标签:
项目:开发一个简单的BBS论坛
需求:
知识必备:
1 # -*- coding:utf-8 -*- 2 from django.db import models 3 from django.contrib.auth.models import User 4 from django.core.exceptions import ValidationError 5 import datetime 6 7 class Article(models.Model): 8 ‘‘‘ 文章帖子 ‘‘‘ 9 title = models.CharField(u‘标题‘, max_length=255) 10 brief = models.CharField(u‘简介‘, max_length=255, blank=True, null=True) 11 category = models.ForeignKey(‘Category‘, verbose_name=u‘板块‘) 12 content = models.TextField(u‘内容‘) 13 author = models.ForeignKey(‘UserProfile‘, verbose_name=u‘作者‘) 14 # auto_now_add 创建生成的时间, auto_now 修改时的时间 15 pub_date = models.DateTimeField(u‘发布时间‘, blank=True, null=True) 16 last_modify = models.DateTimeField(u‘修改时间‘, auto_now=True) 17 priority = models.IntegerField(u‘优先级‘, default=1000) 18 status_choices = ( 19 (‘draft‘, u‘草稿‘), 20 (‘published‘, u‘发布‘), 21 (‘hidden‘, u‘隐藏‘), 22 ) 23 status = models.CharField(u‘状态‘, max_length=64, choices=status_choices, 24 default=‘published‘) 25 # upload_to=‘uploads‘ 设置存放图片路径,默认存在跟目录下 26 head_img = models.ImageField(u‘图片‘, upload_to=‘uploads‘) 27 28 def clean(self): 29 if self.status == ‘draft‘ and self.pub_date is not None: 30 raise ValidationError(u‘草稿是没有发布日期的!‘) 31 # Set the pub_date for published items if it hasn‘t been set already. 32 if self.status == ‘published‘ and self.pub_date is None: 33 self.pub_date = datetime.date.today() 34 35 def __str__(self): 36 return self.title 37 38 class Meta: 39 verbose_name = u‘文章‘ 40 verbose_name_plural = u‘文章‘ 41 42 class Comment(models.Model): 43 ‘‘‘ 评论、点赞 ‘‘‘ 44 article = models.ForeignKey(‘Article‘, verbose_name=‘所属文章‘) 45 parent_comment = models.ForeignKey(‘self‘, related_name=‘my_children‘, 46 blank=True, null=True, verbose_name=u‘父评论‘) 47 comment_choices = ((1, u‘评论‘), (2, u‘点赞‘),) 48 comment_type = models.IntegerField(u‘类型‘, choices=comment_choices, 49 default=1) 50 user = models.ForeignKey(‘UserProfile‘, verbose_name=u‘评论者‘) 51 content = models.TextField(u‘内容‘, blank=True, null=True) 52 date = models.DateTimeField(u‘时间‘, auto_now_add=True) 53 54 def clean(self): 55 if self.comment_type == 1 and len(self.content) == 0: 56 raise ValidationError(u‘评论的内容不能为空!‘) 57 58 def __str__(self): 59 return self.content 60 61 62 class Meta: 63 verbose_name = u‘评论‘ 64 verbose_name_plural = u‘评论‘ 65 66 class Category(models.Model): 67 ‘‘‘ 板块 ‘‘‘ 68 name = models.CharField(u‘板块名字‘, max_length=64, unique=True) 69 brief = models.CharField(u‘简介‘, max_length=255, blank=True, null=True) 70 set_as_top_menu = models.BooleanField(u‘顶级菜单‘, default=False) 71 position_index = models.SmallIntegerField(u‘位置索引‘) 72 admins = models.ManyToManyField(‘UserProfile‘, blank=True, 73 verbose_name=u‘版主‘) 74 75 def __str__(self): 76 return self.name 77 78 class Meta: 79 verbose_name = u‘板块‘ 80 verbose_name_plural = u‘板块‘ 81 82 class UserProfile(models.Model): 83 ‘‘‘ 用户 ‘‘‘ 84 user = models.OneToOneField(User, verbose_name=u‘用户‘) 85 name = models.CharField(u‘昵称‘, max_length=32) 86 signature = models.CharField(u‘签名‘, max_length=255, blank=True, null=True) 87 head_img = models.ImageField(u‘头像‘,height_field=150, width_field=150, 88 blank=True, null=True) 89 90 91 def __str__(self): 92 return self.name 93 94 class Meta: 95 verbose_name = u‘用户权限‘ 96 verbose_name_plural = u‘用户权限‘
CSRF(Cross Site Request Forgery, 跨站域请求伪造)是一种网络的攻击方式,它在 2007 年曾被列为互联网 20 大安全隐患之一。其他安全隐患,比如 SQL 脚本注入,跨站域脚本攻击等在近年来已经逐渐为众人熟知,很多网站也都针对他们进行了防御。然而,对于大多数人来说,CSRF 却依然是一个陌生的概念。即便是大名鼎鼎的 Gmail, 在 2007 年底也存在着 CSRF 漏洞,从而被黑客攻击而使 Gmail 的用户造成巨大的损失。
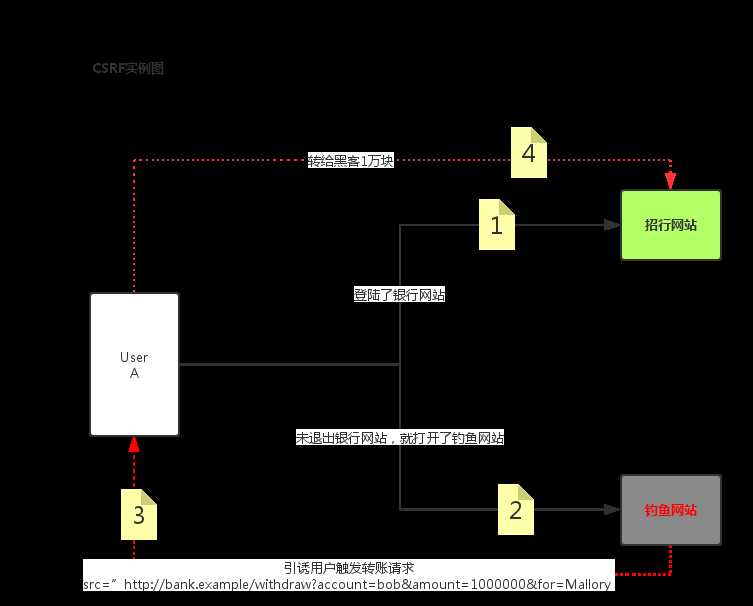
CSRF 攻击可以在受害者毫不知情的情况下以受害者名义伪造请求发送给受攻击站点,从而在并未授权的情况下执行在权限保护之下的操作。比如说,受害者 Bob 在银行有一笔存款,通过对银行的网站发送请求 http://bank.example/withdraw?account=bob&amount=1000000&for=bob2 可以使 Bob 把 1000000 的存款转到 bob2 的账号下。通常情况下,该请求发送到网站后,服务器会先验证该请求是否来自一个合法的 session,并且该 session 的用户 Bob 已经成功登陆。黑客 Mallory 自己在该银行也有账户,他知道上文中的 URL 可以把钱进行转帐操作。Mallory 可以自己发送一个请求给银行:http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory。但是这个请求来自 Mallory 而非 Bob,他不能通过安全认证,因此该请求不会起作用。这时,Mallory 想到使用 CSRF 的攻击方式,他先自己做一个网站,在网站中放入如下代码: src=”http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory ”,并且通过广告等诱使 Bob 来访问他的网站。当 Bob 访问该网站时,上述 url 就会从 Bob 的浏览器发向银行,而这个请求会附带 Bob 浏览器中的 cookie 一起发向银行服务器。大多数情况下,该请求会失败,因为他要求 Bob 的认证信息。但是,如果 Bob 当时恰巧刚访问他的银行后不久,他的浏览器与银行网站之间的 session 尚未过期,浏览器的 cookie 之中含有 Bob 的认证信息。这时,悲剧发生了,这个 url 请求就会得到响应,钱将从 Bob 的账号转移到 Mallory 的账号,而 Bob 当时毫不知情。等以后 Bob 发现账户钱少了,即使他去银行查询日志,他也只能发现确实有一个来自于他本人的合法请求转移了资金,没有任何被攻击的痕迹。而 Mallory 则可以拿到钱后逍遥法外。
在讨论如何抵御 CSRF 之前,先要明确 CSRF 攻击的对象,也就是要保护的对象。从以上的例子可知,CSRF 攻击是黑客借助受害者的 cookie 骗取服务器的信任,但是黑客并不能拿到 cookie,也看不到 cookie 的内容。另外,对于服务器返回的结果,由于浏览器同源策略的限制,黑客也无法进行解析。因此,黑客无法从返回的结果中得到任何东西,他所能做的就是给服务器发送请求,以执行请求中所描述的命令,在服务器端直接改变数据的值,而非窃取服务器中的数据。所以,我们要保护的对象是那些可以直接产生数据改变的服务,而对于读取数据的服务,则不需要进行 CSRF 的保护。比如银行系统中转账的请求会直接改变账户的金额,会遭到 CSRF 攻击,需要保护。而查询余额是对金额的读取操作,不会改变数据,CSRF 攻击无法解析服务器返回的结果,无需保护。
CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于 cookie 中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的 cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有 token 或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。
