标签:
官网:http://lucene.apache.org/solr/
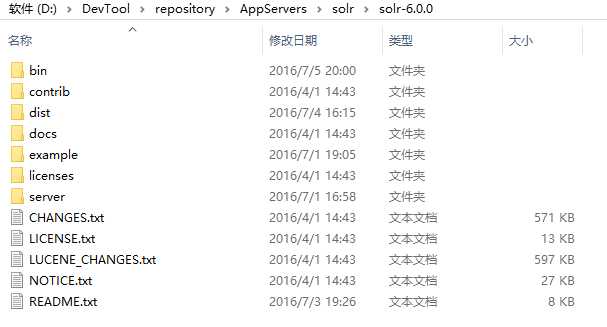
在path路径下将 bin文件夹对应的目录加入,然后输入 solr start(或者 solr start -p port,指定端口启动)。在浏览器中访问如下:
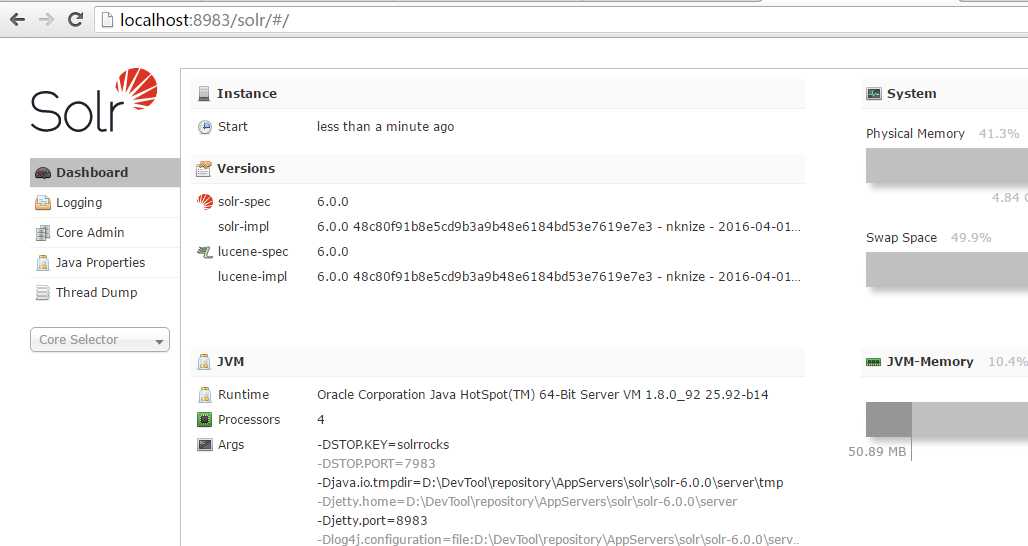
当然,还可以启动其他样例的服务,在example目录下有一个READEME.txt,如果感兴趣请看一下。命令格式如下:
Solr example ------------ This directory contains Solr examples. Each example is contained in a separate directory. To run a specific example, do: bin/solr -e <EXAMPLE> where <EXAMPLE> is one of: cloud : SolrCloud example dih : Data Import Handler (rdbms, mail, rss, tika) schemaless : Schema-less example (schema is inferred from data during indexing) techproducts : Kitchen sink example providing comprehensive examples of Solr features
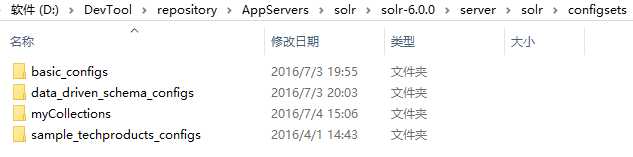
在server/solr目录下,有一个README.txt的文件,其中说明了如何建立solr core。最简单的建立是直接复制solr中为我们提供好的例子,打开server/solr/configsets目录会发现里面已经有三个例子,因为我们是要从数据库导入数据,所以复制 “data_driven_schema_configs” 这个例子并改名为 “myCollections”。
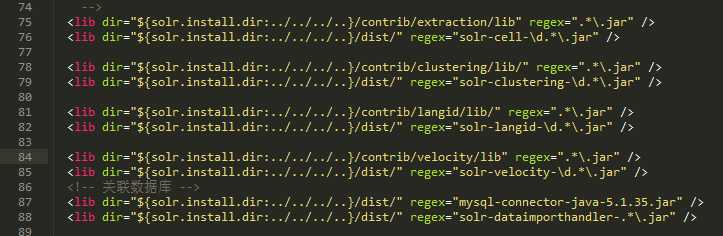
为了导入数据和链接mysql,我们还需要导入两个重要的jar包。由于mysql的jar包并没有在项目中,我是复制了一份放到了dist目录下面了。另外两个需要的jar包就是dist目录下带有“dataimport”标识的jar包。
然后打开myCollections/conf/solrconfig.xml,引用上面提到的jar包,如下。
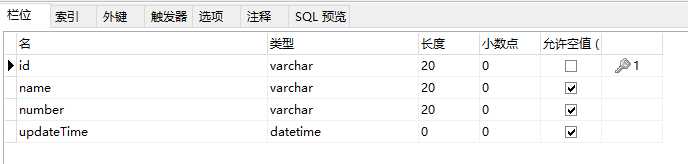
建立好之后,随便写入一点儿数据。
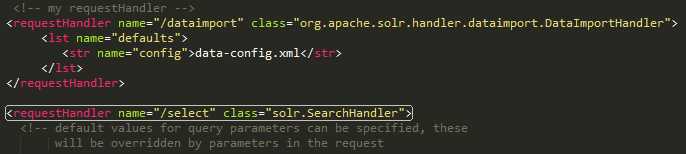
