标签:
1Android是基于Linux的一个操作系统,它可以分为五层,下面是它的层次架构图,可以记一下,因为后面应该会总结到SystemServer这些Application Framework层的东西

Android的五层架构从上到下依次是:应用层,应用框架层,库层,运行时层,Linux内核层。
而在Linux中,它的启动可以归为一下几个流程:
Boot Loader——>初始化内核——>。。。。。。
当初始化内核之后,就会启动一个相当重要的祖先进程,也就是init进程,在Linux中所有的进程都是由init进程直接或间接fork出来的。
而对于Android来说,前面的流程都是一样的,而当init进程创建之后,会fork出一个Zygote进程,这个进程是所有Java进程的父进程。我们知道,Linux是基于C的,而Android是基于Java的(当然底层也是C)。所以这里就会fork出一个Zygote Java进程用来fork出其他的进程。【断点1】
总结到了这里就提一下之后会谈到的几个非常重要的对象以及一个很重要的概念。
- ActivityManagerServices(AMS):它是一个服务端对象,负责所有的Activity的生命周期,ActivityThread会通过Binder与之交互,而AMS与Zygote之间进行交互则是通过Socket通信(IPC通信在之后会总结到)
- ActivityThread:它也就是我们俗称的UI线程/主线程,它里面存在一个main()方法,这也是APP的真正入口,当APP启动时,就会启动ActivityThread中的main方法,它会初始化一些对象,然后开启消息循环队列(之后总结),之后就会Looper.loop死循环,如果有消息就执行,没有就等着,也就是事件驱动模型(edt)的原理。
- ApplicationThread:它实现了IBinder接口,是Activity整个框架中客户端和服务端AMS之间通信的接口,同时也是ActivityThread的内部类。这样就有效的把ActivityThread和AMS绑定在一起了。
- Instrumentation:这个东西我把它理解为ActivityThread的一个工具类,也算是一个劳动者吧,对于生命周期的所有操作例如onCreate最终都是直接由它来执行的。
Android系统中的客户端和服务器的概念
在Android系统中其实也存在着服务器和客户端的概念,服务器端指的就是所有App共用的系统服务,比如上面的AMS,PackageManagerService等等,这些系统服务是被所有的App共用的,当某个App想要实现某个操作的时候,就会通知这些系统服务。
继续断点1
当Zygote被初始化的时候,会fork出System Server进程,这个进程在整个的Android进程中是非常重要的一个,地位和Zygote等同,它是属于Application Framework层的,Android中的所有服务,例如AMS, WindowsManager, PackageManagerService等等都是由这个SystemServer fork出来的。所以它的地位可见一斑。
而当System Server进程开启的时候,就会初始化AMS,同时,会加载本地系统的服务库,创建系统上下文,创建ActivityThread及开启各种服务等等。而在这之后,就会开启系统的Launcher程序,完成系统界面的加载与显示。【断点2】
Context总结
Context是一个抽象类,下面是它的注释信息,摘自源码。
- /**
- * Interface to global information about an application environment. This is
- * an abstract class whose implementation is provided by
- * the Android system. It
- * allows access to application-specific resources and classes, as well as
- * up-calls for application-level operations such as launching activities,
- * broadcasting and receiving intents, etc.
- */
- public abstract class Context {
从上面的这段话可以简单理解一下,Context是一个关于应用程序环境的全局变量接口,通过它可以允许去获得资源或者类,例如启动Activity,广播,intent等等。
我的理解:Context的具体实现是Application, Activity,Service,通过Context能够有权限去做一些事情,其实我觉得就是一个运行环境的问题。
需要注意的地方
Android开发中由于很多地方都包含了Context的使用,因此就必须要注意到内存泄露或者是一些可能会引起的问题。
例如在Toast中,它的Context就最好设置为Application Context,因为如果Toast在显示东西的时候Activity关闭了,但是由于Toast仍然持有Activity的引用,那么这个Activity就不会被回收掉,也就造成了内存泄露。
Toast的相关总结
上面举例的时候举到了Toast,其实Toast也是很有意思的一个东西,它的show方法其实并不是显示一个东西这么简单。
Toast实际上是一个队列,会通过show方法把新的任务加入到队列当中去,列队中只要存在消息就会弹出来使用,而队列的长度据说默认是40个(这是网上搜出来的,我在源码中没找到对应的设置,感觉也没啥必要就没找了)。
所以这里就要注意一下show这个操作了,它并不是显示内容,而是把内容入队列。
- /**
- * Show the view for the specified duration.
