标签:
随着移动互联网时代的到来,移动技术也随之飞速发展。如今,App已然成为绝大多数互联网企业用来获取用户的核心渠道。以往以PC为主要承载平台的各业务线,源源不断集成加入到移动项目中来,原本以产品为中心快速迭代的单一开发模式,已经无法应对这汹涌爆炸式的业务接入和高速增长。同时伴随着用户量的增长,流量的持续暴增,系统架构面临的一系列挑战和转型。怎么构建出高可靠、高扩展、低成本、多快好省系统体系架构已成为业界乐而不厌的长谈话题。
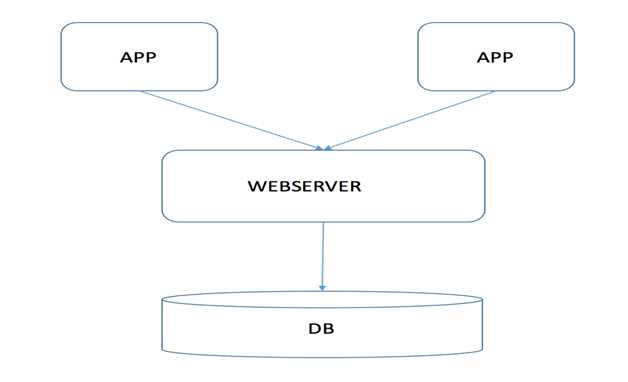
2010年移动端刚刚兴起,公司组建了移动团队(刚开始就几个人)带领着一家外包公司做了第一版。当时业务十分简单,即把PC端的论坛文章等直接搬App端进行展示,服务端也是ALL IN ONE的结构,也没有架构的概念(如图1),虽然系统耦合严重、但流量低也不见明显的问题。
2013年公司上市,业务扩展,移动端流量开始增长,特别是2014年。
2014年末流量较年初增长了2.5倍。而原来的这种ALL-IN-ONE体系结构的弊端日益凸显,服务端经常由于高峰期的访问压力宕机。这种高耦合的结构常常由于某一个接口的超限流量导致其他接口也不能正常访问。
而随着业务的不断扩张,应用的不断迭代导致应用的体积不断增大,项目越来越臃肿,冗余增加,维护成本水涨船高……老架构力不从心。
面对日益严重的服务压力,公司开始组建自己的移动研发团队(C#+SQL Sever),服务端程序进行了第一次重构。
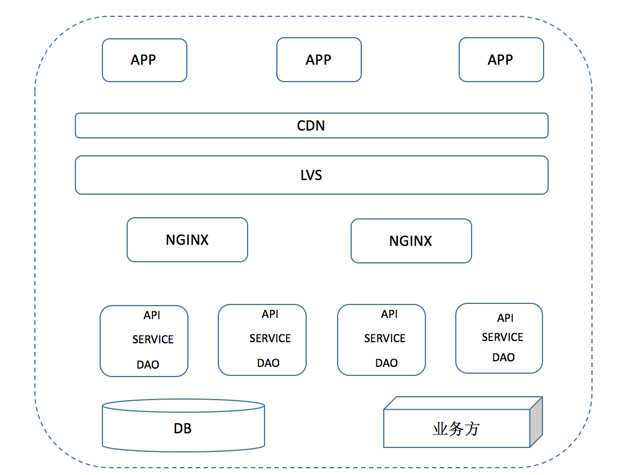
服务端程序进行对应用分层(接口层API、业务逻辑层Service、数据访问层DAO)、分割(根据App端的各个模块把原来的ALL-IN-ONE的结构分割成不同服务)、做动静分离CDN加速、读写分离、集群负载。同时公司运维部根据我们的业务特点研发自己的CDN服务、二级缓存SCS服务对应用做进一步加速,经过这次改造,暂时缓解了服务端的压力。
我2015年初加入汽车之家,当时移动端面临的问题如下:
请求量更大,应该说是流量暴增的时代:2015年9月,汽车之家移动端日均独立用户总访问量较2014年9月同比增加约73.0%。2016年初移动端PV实现亿级。
依赖资源多: 依赖Redis、DB、RPC、HTTP、MongDB、MQ、数十个业务。
