶段2:事务A对myProduct表使用了排他锁,更新price = price + 1。然后事务B对myOrder表使用了排他锁,更新customer=ddd。
阶段3:事务A查询myOrder表,对myOrder表请求共享锁,因为事务A的请求的共享锁与事务B的排他锁冲突,所以事务A被阻塞。然后事务B查询myProduct表,对myProduct表请求共享锁,因为事务B的请求的共享锁与事务A的排他锁冲突,所以事务B被阻塞。
阶段4:事务A等待事务B的排他锁释放,事务B等待事务A的排他锁释放,导致死锁。事务A和事务B都被阻塞了。
阶段5:SQL Server在几秒之内检测到死锁,会选择一个事务作为死锁的牺牲品,终止这个事务,并回滚这个事务所做的操作。在这个例子中,事务A被终止,提示信息:事务(进程 ID 53)与另一个进程被死锁在 锁 资源上,并且已被选作死锁牺牲品。请重新运行该事务。
“死锁 (Dead Lock)”的一些注意事项:
(1)如果两个事务没有设置死锁优先级,且两个事务进行的工作量也差不多一样时,任何一个事务都由可能被终止。
(2)解除死锁要付出一定的系统开销,因为这个过程会涉及撤销已经执行过的处理。
(3)事务处理的时间时间越长,持有锁的时间就越长,死锁的可能性也就越大,应该尽可能保持事务简短,把逻辑上可以不属于同一个工作单元的操作移到事务以外。
(4)上面的例子中,事务A和事务B以相反顺序访问资源,所以发生了死锁。如果两个事务按同样的顺序来访问资源,则不会发生这种类型的死锁。在不改变程序的逻辑情况下,可以通过交换顺序来解决死锁的问题。
标签:
原文地址:http://www.cnblogs.com/XACOOL/p/5642298.html