- */
- public void show() {
- if (mNextView == null) {
- throw new RuntimeException("setView must have been called");
- }
- INotificationManager service = getService();
- String pkg = mContext.getOpPackageName();
- TN tn = mTN;
- tn.mNextView = mNextView;
- try {
- service.enqueueToast(pkg, tn, mDuration);
- } catch (RemoteException e) {
- // Empty
- }
- }
Handler的内存泄露
对于Handler来说,如果我们直接在AndroidStudio中创建一个非静态内部类Handler,那么Handler这一大片的区域会被AS标记为黄色,这个应该很多人都遇到过吧。实际上是因为这样设置会造成内存泄露,因为每一个非静态内部类都会持有一个外部类的引用,那么这里也就产生了一个内存泄露的可能点,如果当Activity被销毁时没有与Handler解除,那么Handler仍然会持有对该Activity的引用,那么就造成了内存泄露。
解决方案
使用static修饰Handler,这样也就成了一个静态内部类,那么就不会持有对外部类的引用了。而这个时候就可以在Handler中创建一个WeakReference(弱引用)来持有外部的对象。只要外部解除了与该引用的绑定,那么垃圾回收器就会在发现该弱引用的时候立刻回收掉它。
垃圾回收
关于垃圾回收的相关总结看我之前的博客,传送门:JVM原理及底层探索
四种引用方式
上面扯到了弱引用,就再BB一下四种引用方式吧。
- 强引用:垃圾回收器打死都不会回收掉一个强引用的,那怕是出现OOM也不会回收掉强引用,所有new出来的都是强引用。
- 软引用:垃圾回收器会在内存不足的情况下回收掉软引用,如果内存充足的话不会理它
- 弱引用:它跟软引用类似,但是它更脆弱,只要垃圾回收器一发现它,就会立刻回收掉它。比如一个对象持有一个强引用和弱引用,当强引用被取消时,那么只要GC发现了它,就会立刻回收掉。只是GC发现它的这个过程是不确定的,有可能不会马上发生,所以它可能还会多活一会,中间存在一个优先级。
- 虚引用:它跟上面3种方式都不同。我对虚引用的理解就是如果一个对象持有虚引用,那么就可以在被GC回收前进行一些设定好的工作等等。因为虚引用有个机制,因为虚引用必须和引用队列联合使用,当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就回在回收对象的内存前,把这个虚引用加入到与之关联的引用队列中。而程序如果判断到引用队列中已经加入了虚引用,那么就可以了解到被引用的对象马上就要被垃圾回收了,这个时候就可以做些被回收之前的事情啦。
ClassLoader
类加载器按层次从顶层到下依次为Boorsrtap ClassLoader(启动类加载器),Extension ClassLoader(拓展类加载器),ApplicationClassLoader(应用程序类加载器)
判断两个类是否是同一个类就是看它们是否是由同一个类加载器加载而来。
这里就需要介绍一下双亲委派模式了:
双亲委派模式的意思就是:除了启动类加载器之外,其余的加载器都需要指定一个父类的加载器,当需要加载的时候会先让父类去试着加载,如果父类无法加载也就是找不到这个类的话就会让子类去加载
好处:防止内存中出现多份同样的字节码
比如类A和类B都要加载system类,如果不是委托的话,类A就会加载一份,B也会加载一份,那么就会出现两份SYstem字节码
如果使用委托机制,会递归的向父类查找,也就是首选用Bootstrap尝试加载,如果找不到再向下,如果A用这个已经加载了的话会直接返回内存中的system而不需要重新加载。那么就只会存在一份
延迟加载的应用:单例模式
对于Java来说,类是需要使用到时才会加载,这里也就出现了一个延迟加载的效果。而在延迟加载的时候,会默认保持同步。这也就产生了一种单例模式的方式,具体的看我之前的博客:设计模式_单例模式
我觉得在android所有的创建单例模式方法中里延迟加载方式是最好吧,虽然枚举比延迟加载更好,effiective java中也很推荐,但是并不怎么适用于Android,Android里枚举的消耗是static的两倍,延迟加载的话只要我们在使用延迟加载方式时做好反序列化的返回值readResolve()准备就好了。
继续断点2
上面BB了太多其他的,现在有点缓不过来,下次自己看自己博客的时候会不会都被自己的思路带得乱七八糟的。
上面的时候我们就已经完成了整个Android系统的开机以及初始化。接下来就可以B一下从点击APP图标开始到APP内部程序运行起来的流程了。
当我们点击屏幕时,触摸屏的两层电极会连接在一起,也就产生了一个电压(具体的我忘了,书上有,图找不到了),当产生电压的时候,就可以通过对应的驱动把当前按压点的XY坐标传给上层,这里也就是操作系统。操作系统在获取到XY值的时候,就会对按压点的范围进行一个判断,如果确定按压点处于一个APP图标或者是Button等等的范围中时,操作系统也就会认为用户当前已经点击了这个东西,启动对应的监听。
而当系统判断我们点击的是APP图标时,该App就由Launcher开始启动了【断点3】
Launcher
Launcher是一个继承自Activity,同时实现了点击事件,长按事件等等的一个应用程序。
- public final class Launcher extends Activity
- implements View.OnClickListener,OnLongClickListener, LauncherModel.Callbacks,View.OnTouchListener
当我们点击一个APP的图标时,会调用Launcher内部的startActivitySafely()方法,而这个方法则会进行两件事,一个是启动目标activity,另一个功能就是捕获异常ActivityNotFoundException,也就是常见的“找不到activity,是否已经在androidmenifest文件中注册?”。而在startActivity方法中,经过一系列的转换最终会调用到startActivityForResult这个方法。
- @Override
- public void startActivity(Intent intent, @Nullable Bundle options) {
- if (options != null) {
- startActivityForResult(intent, -1, options);
- } else {
- // Note we want to go through this call for compatibility with
- // applications that may have overridden the method.
- startActivityForResult(intent, -1);
- }
- }
所以实际上,我对整个Android的界面是这样理解的:
当系统完成初始化以及各种服务的创建之后,就会启动Launcher这个应用程序(它也是继承自Activity的,包含自己对应的xml布局文件),然后再把各种图标按照一个正常APP布局的方式放在上面,当我们点击APP图标时,也就相当于在Launcher这个APP应用程序中通过startActivity(在底层最后会转为startActivityForResult)来启动这个APP。简单的讲,我觉得就是一个主要的APP(Launcher)里面启动了其他的功能APP,例如QQ、微信这些。【个人理解,如果以后发现不对再修改】
Android中点击事件的处理
当我们手指按下时,Android是如何处理点击事件的呢?如何确定是让哪一个控件来处理呢?
