标签:
文件系统的文件太多,而且是照搬的MINIX的文件系统,不想继续分析下去了。缓冲区机制和文件系统密切相关,所以这里就简单分析一下缓冲区机制。
buffer.c 程序用于对高速缓冲区(池)进行操作和管理。高速缓冲区位于内核代码块和主内存区之间,见图9-9 中所示。高速缓冲区在块设备与内核其它程序之间起着一个桥梁作用。除了块设备驱动程序以外,内核程序如果需要访问块设备中的数据,就都需要经过高速缓冲区来间接地操作。
因为读取磁盘数据很耗费时间,所以缓冲区的作用就是存储读过的磁盘数据,下次有需求直接从缓冲区读取,缓冲区是内存区域,读取非常快速。
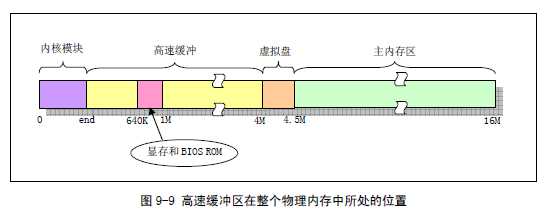
图中高速缓冲区的起始位置从内核模块末段end 标号开始,end 是内核模块链接期间由链接程序(ld)设置的一个值,内核代码中没有定义这个符号。当在连接生成system 模块时,ld 程序的digest_symbols()函数会产生此符号。该函数主要用于对全局变量进行引用赋值,并且计算每个被连接文件的其始和大小,其中也设置了end 的值,它等于data_start + datasize + bss_size,也即内核模块的末段。
整个高速缓冲区被划分成1024 字节大小的缓冲块,正好与块设备上的磁盘逻辑块大小相同。高速缓冲采用hash 表和空闲缓冲块队列进行操作管理。在缓冲区初始化过程中,从缓冲区的两端开始,同时分别设置缓冲块头结构和划分出对应的缓冲块。缓冲区的高端被划分成一个个1024 字节的缓冲块,低端则分别建立起对应各缓冲块的缓冲头结构buffer_head(include/linux/fs.h,68 行),用于描述对应缓冲块的属性和把所有缓冲头连接成链表。直到它们之间已经不能再划分出缓冲块为止,见图9-10 所示。而各个buffer_head 被链接成一个空闲缓冲块双向链表结构。详细结构见图9-11 所示。
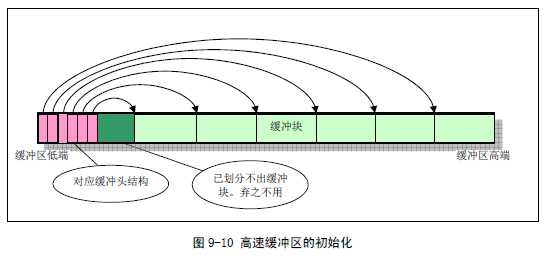
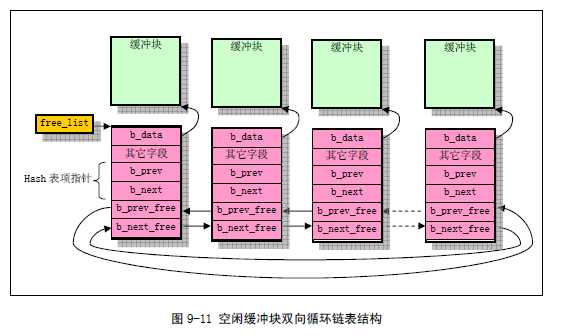
缓冲区的大致结构可参照buffer.c的buffer_init函数:
extern int end; // 由连接程序ld 生成的表明程序末端的变量。[??]
struct buffer_head *start_buffer = (struct buffer_head *) &end;
struct buffer_head *hash_table[NR_HASH]; // NR_HASH = 307 项。
static struct buffer_head *free_list;
//// 缓冲区初始化函数。
// 参数buffer_end 是指定的缓冲区内存的末端。对于系统有16MB 内存,则缓冲区末端设置为4MB。
// 对于系统有8MB 内存,缓冲区末端设置为2MB。
void
buffer_init (long buffer_end)
{
struct buffer_head *h = start_buffer;
void *b;
int i;
// 如果缓冲区高端等于1Mb,则由于从640KB-1MB 被显示内存和BIOS 占用,因此实际可用缓冲区内存
// 高端应该是640KB。否则内存高端一定大于1MB。
if (buffer_end == 1 << 20)
b = (void *) (640 * 1024);
else
b = (void *) buffer_end;
// 这段代码用于初始化缓冲区,建立空闲缓冲区环链表,并获取系统中缓冲块的数目。
// 操作的过程是从缓冲区高端开始划分1K 大小的缓冲块,与此同时在缓冲区低端建立描述该缓冲块
// 的结构buffer_head,并将这些buffer_head 组成双向链表。
// h 是指向缓冲头结构的指针,而h+1 是指向内存地址连续的下一个缓冲头地址,也可以说是指向h
// 缓冲头的末端外。为了保证有足够长度的内存来存储一个缓冲头结构,需要b 所指向的内存块
// 地址 >= h 缓冲头的末端,也即要>=h+1。
while ((b -= BLOCK_SIZE) >= ((void *) (h + 1)))
{
h->b_dev = 0; // 使用该缓冲区的设备号。
h->b_dirt = 0; // 脏标志,也即缓冲区修改标志。
h->b_count = 0; // 该缓冲区引用计数。
h->b_lock = 0; // 缓冲区锁定标志。
h->b_uptodate = 0; // 缓冲区更新标志(或称数据有效标志)。
h->b_wait = NULL; // 指向等待该缓冲区解锁的进程。
h->b_next = NULL; // 指向具有相同hash 值的下一个缓冲头。
h->b_prev = NULL; // 指向具有相同hash 值的前一个缓冲头。
h->b_data = (char *) b; // 指向对应缓冲区数据块(1024 字节)。
h->b_prev_free = h - 1; // 指向链表中前一项。
h->b_next_free = h + 1; // 指向链表中下一项。
h++; // h 指向下一新缓冲头位置。
NR_BUFFERS++; // 缓冲区块数累加。
if (b == (void *) 0x100000) // 如果地址b 递减到等于1MB,则跳过384KB,
b = (void *) 0xA0000; // 让b 指向地址0xA0000(640KB)处。
}
h--; // 让h 指向最后一个有效缓冲头。
free_list = start_buffer; // 让空闲链表头指向头一个缓冲区头。
free_list->b_prev_free = h; // 链表头的b_prev_free 指向前一项(即最后一项)。
h->b_next_free = free_list; // h 的下一项指针指向第一项,形成一个环链。
// 初始化hash 表(哈希表、散列表),置表中所有的指针为NULL。
for (i = 0; i < NR_HASH; i++)
hash_table[i] = NULL;
}
根据上面的理论知识,这段代码很好分析,就不多做解释了。
标签:
原文地址:http://www.cnblogs.com/joey-hua/p/5662070.html