继续修改myCollections/conf/solrconfig.xml,搜索 <requestHandler name="/select" class="solr.SearchHandler"> ,然后在该行之上添加如下代码。
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
在myCollections/conf目录下新建data-config.xml, 内容如下。
<?xml version="1.0" encoding="UTF-8"?> <dataConfig> <dataSource name="source1" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/solrdata" user="root" password="123456" batchSize="-1" /> <document> <entity name="goods" pk="id" dataSource="source1" query="select * from goods" deltaImportQuery="select * from goods where id=‘${dih.delta.id}‘" deltaQuery="select id from goods where updateTime> ‘${dataimporter.last_index_time}‘"> <field column="id" name="id"/> <field column="name" name="name"/> <field column="number" name="number"/> <field column="updateTime" name="updateTime"/> </entity> </document> </dataConfig>
说明:
dataSource是数据库数据源。Entity就是一张表对应的实体,pk是主键,query是查询语句。Field对应一个字段,column是数据库里的column名,后面的name属性对应着Solr的Filed的名字。其中solrdata是数据库名,goods是表名。
其中deltaQuery是增量索引,原理是从数据库中根据deltaQuery指定的SQL语句查询出所有需要增量导入的数据的ID号。然后根据deltaImportQuery指定的SQL语句返回所有这些ID的数据,即为这次增量导入所要处理的数据。核心思想是:通过内置变量“${dih.delta.id}”和 “${dataimporter.last_index_time}”来记录本次要索引的id和最近一次索引的时间。
搜索 <field name= ,添加关联数据库表Column的信息。

注意:默认的 filed 不要删除哦!