简单一句话:层层传递-冒泡的方式处理
举个例子:现在公司来了个小项目,老板一看分配给经理做,经理一看分配给小组长,小组长一看好简单,分配给组员。如果在这个传递过程中(也就是还为分配到最底部时),某一层觉得我来负责这个比较好的话就会拦截掉这个消息,然后把它处理了,下面的就收不到有消息的这个通知。如果一直到了底层的话,组员如果能完成,就完成它。如果不能完成,那么就报告给组长,说组长我做不来,边学边做要影响进度。组长一看我也做不来,就给经理,经理一看我也不会,就给老板。这样也就一层层的传递了。
总结一下就是消息从上到下依次传递,如果在传递的过程中被拦截了就停止下传。如果没有被拦截,就一直传递到底部,如果底部不能够消耗该消息,那么就又一层层的返回来,返给上层,直到被消耗或者是到达最顶层。
在Android中,存在三个重要的方法:
- dispathTouchEvent(MotionEvent ev)
- onInterceptTouchEvent(MotionEvent ev)
- onTouchEvent(MotionEvent ev)
第一个方法负责事件的分发,它的返回值就是表示是否消耗当前事件。
第二个方法是用于判断是否拦截该消息,如果当前View拦截了某个时间,那么在同一个事件序列中,此方法不会被再次调用。返回结果表示是否拦截当前事件
第三个方法就是处理事件。返回结果表示是否消耗当前事件,如果不小号,则在同一时间序列中,当前View无法再次接收到事件。
对于一个根ViewGroup来说,点击事件产生后,首先会传递给它,调用它的dispath方法。如果这个ViewGroup的onIntercept方法返回true就表示它要拦截当前事件,false就表示不拦截,这个时候事件就会继续传递给子元素,接着调用子元素的dispath方法,直到被处理。
滑动冲突
顺带总结一下滑动冲突的解决吧
View的滑动冲突一般可以分为三种:
- 外部滑动和内部滑动方向不一致
- 外部滑动方向和内部滑动方向一致
- 嵌套上面两种情况
比如说一个常见的,外部一个ListView,里面一个ScrollView。这个时候该怎么解决呢?其实这里想到了ViewPager,它里面实际上是解决了滑动冲突的,可以借鉴一下它的。
滑动处理规则
一般来说,我们可以根据用户手指滑动的方向以及角度来判断用户是要朝着哪个方向去滑动。而很多时候还可以根据项目的需求来指定一套合适的滑动方案。
外部拦截法
这种方法就是指所有的点击时间都经过父容器的拦截处理,如果父容器需要此时间就拦截,如果不需要此事件就不拦截。通过重写父容器的onInterceptTouchEvent方法:
- case MotionEvent.ACTION_DOWN:
- intercepted = false;
- break;
- case MotionEvent.ACTION_MOVE:
- if(父类容器需要) {
- intercepted = true;
- } else {
- intercepted = false;
- }
- break;
- case MotionEvent.ACTION_UP:
- intercepted = false;
- break;
- return intercepted;
这里有一点需要注意,ACTION_DOWN事件父类容器就必须返回false,因为如果父类容器拦截了的话,后面的Move等所有事件都会直接由父类容器处理,就无法传给子元素了。UP事件也要返回false,因为它本身来说没有太多的意义,但是对于子元素就不同了,如果拦截了,那么子元素的onClick事件就无法触发。
内部拦截法
这种方法指的是父容器不拦截任何时间,所有的事件都传递给子元素,如果子元素需要此事件就直接消耗掉,否则就交给父容器进行处理。它需要配合requestDisallowInterceptTouchEvent方法才能正常工作。我们需要重写子元素的dispatch方法
- case MotionEvent.ACTION_DOWN:
- parent.requestDisallowInterceptTouchEvent(true);
- break;
- MotionEvent.ACTION_MOVE:
- if(父容器需要此类点击事件) {
- parent.requestDisallowInterceptTouchEvent(false);
- }
- break;
- return super.dispatchTouchEvent(event);
这种方法的话父类容器需要默认拦截除了ACTION_DOWN以外的其他时间,这样当子元素调用request方法的时候父元素才能继续拦截所需的事件。
其他的
如果觉得上面两个方式太复杂,看晕了,其实也可以自己根据项目的实际需要来指定自己的策略实现。例如根据你手指按的点的位置来判断你当前触碰的是哪个控件,以此来猜测用户是否是要对这个控件进行操作。如果点击的是空白的地方,就操作外部控件即可。
【等有时间了就把ViewPager的处理总结一下,挺重要的】
继续断点3
- 当我们点击桌面的APP图标时,Launcher进程会采用Binder的方式向AMS发出startActivity请求
- AMS在接收到请求之后,就会通过Socket向Zygote进程发送创建进程的请求
- Zygote进程会fork出新的子进程(APP进程)
- 之后APP进程会再向AMS发起一次请求,AMS收到之后经过一系列的准备工作再回传请求。
- APP进程收到AMS返回的请求后,会利用Handler向主线程发送LAUNCH_ACTIVITY消息
- 主线程在收到消息之后,就创建目标Activity,并回调onCreate()/onStart()/onResume()等方法,UI渲染结束后便可以看到App主界面
【断点4】
Handler/Looper/Message Queue/ThreadLocal机制
Android的消息机制主要是指Handler的运行机制,Handler的运行需要底层的MessageQueue和Looper的支撑
虽然MessageQueue叫做消息队列,但是实际上它内部的存储结构是单链表的方式。由于Message只是一个消息的存储单元,它不能去处理消息,这个时候Looper就弥补了这个功能,Looper会以无限循环的形式去查找是否有新消息,如果有的话就处理消息,否则就一直等待(机制等会介绍)。而对于Looper来说,存在着另外的一个很重要的概念,就是ThreadLocal。
ThreadLocal
ThreadLocal它并不是一个线程,而是一个可以在每个线程中存储数据的数据存储类,通过它可以在指定的线程中存储数据,数据存储之后,只有在指定线程中可以获取到存储的数据,对于其他线程来说则无法获取到该线程的数据。
举个例子,多个线程通过同一个ThreadLocal获取到的东西是不一样的,就算有的时候出现的结果是一样的(偶然性,两个线程里分别存了两份相同的东西),但他们获取的本质是不同的。
那为什么有这种区别呢?为什么要这样设计呢?
