标签:
什么是xml,什么是excel?她们两种都是一种文件格式,属于文本文件。计算机里面要存放数据,一般都是存放在文件中,有些是文本文件,有些是二进制文件,比如图片是二进制文件,你用文本编辑器打开会看到乱码,而一些文件打开,你大致读得懂就是文本文件。数据库存放的数据底层也是存放在文件里面。
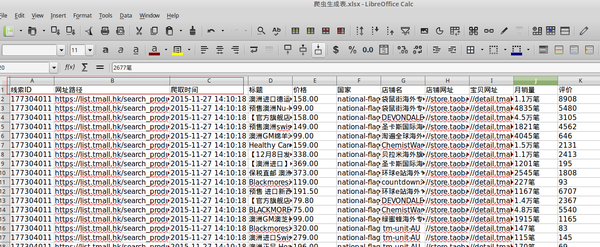
为什么要将数据导入到excel?现在你要提取到excel,就是说你想整理这些数据,因为excel的功能就是简单化数据处理,而不需要手动编程。。。你要提取爱我,才怪,这些你喜欢的标记里面的内容或者属性,便于统计整理。直接在文本编辑器编辑是不可能的,因为你打开xml文件是很难整理的。
如何导入excel?切入正题,来回答乎主的问题。怎么把xml提取到excel?
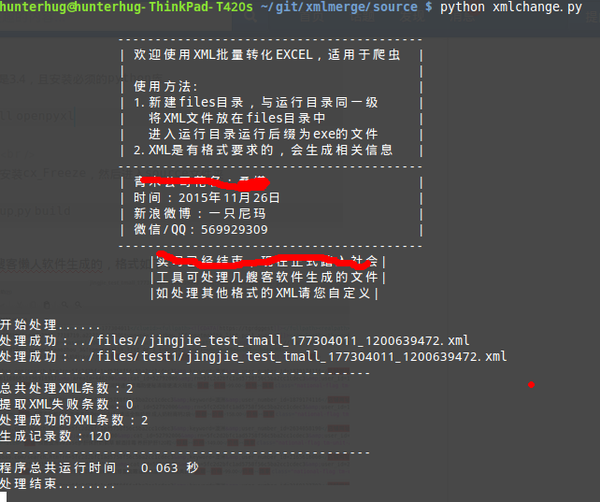
程序演示我已经写好了一个软件,请上github寻找:GitHub - hunterhug/xmlmerge: 及搜客XML合并程序 这个程序已经封装成exe在Windows下可以直接运行。我来演示一下操作。
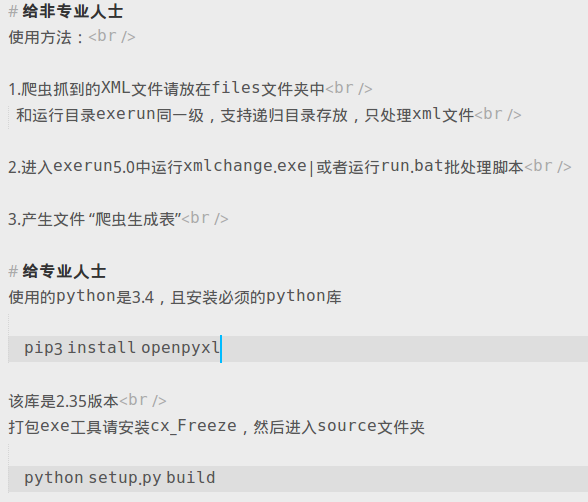
-- exerun5.0 运行目录<br /> -- xmlchange.exe 可执行文件<br /> -- files 需处理的XML(递归子文件夹)<br /> -- jingjie_详情_175894040_1117385545.xml<br /> -- jingjie_详情_175894040_111738554f.xml<br /> -- jingjie_详情_1758940s_1117385545.xml<br /> -- source 源程序<br /> -- xmlchange.py 源代码<br /> -- setup.py 打包配置<br /> --run.bat 批处理运行脚本 -- data 演示数据<br />
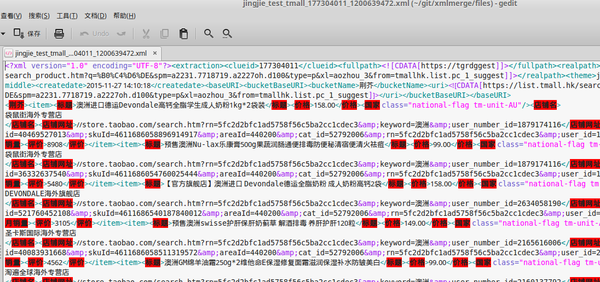
<?xml version="1.0" encoding="UTF-8"?> <root> <clueid>177304011</clueid> <createdate>2015-11-27 14:10:33</createdate> <uri><![CDATA[https://list.tmall.hk/search_product.htm?cat=52792006&s=60&q=%B0%C4%D6%DE&sort=s&style=g&auction_tag=13186;&from=tmallhk.list.pc_1_suggest&suggest=0_3&spm=a2231.7718719.a2227oh.d100&tmhkmain=1&type=pc#J_Filter]]></uri> <item><标题>澳洲直邮 悉尼发货 Woolworths 全脂高钙成人奶粉 1kg</标题></item> <item><标题>澳洲直邮 悉尼发货 Woolworths 全脂高钙成人奶粉 1kg</标题></item> <item><标题>澳洲直邮 悉尼发货 Woolworths 全脂高钙成人奶粉 1kg</标题></item> </root>
源代码展示
# -*- coding:utf-8 -*- # https://docs.python.org/2/library/xml.dom.html#dom-nodelist-objects import xml.dom.minidom import os.path import time from openpyxl import Workbook start = time.clock() wb=Workbook() # sheet=wb.create_sheet(0,‘爬虫抓取表‘) sheet=wb.create_sheet(‘爬虫抓取表‘,0) # 2.3.5 i = 1 def get_xmlnode(node,name): return node.getElementsByTagName(name) if node else [] def files(rootdir): file = [] for parent,dirnames,filenames in os.walk(rootdir): for filename in filenames: if filename.endswith(‘.xml‘): file.append((parent+‘/‘+filename).replace(‘\\‘,‘/‘)) return file def writedata(i,j,item): if i == 1: try: sheet.cell(row = i,column= j).value = item.tagName sheet.cell(row = i+1,column= j).value = item.firstChild.data.strip() except: sheet.cell(row = i,column= j).value = item.tagName attrtext = [] for key in item.attributes.keys(): attrvalue = item.attributes[key] attrtext.append(attrvalue.value) sheet.cell(row = i+1,column= j).value = ‘,‘.join(attrtext) else: try: sheet.cell(row = i+1,column= j).value = item.firstChild.data.strip() except: attrtext = [] for key in item.attributes.keys(): attrvalue = item.attributes[key] attrtext.append(attrvalue.value) sheet.cell(row = i+1,column= j).value = ‘,‘.join(attrtext) def curitem(nodelist,v1,v2,v3,tag=‘item‘): if nodelist: for node in nodelist: nodelist2 = node.getElementsByTagName(tag) if node else [] islast = curitem(nodelist2,v1,v2,v3) if islast==1: items = node.childNodes j=4 for item in items: global i writedata(i,j,item) j=j+1 sheet.cell(row=i+1,column=1).value = v1 sheet.cell(row=i+1,column=2).value = v2 sheet.cell(row=i+1,column=3).value = v3 i=i+1 return 2 else: return 1 def begin(): sangjin = ‘‘‘ ‘‘‘ print(sangjin) begin() print("开始处理......") path = ‘../爬虫生成表.xlsx‘ xmls = files(‘../files/‘) erpath = [] en = 0 #错误数 sheet.cell(row=1,column=1).value = ‘线索ID‘ sheet.cell(row=1,column=2).value = ‘网址路径‘ sheet.cell(row=1,column=3).value = ‘爬取时间‘ for filename in xmls: try: doc =xml.dom.minidom.parse(filename) root = doc.documentElement noderoot = get_xmlnode(root,‘item‘) clueid = get_xmlnode(root,‘clueid‘) v1=clueid[0].childNodes[0].data clueid1 = get_xmlnode(root,‘uri‘) v2=clueid1[0].childNodes[0].data clueid2 = get_xmlnode(root,‘createdate‘) v3=clueid2[0].childNodes[0].data curitem(noderoot,v1,v2,v3) print("处理成功:"+filename) except Exception as e: #raise en = en+1 erpath.append(filename+"\n"+str(e)) pass wb.save(path) total = len(xmls) if erpath: print("-"*50) print("提取失败的文件:") print(‘\n‘.join(erpath)) print("-"*50) print(‘总共处理XML条数:‘+str(total)) print(‘提取XML失败条数:‘+str(en)) print(‘处理成功的XML条数:‘+str(total-en)) print(‘生成记录数:‘+str(i-1)) print("-"*50) end = time.clock() print("程序总共运行时间 : %.03f 秒" %(end-start)) print("处理结束........") input() 只使用了xml和excel的库: import xml.dom.minidom from openpyxl import Workbook 代码使用递归形式解析,很短很短,看看就知道了: doc =xml.dom.minidom.parse(filename) root = doc.documentElement noderoot = get_xmlnode(root,‘item‘) clueid = get_xmlnode(root,‘clueid‘) v1=clueid[0].childNodes[0].data clueid1 = get_xmlnode(root,‘uri‘) v2=clueid1[0].childNodes[0].data clueid2 = get_xmlnode(root,‘createdate‘) v3=clueid2[0].childNodes[0].data curitem(noderoot,v1,v2,v3) print("处理成功:"+filename)
# -*- coding:utf-8 -*- import urllib.request, urllib.parse, http.cookiejar import os import random import re # 代理ip函数 # 183.239.167.122:8080 # 返回[[‘179.176.37:8080‘, ‘179.146.153:8080‘, ‘179.198.37:8080‘, ‘234.45.50:3128‘, ‘255.53.81:80‘, ‘22.195.148:80‘] def daili(): geshi=re.compile(r‘(.