垂直业务耦合严重:如帖子、文章最终页和评论系统这种垂直耦合业务常常出现评论系统挂掉导致帖子或文章最终不能访问的情况。
运营推广活动多:为了增加用户粘度,提高用户活跃度,各个业务方和我们自己的运营推广活动大量增加。
发版快:每月固定两次发版,多版本并存。
微软技术体系:微软收费服务都需要大把白花花的银子,且高质量的.NET工程师越来越难招,生态圈不太景气。
为了应对流量的暴涨,服务的高可用性和团队变大,所有开发人员集中针对同一个系统的严重冲突,App端进行插件化改造。服务端2015年初也开始了二次重构计划,进行了一次脱胎换骨的转型,全面拥抱Java,主要的技术改变有:
Windows→Linux、SQL Server→MySQL、IIS→Tomcat、C#→Java。
需求方面主要有这几点:文章、帖子的评论这种垂直业务不能挂掉;业务爆发能够快速实现;依赖(多业务方、多资源)解耦,故障时绝对不允许相互影响。
解决方案分为以下几步:
分解。首先是团队:根据App插件化的划分,对服务端团队研发人员进行分组,各小组只负责自己的模块,每月固定的两次迭代,各小组服务独立上线互不影响。其次是服务结构,包括水平扩展:多集群、多机房部署提高并发能力和容灾能力;垂直拆分:垂直业务进一步拆分,依赖解耦;业务分片:按功能特点分开部署,如活动、秒杀、推送等物理隔离;水平拆分:服务分层,功能和非功能分开,基础核心服务非核心服务分开。
业务服务化,相互独立,如咨询、论坛、广告等。
无状态设计。调用链路无单点、无状态服务,可线性扩容(尽可能不要把状态数据保存到本机、接口调用做到幂等性)。
可复用。复用的粒度是业务逻辑的抽象服务,不是服务实现的细节、服务引用只依赖服务抽象。
资源分层。Redis、DB、MQ 主从设计,多机房部署、保障高可用。
松耦合、自保护、防雪崩。跨业务调用尽可能异步解耦,必须同步调用时设置超时、队列大小、线程池大小、相对稳定的基础服务与易变流程的服务分层;线程池保护,超出服务器最大线程时DROP请求(Nginx、Tomcat)。Redis、DB、MQ、Turbo(RPC)、HttpClient等在后端资源出问题时可以自动降级请求调用、发送异常报警。
服务隔离可自理。服务可降级、可限流、可开关、可监控、白名单机制。