先来研究一下为什么会出现这个结果。
在ThreadLocal中存在着两个很重要的方法,get和set方法,一个读取一个设置。
- /**
- * Returns the value of this variable for the current thread. If an entry
- * doesn‘t yet exist for this variable on this thread, this method will
- * create an entry, populating the value with the result of
- * {@link #initialValue()}.
- *
- * @return the current value of the variable for the calling thread.
- */
- @SuppressWarnings("unchecked")
- public T get() {
- // Optimized for the fast path.
- Thread currentThread = Thread.currentThread();
- Values values = values(currentThread);
- if (values != null) {
- Object[] table = values.table;
- int index = hash & values.mask;
- if (this.reference == table[index]) {
- return (T) table[index + 1];
- }
- } else {
- values = initializeValues(currentThread);
- }
- return (T) values.getAfterMiss(this);
- }
- /**
- * Sets the value of this variable for the current thread. If set to
- * {@code null}, the value will be set to null and the underlying entry will
- * still be present.
- *
- * @param value the new value of the variable for the caller thread.
- */
- public void set(T value) {
- Thread currentThread = Thread.currentThread();
- Values values = values(currentThread);
- if (values == null) {
- values = initializeValues(currentThread);
- }
- values.put(this, value);
- }
摘自源码
首先研究它的get方法吧,从注释上可以看出,get方法会返回一个当前线程的变量值,如果数组不存在就会创建一个新的。
这里有几个很重要的词,就是“当前线程”和“数组”。
这里提到的数组对于每个线程来说都是不同的,values.table,而values是通过当前线程获取到的一个Values对象,因此这个数组是每个线程唯一的,不能共用,而下面的几句话也更直接了,获取一个索引,再返回通过这个索引找到数组中对应的值。这也就解释了为什么多个线程通过同一个ThreadLocal返回的是不同的东西。
那这里为什么要这么设置呢?翻了一下书,搜了一下资料:
- ThreadLocal在日常开发中使用到的地方较少,但是在某些特殊的场景下,通过ThreadLocal可以轻松实现一些看起来很复杂的功能。一般来说,当某些数据是以线程为作用域并且不同线程具有不同的数据副本的时候,就可以考虑使用ThreadLocal。例如在Handler和Looper中。对于Handler来说,它需要获取当前线程的Looper,很显然Looper的作用域就是线程并且不同的线程具有不同的Looper,这个时候通过ThreadLocal就可以轻松的实现Looper在线程中的存取。如果不采用ThreadLocal,那么系统就必须提供一个全局的哈希表供Handler查找指定的Looper,这样就比较麻烦了,还需要一个管理类。
- ThreadLocal的另一个使用场景是复杂逻辑下的对象传递,比如监听器的传递,有些时候一个线程中的任务过于复杂,就可能表现为函数调用栈比较深以及代码入口的多样性,这种情况下,我们又需要监听器能够贯穿整个线程的执行过程。这个时候就可以使用到ThreadLocal,通过ThreadLocal可以让监听器作为线程内的全局对象存在,在线程内通过get方法就可以获取到监听器。如果不采用的话,可以使用参数传递,但是这种方式在设计上不是特别好,当调用栈很深的时候,通过参数来传递监听器这个设计太糟糕。而另外一种方式就是使用static静态变量的方式,但是这种方式存在一定的局限性,拓展性并不是特别的强。比如有10个线程在执行,就需要提供10个监听器对象。
消息机制
上面提到了Handler/Looper/Message Queue,它们实际上是一个整体,只不过我们在开发中接触更多的是Handler而已,Handler的主要作用是将一个任务切换到某个指定的线程中去执行,而Android之所以提供这个机制是因为Android规定UI只能在主线程中进程,如果在子线程中访问UI就会抛出异常。
为什么Android不允许在子线程访问UI
其实这一点不仅仅是对于Android,对于其他的所有图形界面现在都采用的是单线程模式。
因为对于一个多线程来说,如果子线程更改了UI,那么它的相关操作就必须对其他子线程可见,也就是Java并发中很重要的一个概念,线程可见性,Happen-before原则【下篇博客总结一下自己对Java并发的理解吧,挺重要的,总结完后再把传送门贴过来】而一般来说,对于这种并发访问,一般都是采用加锁的机制,但是加锁的机制存在很明显的问题:让UI访问间的逻辑变得复杂,同时效率也会降低。甚至有的时候还会造成死锁的情况,这个时候就麻烦了。
而至于究竟能不能够实现这种UI界面的多线程呢?SUN公司的某个大牛(忘了是谁,很久之前看的,好像是前副总裁)说:“行肯定是没问题,但是非常考技术,因为必须要考虑到很多种情况,这个时候就需要技术专家来设计。而这种设计出来的东西对于广大普通程序员来说又是异常头疼的,就算是实现了多线程,普通人用起来也是怨声载道的。所以建议还是单线程”。
死锁
顺带着BB一下死锁。
死锁的四个必要条件
- 互斥条件:资源不能被共享,只能被同一个进程使用
- 请求与保持条件:已经得到资源的进程可以申请新的资源
- 非剥夺条件:已经分配的资源不能从相应的进程中被强制剥夺
- 循环等待条件:系统中若干进程组成环路,该环路中每个进程都在等待相邻进程占用的资源
举个常见的死锁例子:进程A中包含资源A,进程B中包含资源B,A的下一步需要资源B,B的下一步需要资源A,所以它们就互相等待对方占有的资源释放,所以也就产生了一个循环等待死锁。
处理死锁的方法
- 忽略该问题,也就是鸵鸟算法。当发生了什么问题时,不管他,直接跳过,无视它。
- 检测死锁并恢复
- 资源进行动态分配
- 破除上面的四种死锁条件之一
继续消息机制
MessageQueue主要包含两个操作:插入和读取,读取操作本身会伴随着删除操作,插入和读取对应的方法分别为enqueueMessage和next,其中enqueueMessage的作用是往消息队列中插入一条消息,而next的作用是从消息队列中取出一条消息并将其从消息队列中移除。这也就是为什么使用的是一个单链表的数据结构来维护消息列表,因为它在插入和删除上比较有优势(把下一个连接的点切换一下就完成了)。
而对于MessageQueue的插入操作来说,没什么可以看的,也就这样吧,主要需要注意的是它的读取方法next。
源码有点长,总结一下就是:
next方法它是一个死循环,如果消息队列中没有消息,那么next方法就会一直阻塞在这里,当有新的消息来的时候,next方法就会返回这条信息并将其从单链表中移除。
而这个时候勒Looper就等着的,它也是一直循环循环,不停地从MessageQueue中查看是否有新消息,如果有新消息就会立刻处理,否则就会一直阻塞在那里。而对于Looper来说,它是只能创建一个的,这个要归功与它的prepare方法。
- /** Initialize the current thread as a looper.