token 可以在用户登陆后产生并放于 session 之中,然后在每次请求时把 token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。 而对于 POST 请求来说,要在 form 的最后加上 <input type=”hidden” name=”csrftoken” value=”tokenvalue”/>,这样就把 token 以参数的形式加入请求了。但是,在一个网站中,可以接受请求的地方非常多,要对于每一个请求都加上 token 是很麻烦的,并且很容易漏掉,通常使用的方法就是在每次页面加载时,使用 javascript 遍历整个 dom 树,对于 dom 中所有的 a 和 form 标签后加入 token。这样可以解决大部分的请求,但是对于在页面加载之后动态生成的 html 代码,这种方法就没有作用,还需要程序员在编码时手动添加 token。
1 // using jQuery 2 function getCookie(name) { 3 var cookieValue = null; 4 if (document.cookie && document.cookie !== ‘‘) { 5 var cookies = document.cookie.split(‘;‘); 6 for (var i = 0; i < cookies.length; i++) { 7 var cookie = jQuery.trim(cookies[i]); 8 // Does this cookie string begin with the name we want? 9 if (cookie.substring(0, name.length + 1) === (name + ‘=‘)) { 10 cookieValue = decodeURIComponent(cookie.substring(name.length + 1)); 11 break; 12 } 13 } 14 } 15 return cookieValue; 16} 17 18 19 function csrfSafeMethod(method) { 20 // these HTTP methods do not require CSRF protection 21 return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method)); 22} 23 var csrftoken = getCookie(‘csrftoken‘); 24 $.ajaxSetup({ 25 beforeSend: function(xhr, settings) { 26 if (!csrfSafeMethod(settings.type) && !this.crossDomain) { 27 xhr.setRequestHeader("X-CSRFToken", csrftoken); 28 } 29 } 30 }); 31// end ajax
1 <form enctype="multipart/form-data" action="{% url ‘new_article‘ %}" method="post">{% csrf_token %} 2 3 上传标题图片:<input type="file" name="head_img" > 4 5 <button type="submit" class="btn btn-success pull-right">提交</button> 6 7 </form>
1 数据库里评论之前的关系大概如下 2 data = [ 3 (‘a‘,None), 4 (‘b‘, ‘a‘), 5 (‘c‘, None), 6 (‘d‘, ‘a‘), 7 (‘e‘, ‘a‘), 8 (‘g‘, ‘b‘), 9 (‘h‘, ‘g‘), 10 (‘j‘, None), 11 (‘f‘, ‘j‘), 12 ] 13 14 15 ‘‘‘ 16 完整的层级关系如下: 17 a -> b -> g ->h 18 a -> d 19 a -> e 20 21 ‘‘‘ 22 23 #转成字典后的关系如下 24 { 25 ‘a‘:{ 26 ‘b‘:{ 27 ‘g‘:{ 28 ‘h‘:{} 29 } 30 }, 31 ‘d‘:{}, 32 ‘e‘:{} 33 }, 34 ‘j‘:{ 35 ‘f‘:{} 36 } 37 }
接下来其实直接用递归的方法去迭代一遍字典就行啦。
1 #!/usr/bin/env python3 2 # -*- coding:utf-8 -*- 3 # Version:Python3.5.0 4 5 from django import template 6 from django.utils.html import format_html 7 8 register = template.Library() 9 10 @register.filter 11 def truncate_url(img_obj): 12 # img_obj是一个图片对象,img_obj.name或者img_obj.url都是获取图片路径 13 # split(‘/‘, maxsplit=1)[-1] 分割一次,去最后的值 14 # print(img_obj.name,img_obj.url) # uploads/1.jpg 15 return img_obj.name.split(‘/‘, maxsplit=1)[-1] 16 17 @register.simple_tag 18 def filter_comment(article_obj): 19 ‘‘‘ 过滤点赞、评论‘‘‘ 20 # comment_set.select.related() 分组 21 query_set = article_obj.comment_set.select_related() 22 comments = { 23 ‘comment_count‘: query_set.filter(comment_type=1).count(), 24 ‘thumb_count‘: query_set.filter(comment_type=2).count(), 25 } 26 print(comments) 27 return comments
标签:
原文地址:http://www.cnblogs.com/suke99/p/5645816.html