*)@(.*)‘) file =open(‘daili.txt‘,‘rb‘) data=file.read().decode(‘utf-8‘,‘ignore‘).split(‘\n‘) location=[] #random.shuffle(data) # ip数组打乱 for i in range(0,len(data)): temp=geshi.match(data[i]).group(1).split(‘.‘) location.append(geshi.match(data[i]).group(2)) data[i]=‘.‘.join([temp[1],temp[2],temp[3]]) file.close() file =open(‘daili1.txt‘,‘w‘) file.write(‘\n‘.join(data)) file.close() return data # 万能抓取函数 def getHtml(url,daili=‘‘,postdata={}): """ 抓取网页:支持cookie 第一个参数为网址,第二个为POST的数据 """ # COOKIE文件保存路径 filename = ‘cookie.txt‘ # 声明一个MozillaCookieJar对象实例保存在文件中 cj = http.cookiejar.MozillaCookieJar(filename) # cj =http.cookiejar.LWPCookieJar(filename) # 从文件中读取cookie内容到变量 # ignore_discard的意思是即使cookies将被丢弃也将它保存下来 # ignore_expires的意思是如果在该文件中 cookies已经存在,则覆盖原文件写 # 如果存在,则读取主要COOKIE if os.path.exists(filename): cj.load(filename, ignore_discard=True, ignore_expires=True) # 建造带有COOKIE处理器的打开专家 proxy_support = urllib.request.ProxyHandler({‘http‘:‘http://‘+daili}) # 开启代理支持 if daili: print(‘代理:‘+daili+‘启动‘) opener = urllib.request.build_opener(proxy_support, urllib.request.HTTPCookieProcessor(cj), urllib.request.HTTPHandler) else: opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) # 打开专家加头部 opener.addheaders = [(‘User-Agent‘, ‘Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5‘), (‘Referer‘, ‘http://s.m.taobao.com‘), (‘Host‘, ‘h5.m.taobao.com‘)] # 分配专家 urllib.request.install_opener(opener) # 有数据需要POST if postdata: # 数据URL编码 postdata = urllib.parse.urlencode(postdata) # 抓取网页 html_bytes = urllib.request.urlopen(url, postdata.encode()).read() else: html_bytes = urllib.request.urlopen(url).read() # 保存COOKIE到文件中 cj.save(ignore_discard=True, ignore_expires=True) return html_bytes if __name__ == ‘__main__‘: url=‘http://www.baidu.com‘ a=getHtml(url,‘‘,{}) b=getHtml(url) print(a.decode(‘utf-8‘,‘ignore‘)) print(b.decode(‘utf-8‘,‘ignore‘)) data=daili() print(data) c=getHtml(url,data[0],{}) print(c.decode(‘utf-8‘,‘ignore‘))
1.179.176.37:8080@HTTP#泰国 TOT公共有限公司 1.179.146.153:8080@HTTP#泰国 TOT公共有限公司 1.179.198.37:8080@HTTP#泰国 TOT公共有限公司 1.234.45.50:3128@HTTP#韩国 SK电讯 1.255.53.81:80@HTTP#韩国 SK电讯 5.22.195.148:80@HTTP#【匿】伊朗 5.135.161.61:3128@HTTP#法国 5.141.9.86:8080@HTTP#俄罗斯 5.160.247.16:8080@HTTP#伊朗
标签:
原文地址:http://www.cnblogs.com/nima/p/5663057.html