- * This gives you a chance to create handlers that then reference
- * this looper, before actually starting the loop. Be sure to call
- * {@link #loop()} after calling this method, and end it by calling
- * {@link #quit()}.
- */
- public static void prepare() {
- prepare(true);
- }
- private static void prepare(boolean quitAllowed) {
- if (sThreadLocal.get() != null) {
- throw new RuntimeException("Only one Looper may be created per thread");
- }
- sThreadLocal.set(new Looper(quitAllowed));
- }
从这里我们就可以看出该prepare方法会首先检测是否已经存在looper了,如果不存在,就创建一个新的;如果存在,就抛出异常。
而之后使用Looper.loop()就可以开启消息循环了。
- /**
- * Run the message queue in this thread. Be sure to call
- * {@link #quit()} to end the loop.
- */
- public static void loop() {
- final Looper me = myLooper();
- if (me == null) {
- throw new RuntimeException("No Looper; Looper.prepare() wasn‘t called on this thread.");
- }
- final MessageQueue queue = me.mQueue;
- // Make sure the identity of this thread is that of the local process,
- // and keep track of what that identity token actually is.
- Binder.clearCallingIdentity();
- final long ident = Binder.clearCallingIdentity();
- for (;;) {
- Message msg = queue.next(); // might block
- if (msg == null) {
- // No message indicates that the message queue is quitting.
- return;
- }
- // This must be in a local variable, in case a UI event sets the logger
- Printer logging = me.mLogging;
- if (logging != null) {
- logging.println(">>>>> Dispatching to " + msg.target + " " +
- msg.callback + ": " + msg.what);
- }
- msg.target.dispatchMessage(msg);
- if (logging != null) {
- logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
- }
- // Make sure that during the course of dispatching the
- // identity of the thread wasn‘t corrupted.
- final long newIdent = Binder.clearCallingIdentity();
- if (ident != newIdent) {
- Log.wtf(TAG, "Thread identity changed from 0x"
- + Long.toHexString(ident) + " to 0x"
- + Long.toHexString(newIdent) + " while dispatching to "
- + msg.target.getClass().getName() + " "
- + msg.callback + " what=" + msg.what);
- }
- msg.recycleUnchecked();
- }
- }
从这里面我们可以看到它也是个死循环,会不停的调用queue.next()方法来获取信息,如果没有,就return,如果有就处理。
注意
当然了,这里有一个很重要的点,一般可能会忘,那就是在子线程中如果手动为其创建了Looper,那么在所有的事情完成以后应该调用quit方法来终止消息循环,否则这个子线程就会一直处于等待状态,而如果退出Looper之后,这个线程就会立刻终止,所以建议不需要使用的时候终止Looper。
Handler
上面总结了Looper和MessageQueue,这里就对Handler进行一个总结吧。它的工作主要包含消息的发送和接受过程,消息的发送可以通过post的一系列方法以及send的一系列方法来实现,post的一系列方法最终是通过send的一系列方法来实现的。
实际上它发送消息的过程仅仅是向消息队列中插入了一条消息,MessageQueue的next方法就会返回这条消息给Looper,Looper在收到消息之后就会开始处理了。最后由Looper交给Handler处理(handleMessage()方法)。
IPC通信
上面总结完了Android的消息处理机制,那么就顺带总结一下IPC通信吧,毕竟上面提到过那么多次Binder和Socket。
资料:为什么Android要采用Binder作为IPC机制?
