标签:
Java 散列表 hash table
@author ixenos
hash table, HashTable, HashMap, HashSet
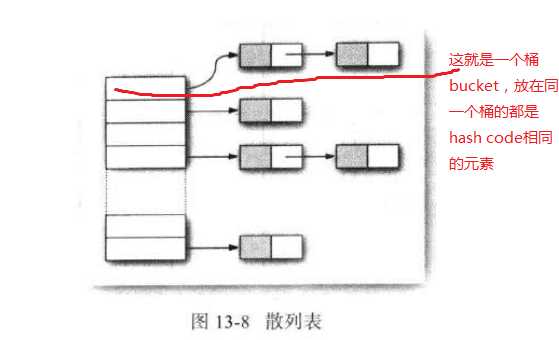 //图片来自《Core Java》
//图片来自《Core Java》
public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>, Cloneable, Serializable
此类实现一个哈希表,该哈希表将键映射到相应的值。任何非 null 对象都可以用作键或值。为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。Hashtable 的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable{ private transient HashMap<E,Object> map; ... public HashSet() { map = new HashMap<>(); } ... }
//HashSet的contains方法源码(借助HashMap的方法) public boolean contains(Object o) { return map.containsKey(o); } //来自HashMap的源码 final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; } public boolean containsKey(Object key) { //被HashSet的contains方法调用 return getNode(hash(key), key) != null; }
标签:
原文地址:http://www.cnblogs.com/ixenos/p/5654343.html