标签:
之前用nodejs的cheerio来做,不过nodejs的异步回掉太恶心了,受不了。
后来发现了php的htmlpagedom库,类似jquery的选择器语法,而且支持中文。
安装 composer install wa72/htmlpagedom
1、读取一个简单的网页,如:
require ‘vendor/autoload.php‘; use \Wa72\HtmlPageDom\HtmlPageCrawler; $url = "http://news.cnblogs.com/"; $dom = HtmlPageCrawler::create(file_get_contents($url)); print $dom->text(); //输出内容
2、如何分析,使用jquery选择器语法,可以参考
如提取博客园新闻首页第一页的所有链接,结构如下
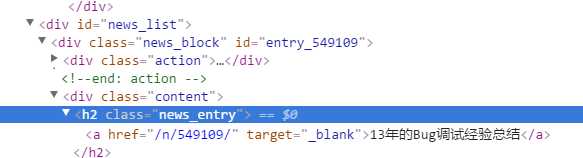
$news_list = $dom->filter("#news_list"); $news_entry =$news_list->filter(".news_entry"); $urls = []; $i = 0; $url_cnt = $news_entry->count(); //print $url_cnt; 30条,在浏览器里查找“发布于”是30,证明是正确的 while ($i<$url_cnt){ $urls[] = $news_entry->eq($i)->filter(‘a‘)->eq(0)->attr("href"); ++$i; }
可能有人疑问,为啥不用foreach
因为$news_entry->children() 返回的是DOMElement,而不是HtmlPageCrawler,不能使用filter,还要继续用HtmlPageCrawler::create()。
3、提取新闻正文
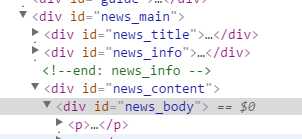
$content = HtmlPageCrawler::create(file_get_contents($url.$urls[0]));
print $content->filter("#news_body")->text();
4、说明
有些网站的内容可能不是utf8的这时就要用iconv转码了
可以写个函数封装一下,$base根url,因为很多情况下链接是相对的。
function httpGet($url, $base = null) { if (!$base) { $url .= $base; } $html = file_get_contents($url); $encode = mb_detect_encoding($html, "gbk,utf-8"); if (stripos($encode, "utf") !== false) { return HtmlPageCrawler::create($html); } else { $utf_html = iconv("gbk", "utf-8", $html); return HtmlPageCrawler::create($utf_html); } }
如果用html()函数获取html则输出的都是html实体编码,可以用html_entity_decode
另外可以用strip_tags 来去除html里的某些标签。
id是唯一的,而class和标签都不是唯一的,所以获取class和标签,就算只有一个也要用eq(0)还获取
jquery有个has函数判断是否存在某个标签,而HtmlPageCrawler缺少这个,于是手工添加了一个。
在HtmlPageCrawler.php的hasClass函数下面,添加如下代码
public function has($name) { foreach ($this->children() as $node){ if ($node instanceof \DOMElement) { $tagName = $node->tagName; if (stripos($tagName, $name) !== false) { return true; } } } return false; }
标签:
原文地址:http://www.cnblogs.com/xdao/p/php_spider.html