知乎上面的回答相当的好,这个博主对系统底层也是颇有钻研,学习。
这里就结合上面的知乎回答以及加上《Linux程序设计》还有一本Linux内核剖析(书名忘了但是讲得真的非常好),掺杂一些个人的理解。
进程的定义
UNIX标准把进程定义为:“一个其中运行着一个或多个进程的地址控件和这些线程所需要的系统资源”。目前,可以简单的把进程看做正在运行的程序。
进程都会被分配一个唯一的数字编号,我们成为PID(也就是进程标识符),它通常是一个取值范围从2到32768的正整数。当进程被启动时,系统将按顺序选择下一个未被使用的数字作为PID,当数字已经回绕一圈时,新的PID重新从2开始,数字1一般是为init保留的。在进程中,存在一个自己的栈空间,用于保存函数中的局部变量和控制函数的调用与返回。进程还有自己的环境空间,包含专门为这个进程建立的环境变量,同时还必须要维护自己的程序计数器,这个计数器用来记录它执行到的位置,即在执行线程中的位置。
在Linux中可以通过system函数来启动一个进程
守护进程
这里就需要提到一个守护进程了,这个在所有的底层中经常都会被提到。
在linux或者unix操作系统中在系统引导的时候会开启很多服务,这些服务就叫做守护进程。为了增加灵活性,root可以选择系统开启的模式,这些模式叫做运行级别,每一种运行级别以一定的方式配置系统。 守护进程是脱离于终端并且在后台运行的进程。守护进程脱离于终端是为了避免进程在执行过程中的信息在任何终端上显示并且进程也不会被任何终端所产生的终端信息所打断。
守护进程常常在系统引导装入时启动,在系统关闭时终止。如果想要某个进程不因为用户或终端或其他的变化而受到影响,那么就必须把这个进程变成一个守护进程
防止手机服务后台被杀死
是不是在手机的设置界面看当前正在运行的服务时会发现有的APP不止存在一个服务?有的APP后台存在两个,有的存在三个?有的流氓软件也会这么设置,这样的话就可以一直运行在后台,用户你关也关不了(倒不是说所有这么设置的都是流氓软件,因为有的软件需要保持一个长期的后台在线,这是由功能决定的)。
这里有两种方法(可能还有更多,这里只总结我了解的):
- 第一种方法就是利用android中service的特性来设置,防止手机服务后台被杀死。通过更改onStartCommand方法的返回值,将service设置为粘性service,那么当service被kill的时候就会将服务的状态返回到最开始启动的状态,也就是运行的状态,所以这个时候也就会再次重新运行。但是需要注意一点,这个时候的intent值就为空了,获取的话需要注意一下这一点。
- 第二种就是fork出一个C的进程,因为在Linux中,子类进程在父类被杀死销毁的时候不会随之杀死,它会被init进程领养。所以也就可以使用这一个方法,利用主进程fork出一个C进程在后台运行,一旦检测到服务被杀死(检测的方式多种,可使用观察者模式,广播,轮询等等),就重启服务即可
IPC通信
上面总结了进程的相关基础,这里就开始总结一下进程间通信(IPC
)的问题了。
现在Linux现有的所有IPC方式:
- 管道:在创建时分配一个page大小的内存,缓存区大小有限
- 消息队列:信息复制两次,额外的cpu消耗,不适合频繁或信息量大的通信
- 共享内存:无需复制,共享缓冲区直接附加到进程虚拟地址控件,速度是在所有IPC通信中最快的。但是进程间的同步问题操作系统无法实现,必须由各进程利用同步工具解决。
- Socket:作为更通用的接口,传输效率低,主要用于不通机器或跨网络的通信
- 信号量:常作为一种锁机制。
- 信号:不适用于信息交换,更适用于进程件中断控制,例如kill process
到了这里,就有了问题,为什么在Linux已经存在这么多优良的IPC方案时,Android还要采取一种新的Binder机制呢?
猜测:我觉得Android采用这种新的方式(当然也大面积的同时使用Linux的IPC通信方式),最多两个原因:
- 推广时手机厂商自定义ROM底层的保密性或者公司之间的关系。
- 在某些情况下更适合手机这种低配置,对效率要求极高,用户体验极其重要的设备
资料
对于Binder来说,存在着以下的优势:
- 性能角度:Binder的数据拷贝只需要一次,而管道、消息队列、Socket都需要2次,而共享内存是一次都不需要拷贝,因此Binder的性能仅次于共享内存
- 稳定性来说:Binder是基于C/S架构的,也就是Client和Server组成的架构,Client端有什么需求,直接发送给Server端去完成,架构清晰,分工明确。而共享内存的实现方式复杂,需要充分考虑访问临界资源的并发同步问题,否则可能会出现死锁等问题。从稳定性来说,Binder的架构优于共享内存。
- 从安全的角度:Linux的传统IPC方式的接收方无法获得对方进程可靠的UID(用户身份证明)/PID(进程身份证明),从而无法鉴别对方身份,而Android是一个对安全性能要求特别高的操作系统,在系统层面需要对每一个APP的权限进行管控或者监视,对于普通用户来说,绝对不希望从App商店下载偷窥隐射数据、后台造成手机耗电等问题。传统的Linux IPC无任何保护措施,完全由上层协议来确保。而在Android中,操作系统为每个安装好的应用程序分配了自己的UID,通过这个UID可以鉴别进程身份。同时Android系统对外只暴露Client端,Client端将任务发送给Server端,Server端会根据权限控制策略判断UID/PID是否满足访问权限。也就是说Binder机制对于通信双方的身份是内核进行校验支持的。例如Socket方式只需要指导地址就可以连接,他们的安全机制需要上层协议来假设
- 从语言角度:Linux是基于C的,而Android是基于Java的,而Binder是符合面向对象思想的。它的实体位于一个进程中,而它的引用遍布与系统的各个进程之中,它是一个跨进程引用的对象,模糊了进程边界,淡化了进程通信的过程,整个系统仿佛运行于同一个面向对象的程序之中。
- 从公司角度:Linux内核是开源的,GPL协议保护,受它保护的Linux Kernel是运行在内核控件,对于上层的任何类库、服务等只要进行系统调用,调用到底层Kernel,那么也必须遵循GPL协议。而对于Android来说,Google巧妙地将GPL协议控制在内核控件,将用户控件的协议采用Apache-2.0协议(允许基于Android的开发商不向社区反馈源码)。
反射
刚才谈到Binder的时候提了一下效率的问题,那这里就不得不讲到反射了。
反射它允许一个类在运行过程中获得任意类的任意方法,这个是Java语言的一个很重要的特性。它方便了程序员的编写,但是降低了效率。
实际上,对于只要不是特别大的项目(非Android),反射对于效率的影响微乎其微,而与之对比的开发成本来说就更划算了。
但是,Android是一个用于手机的,它的硬件设施有限,我们必须要考虑到它的这个因素,用户体验是最重要的。以前看到过国外的一项统计。在一个APP中的Splash中使用了反射,结果运行时间增加了一秒,这个已经算是很严重的效率影响了。
为什么反射影响效率呢
这里就需要提到一个东西,JIT编译器。JIT编译器它可以把字节码文件转换为机器码,这个是可以直接让处理器使用的,经过它处理的字节码效率提升非常大,但是它有一个缺点,就是把字节码转换成机器码的过程很慢,有的时候甚至还超过了不转换的代码效率(转换之后存在一个复用的问题,对于转换了的机器码,使用的次数越多就越值的)。因此,在JVM虚拟机中,也就产生了一个机制,把常用的、使用频率高的字节码通过JIT编译器转换,而频率低的就不管它。而反射的话则是直接越过了JIT编译器,不管是常用的还是非常用的字节码一律没有经过JIT编译器的转化,所以效率就会低。
而在Android里面,5.0之前使用的是Davlik虚拟机,它就是上面的机制,而在Android5.0之后Google使用了一个全新的ART虚拟机全面代替Davlik虚拟机。
ART虚拟机会在程序安装时直接把所有的字节码全部转化为机器码,虽然这样会导致安装时间边长,但是程序运行的效率提升非常大。
【疑问:那在Android5.0之后的系统上,反射会不会没影响了?由于现在做项目的时候更多考虑的是向下兼容,单独考虑5.0的情况还没有,等以后有需求或者是有机会的时候再深入了解一下,以后更新】