各个服务独立部署互不影响,服务异常自动熔断,根据各个服务特点走相应的降级策略。基础服务下沉可复用基础服务自治、相互独立、基础服务要求尽量精简可水平扩展、物理隔离保证稳定(如用户中心、产品库)。
分清核心业务。核心业务服务尽量精简,利于稳定(运行时优先保证主流程顺利完成、辅助流程采用异步:如日志上报)。
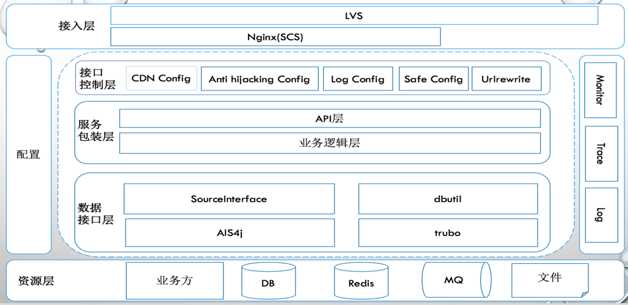
App端请求经过接入层(CDN、LVS、NG/SCS),通过接口控制层的设置校验(CDN配置、反劫持配置、日志服务配置、安全校验……)调用API层发布的REST接口,通过参数校验后调用业务逻辑层的业务实现。同时业务逻辑层通过数据接口层(SourceInterface源接口服务、DbUtils数据库分开分表组件、AIS4J异步请求组件、Trubo RPC服务)调用资源层的资源服务来完成本次业务的数据组装,完成本次业务的调用。
配置方面,一个基于zookeeper的配置服务(配置服务用于系统的各种开关的实时配置如:源接口的限流熔断阈值等);Monitor:监控服务实时查看系统异常、流量;Trace:系统跟踪服务;Log:(日志服务)。
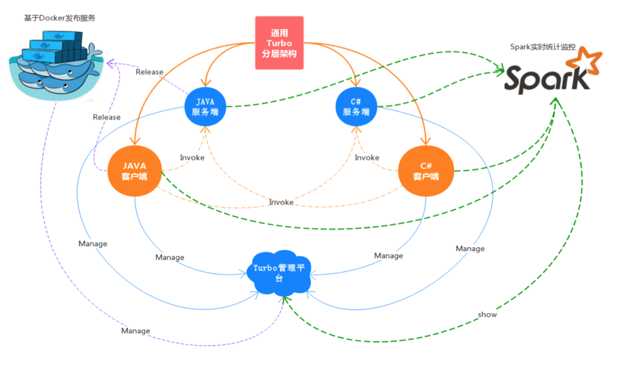
为了应对服务化作服务自理,2015年底我们全面启用公司的RPC服务Trubo
框架特点主要有:多语言服务端发布,支持C#和Java;高效透明的RPC调用,多协议支持;基于ZooKeeper的注册中心,用于服务发现;客户端软负载和容错机制;使用Spark进行服务监控与跟踪Trace分析;整合Locker(Docker调度平台),实现服务部署自动化。
服务发现与RPC稳定性和容错方面,主要是双机房部署ZooKeeper集群,主力机房5个节点(Leader/Follower集群),其他机房2个节点(Observer节点),保证性能和稳定性;Trubo客户端服务端添加守护线程,定时校验本地缓存和ZooKeeper的数据一致性;Trubo客户端会将缓存的服务信息持久化到本地,即使ZooKeeper挂掉或者重启也不影响正常调用;嵌入Trace客户端上报收集分布式跟踪日志。
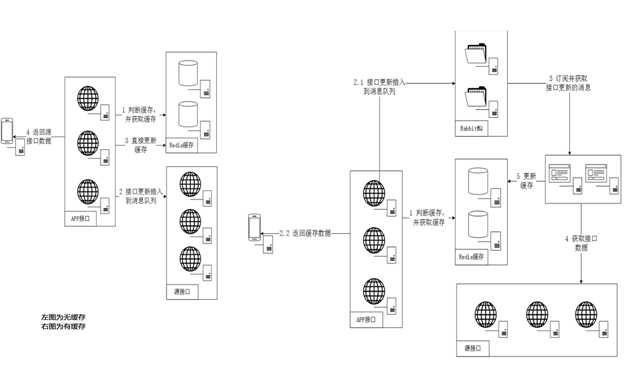
为了解决接口和资源依赖问题(源站或Redis、DB等资源层挂掉导致我们服务不可用的高风险),同时也为了请求响应时间受到源站依赖问题,我们封装了异步请求组件AIS4J。同时嵌入我们的熔断限流组件来对源站进行解耦。