(1).点击Core Admin,配置我们建立的solr Core的信息,如下所示。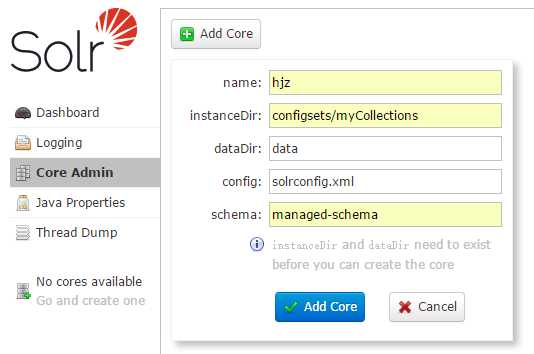
(2).点击 Add Core,如下所示。
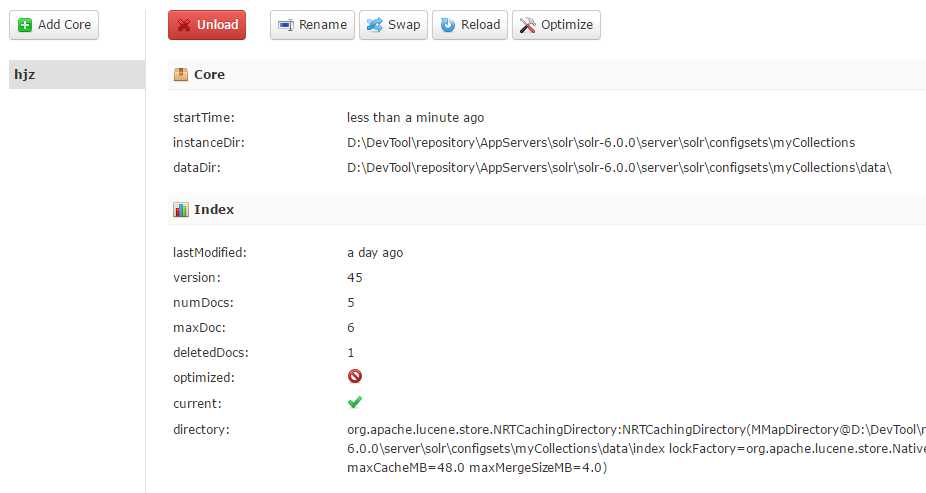
(3).测试索引是否成功
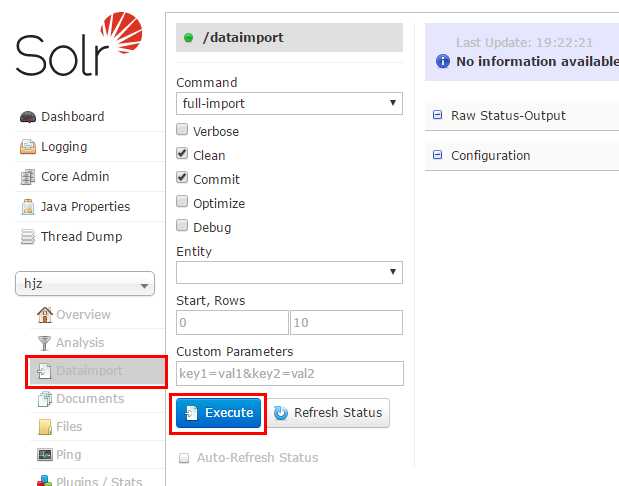
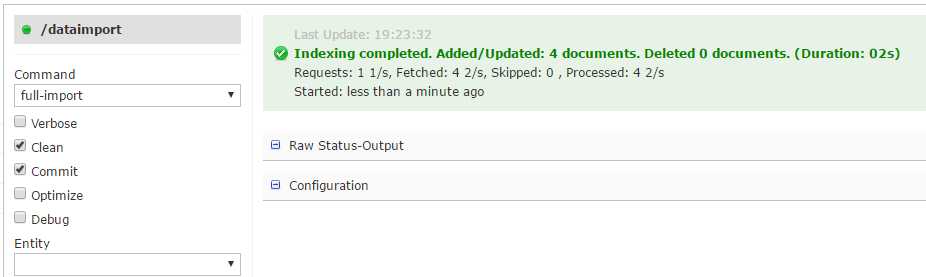
索引成功
(4).监测查询成功
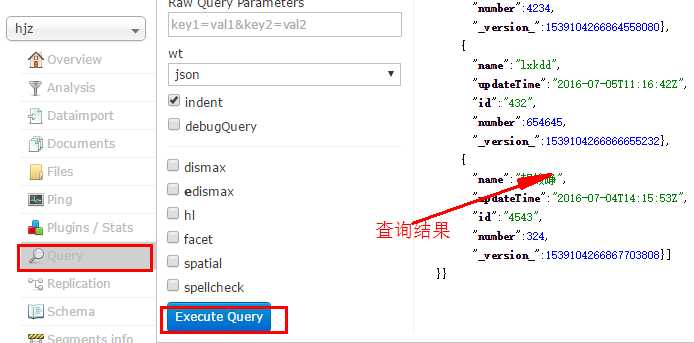
查询成功
简单建立一个java项目,依赖上dist目录下的solr-solrj-6.0.0.jar。
测试代码如下。

import java.lang.reflect.Method; import java.sql.Timestamp; import org.apache.solr.client.solrj.SolrQuery; import org.apache.solr.client.solrj.impl.HttpSolrServer; import org.apache.solr.client.solrj.response.QueryResponse; import org.apache.solr.common.SolrInputDocument; import com.entity.Good; @SuppressWarnings("deprecation") public class Solr { private static HttpSolrServer solrServer; static { //注意请求地址格式:浏览器中的地址有 ‘#’,需要把‘#’去掉! solrServer = new HttpSolrServer("http://localhost:8983/solr/hjz"); solrServer.setConnectionTimeout(5000); } /** * 添加单个文档 。 * * @param article 文章对象 * @param articleAddon 文章正文对象 */ public static void insert(Good good) { SolrInputDocument doc = new SolrInputDocument(); doc.addField("id", good.getId()); doc.addField("name", good.getName()); doc.addField("number", good.getNumber()); doc.addField("updateTime", good.getUpdateTime()); try { solrServer.add(doc); solrServer.commit(); } catch (Exception e) { e.printStackTrace(); } } /** * 根据文档id删除文档 。 */ public static void deleteById(String id) { try { solrServer.deleteById(id+""); solrServer.commit(); } catch (Exception e) { e.printStackTrace(); } } /** * 删除所有文档,为安全起见,使用时再解注函数体 。 */ public static void deleteAll() { try { solrServer.deleteByQuery("*:*"); solrServer.commit(); } catch (Exception e) { e.printStackTrace(); } } /** * 更新文档,其实也是通过insert操作来完成 。 * * @param article 文章对象 * @param articleAddon 文章内容对象,如果不更新正文,可以为null。 */ public static void update(Good good) { insert(good); } /** * 根据文档id查询单个文档 。 * @return */ public static <T> T getById(int id, Class<T> clazz) { SolrQuery query = new SolrQuery(); query.setQuery("id:" + id); try { QueryResponse rsp = solrServer.query(query); return rsp.getBeans(clazz).get(0); } catch (Exception e) { e.printStackTrace(); } return null; } /** * @param obj 对象索引 * @param idName 主键名称 */ public static void deleteByObject(Object obj, String idName){ try { Class<?> clazz = obj.getClass(); //将idName的首字母变成大写 if(Character.isLowerCase(idName.charAt(0))) idName = Character.toUpperCase(idName.charAt(0)) + idName.substring(1); Method method = clazz.getMethod("get"+idName); String idValue = (String) method.invoke(obj); deleteById(idValue); } catch (Exception e) { e.printStackTrace(); } } public static void main(String[] args){ Good good = new Good("123", 9999, "hjzgg5211314", new Timestamp(System.currentTimeMillis())); //Solr.update(good); //System.out.println(Solr.getById(123, Good.class)); deleteByObject(good, "id"); } }
对应的实体类。
import java.sql.Timestamp; import org.apache.solr.client.solrj.beans.Field; public class Good{ @Field("id") private String id; @Field("number") private int number; @Field("name") private String name; @Field("updateTime") private Timestamp updateTime; @Override public String toString() { return "Good [id=" + id + ", number=" + number + ", name=" + name + ", updateTime=" + updateTime + "]"; } public Good(){} public Good(String id, int number, String name, Timestamp updateTime) { super(); this.id = id; this.number = number; this.name = name; this.updateTime = updateTime; } public String getId() { return id; } public void setId(String id) { this.id = id; } public int getNumber() { return number; } public void setNumber(int number) { this.number = number; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Timestamp getUpdateTime() { return updateTime; } public void setUpdateTime(Timestamp updateTime) { this.updateTime = updateTime; } }
每测试一次,可以在浏览器中通过query方式查看测试结果是否正确。
Solr参考指南 可以下载
标签:
原文地址:http://www.cnblogs.com/hujunzheng/p/5647896.html
