标签:
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术,。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。
TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。
如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m + k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。
实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
TF公式:
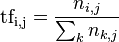
以上式子中  是该词在文件
是该词在文件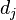 中的出现次数,而分母则是在文件中所有词的出现次数之和。
中的出现次数,而分母则是在文件中所有词的出现次数之和。
IDF公式:
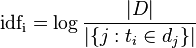
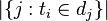 :包含词语
:包含词语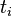 的文件数目(即
的文件数目(即 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用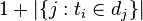
idf = log(语料中文件的总数 / 包含词语t的文件数目)
然后 tfidf 就是tf*idf
标签:
原文地址:http://www.cnblogs.com/xueyuwyz/p/5660868.html