继续断点4
刚才总结了Android的消息处理机制和IPC通信,那么我们主线程的消息处理机制是什么时候开始的呢?因为我们知道在主线程中我们是不需要手动调用Looper.prepare()和Looper.loop()的。
Android的主线程就是ActivityThread,主线程的入口方法是main方法,在main方法中系统会通过Looper.prepareMainLooper()来创建主线程的Looper以及MessageQueue,并通过Looper.loop来开启消息循环,所以这一步实际上是系统已经为我们做了,我们就不再需要自己来做。
ActivityThread通过AppplicationThread和AMS进行进程件通信,AMS以进程间通信的方式完成ActivityThread的请求后会回调ApplicationThread中的Binder方法,然后ApplicationThread会向Handler发送消息,Handler收到消息后会将ApplicationThread中的逻辑切换到主线程中去执行,这个过程就是主线程的消息循环模型。
上面总结到了APP开始运行,依次调用onCreate/onStart/onResume等方法,那么在onCreate方法中我们经常使用的setContentView和findViewById做了什么事呢?
Activity界面显示
首先,就考虑到第一个问题,也就是setContentView这个东西做了什么事,这里就要对你当前继承的Activity分类了,如果是继承的Activity,那么setContentView源码是这样的:
- /**
- * Set the activity content from a layout resource. The resource will be
- * inflated, adding all top-level views to the activity.
- *
- * @param layoutResID Resource ID to be inflated.
- *
- * @see #setContentView(android.view.View)
- * @see #setContentView(android.view.View, android.view.ViewGroup.LayoutParams)
- */
- public void setContentView(@LayoutRes int layoutResID) {
- getWindow().setContentView(layoutResID);
- initWindowDecorActionBar();
- }
- /**
- * Set the activity content to an explicit view. This view is placed
- * directly into the activity‘s view hierarchy. It can itself be a complex
- * view hierarchy. When calling this method, the layout parameters of the
- * specified view are ignored. Both the width and the height of the view are
- * set by default to {@link ViewGroup.LayoutParams#MATCH_PARENT}. To use
- * your own layout parameters, invoke
- * {@link #setContentView(android.view.View, android.view.ViewGroup.LayoutParams)}
- * instead.
- *
- * @param view The desired content to display.
- *
- * @see #setContentView(int)
- * @see #setContentView(android.view.View, android.view.ViewGroup.LayoutParams)
- */
- public void setContentView(View view) {
- getWindow().setContentView(view);
- initWindowDecorActionBar();
- }
- /**
- * Set the activity content to an explicit view. This view is placed
- * directly into the activity‘s view hierarchy. It can itself be a complex
- * view hierarchy.
- *
- * @param view The desired content to display.
- * @param params Layout parameters for the view.
- *
- * @see #setContentView(android.view.View)
- * @see #setContentView(int)
- */
- public void setContentView(View view, ViewGroup.LayoutParams params) {
- getWindow().setContentView(view, params);
- initWindowDecorActionBar();
- }
这里面存在着3个重载函数,而不管你调用哪一个,最后都会调用到initWindowDecorActionBar()这个方法。
而对于新的一个AppcompatActivity,这个Activity里面包含了一些新特性,现在我做的项目里基本都是使用AppcompatActivity代替掉原来的Activity,当然也并不是一定的,还是要根据项目的实际情况来选择。
在AppcompatActivity中,setContentView是这样的:
- @Override
- public void setContentView(@LayoutRes int layoutResID) {
- getDelegate().setContentView(layoutResID);
- }
- @Override
- public void setContentView(View view) {
- getDelegate().setContentView(view);
- }
- @Override
- public void setContentView(View view, ViewGroup.LayoutParams params) {
- getDelegate().setContentView(view, params);
- }
一样的3个重载函数,只是里面没有了上面的那个init方法,取而代之的是一个getDelegate().setContentView,这个delegate从字面上可以了解到它是一个委托的对象,源码是这样的:
- /**
- * @return The {@link AppCompatDelegate} being used by this Activity.
- */
- @NonNull
- public AppCompatDelegate getDelegate() {
- if (mDelegate == null) {
- mDelegate = AppCompatDelegate.create(this, this);
- }
- return mDelegate;
- }
- 而在AppCompatDelegate.Create方法中,则会返回一个很有意思的东西:
- /**
- * Create a {@link android.support.v7.app.AppCompatDelegate} to use with {@code activity}.