引入AIS4J后大大缓解了对外部资源的依赖,提高了服务的可用性,但同时也带来了一些问题。公司要求对缓存内容时间限定在10分钟以内,原来的时间被平均分配到了CDN和我们的二级缓存SCS上,现在加入这个组件为了满足10分钟的要求必须把原来的10分钟拆分到AIS4J上,这就需要增大系统接口的回源率(10%左右)。这个时间就要对请求时间和系统压力上做一个权衡。
就目前阶段来说,服务分解封装应对一段时间的流量增长已没太大问题。但为了保证服务的高可用、系统的扩容预估、故障的实时定位……就必须有一套完善的监测报警系统。
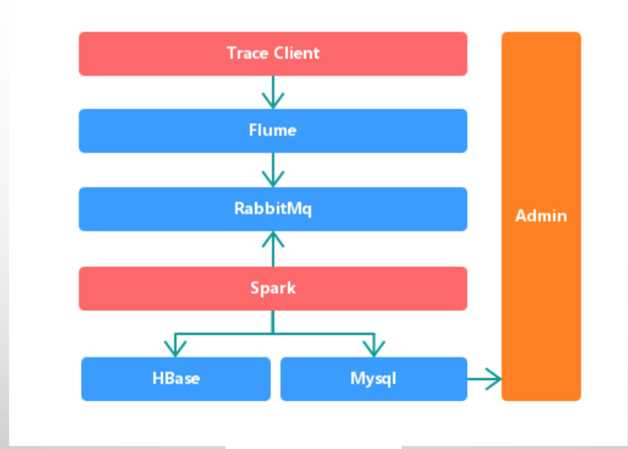
图7是系统调用追踪服务,通过对程序Java的Instrumentation和配置系统对系统程序进行埋点跟踪,再通过Spark对跟踪日志进行实时分析展现。
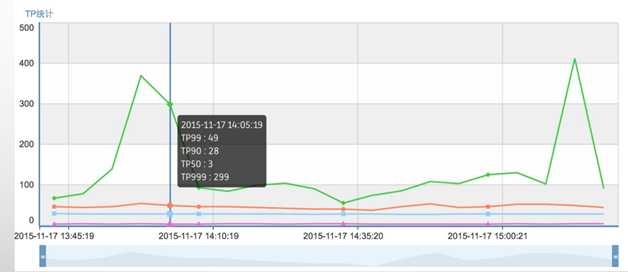
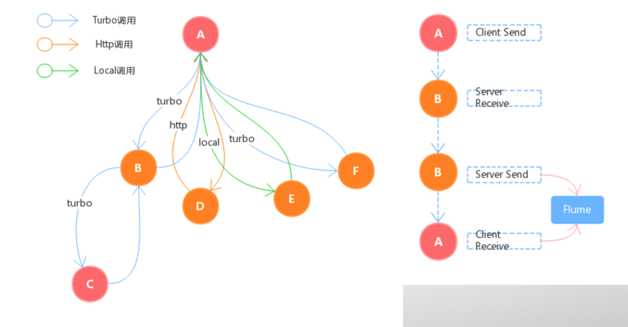
Trace ID标识唯一调用树,Transaction ID标识唯一次调用,一次Trace调用会产生四条日志,Trace调用树可以由Turbo、本地调用、HTTP或其他调用方式组成,Trace客户端是独立的,Turbo单向依赖Trace。
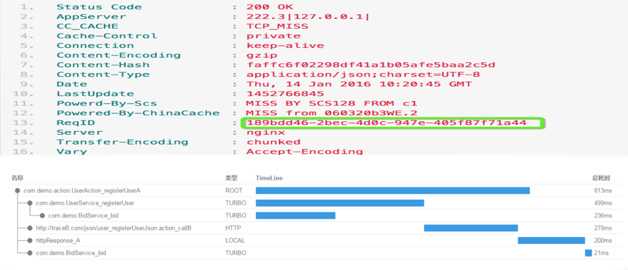
同时我们在APP端的请求头中埋入Req ID,通过Req ID和Trace ID的对接记录一次请求过程(CDN、SCS、后端服务、RPC/HttpClient调用)每一步的时间消耗。
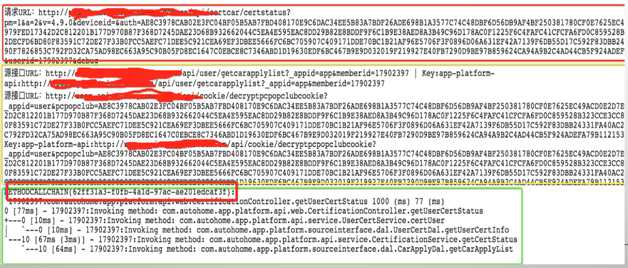
为了更快的定位稳定,我们在程序中预设了Debug模式,在内网环境中只要拿到请求的URL开启Debug模式就可以快速的调出系统调用资源链和每一步的程序调用消耗时间。
通过Spark对日志记录的分析结果,会实时对接到我们的报警系统上,实现对程序异常的实时报警。报警系统通过短信、邮件方式发生,内容中包含请求的Trace ID超链到报表系统实现对异常问题的实时查看定位。
标签:
原文地址:http://www.cnblogs.com/WeiGe/p/5664390.html