- *
- * @param callback An optional callback for AppCompat specific events
- */
- public static AppCompatDelegate create(Activity activity, AppCompatCallback callback) {
- return create(activity, activity.getWindow(), callback);
- }
- private static AppCompatDelegate create(Context context, Window window,
- AppCompatCallback callback) {
- final int sdk = Build.VERSION.SDK_INT;
- if (sdk >= 23) {
- return new AppCompatDelegateImplV23(context, window, callback);
- } else if (sdk >= 14) {
- return new AppCompatDelegateImplV14(context, window, callback);
- } else if (sdk >= 11) {
- return new AppCompatDelegateImplV11(context, window, callback);
- } else {
- return new AppCompatDelegateImplV7(context, window, callback);
- }
- }
这里会根据SDK的等级来返回不同的东西,这样的话就不深究了,底层的话我撇了一下,应该原理和Activity是一样的,可能存在一些区别。这里就用Activity来谈谈它的setContentView方法做了什么事。
在setContentView上面有段注释:
Set the activity content from a layout resource. The resource will be inflated, adding all top-level views to the activity.
这里就介绍了它的功能,它会按照一个布局资源去设置Activity的内容,而这个布局资源将会被引入然后添加所有顶级的Views到这个Activity当中。
这是个啥意思勒。
下面从网上扒了一张图:
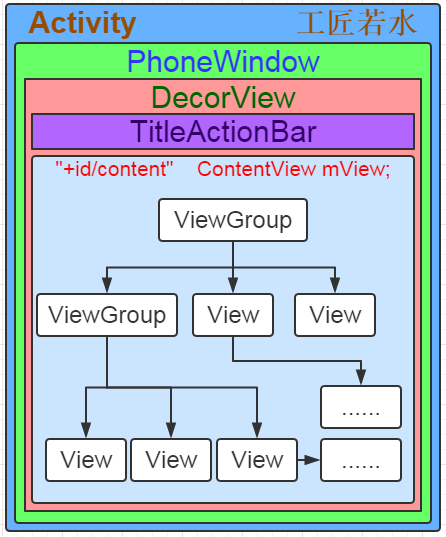
这里是整个Activity的层级,最外面一层是我们的Activity,它包含里面的所有东西。
再上一层是一个PhoneWindow,这个PhoneWindow是由Window类派生出来的,每一个PhoneWindow中都含有一个DecorView对象,Window是一个抽象类。
再上面一层就是一个DecorView,我理解这个DecorView就是一个ViewGroup,就是装View的。
而在DecoreView中,最上面的View就是我们的TitleActionBar,下面就是我们要设置的content。所以在上面的initWindowDecorActionBar就能猜到是什么意思了吧。
而在initWindowDecorActionBar方法中,有一段代码:
- /**
- * Creates a new ActionBar, locates the inflated ActionBarView,
- * initializes the ActionBar with the view, and sets mActionBar.
- */
- private void initWindowDecorActionBar() {
- Window window = getWindow();
- // Initializing the window decor can change window feature flags.
- // Make sure that we have the correct set before performing the test below.
- window.getDecorView();
- if (isChild() || !window.hasFeature(Window.FEATURE_ACTION_BAR) || mActionBar != null) {
- return;
- }
- mActionBar = new WindowDecorActionBar(this);
- mActionBar.setDefaultDisplayHomeAsUpEnabled(mEnableDefaultActionBarUp);
- mWindow.setDefaultIcon(mActivityInfo.getIconResource());
- mWindow.setDefaultLogo(mActivityInfo.getLogoResource());
- }
注意上面的window.getDecoreView()方法的注释,该方法会设置一些window的标志位,而当这个方法执行完之后,就再也不能更改了,这也就是为什么很多第三方SDK设置window的标志位时一定要求要在setContentView方法前调用。
findViewById
我们通过一个findViewById方法可以实现对象的绑定,那它底层究竟是怎么实现的呢?
findViewById根据继承的Activity类型的不同也存在着区别,老规矩,还是以Activity的来。
- /**
- * Finds a view that was identified by the id attribute from the XML that
- * was processed in {@link #onCreate}.
- *
- * @return The view if found or null otherwise.
- */
- @Nullable
- public View findViewById(@IdRes int id) {
- return getWindow().findViewById(id);
- }
从源码来看,findViewById也是经过了一层层的调用,它的功能如同它上面的注释一样,通过一个view的id属性查找view,这里也可以看到一个熟悉的getWindow方法,说明findViewById()实际上Activity把它也是交给了自己的window来做
- /**
- * Finds a view that was identified by the id attribute from the XML that
- * was processed in {@link android.app.Activity#onCreate}. This will
- * implicitly call {@link #getDecorView} for you, with all of the
- * associated side-effects.
- *
- * @return The view if found or null otherwise.
- */
- @Nullable
- public View findViewById(@IdRes int id) {
- return getDecorView().findViewById(id);
- }
而在这里面,又调用了getDecorView的findViewById()方法,这也相当于是一个层层传递的过程,因为DecorView我理解为就是一个ViewGroup,而当运行getDecorView().findViewById()方法时,就会运行View里面的findViewById方法。它会使用这个被给予的id匹配子View的Id,如果匹配,就返回这个View,完成View的绑定
- /**
- * Look for a child view with the given id. If this view has the given
- * id, return this view.
- *
- * @param id The id to search for.
- * @return The view that has the given id in the hierarchy or null
- */
- @Nullable
- public final View findViewById(@IdRes int id) {
- if (id < 0) {
- return null;
- }
- return findViewTraversal(id);
- }
- /**
- * {@hide}
- * @param id the id of the view to be found
- * @return the view of the specified id, null if cannot be found
- */
- protected View findViewTraversal(@IdRes int id) {
- if (id == mID) {
- return this;
- }
- return null;
- }
最后总结一下(Activity中),findViewById的过程是这样的:
Activity -> Window -> DecorView -> View
Android从启动到程序运行整个过程的整理
标签:
原文地址:http://www.cnblogs.com/zyanrong/p/5661114.html