标签:
1. 蒙特卡洛估计
若$\theta$是要估计的参数,$y_{1},...,y_{n}$是从分布$p(y_{1},...,y_{n}|\theta) $中采样的样本值,假定我们从后验分布$p(\theta|y_{1},...,y_{n})$中独立随机采样$S$个$\theta$值,则$$ \theta^{(1)},...,\theta^{(S)}\sim^{i.i.d.}p(\theta|y_{1},...,y_{n}) $$
那么我们就能够通过样本$\{\theta^{(1)},...,\theta^{(S)}\} $对$p(\theta|y_{1},...,y_{n}) $进行估计,且随着$S$增加,估计精度也会提高。样本$\{\theta^{(1)},...,\theta^{(S)}\} $的经验分布就被称为$p(\theta|y_{1},...,y_{n}) $的$Monte\;Carlo $估计。
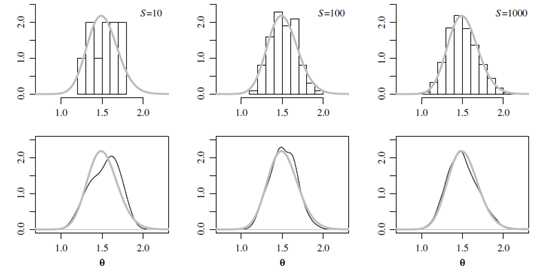
另外,令$g(\theta) $为任意函数,根据大数定理,如果$\theta^{(1)},...,\theta^{(S)} $是从$p(\theta|y_{1},...,y_{n}) $中独立同分布采样的,那么有:$$ \frac{1}{S}\sum_{s=1}^Sg(\theta^{(s)})\rightarrow E[g(\theta)|y_{1},...,y_{n}]=\int g(\theta)p(\theta|y_{1},...,y_{n})d\theta \; as\;S\rightarrow \infty $$
当$S\rightarrow \infty $,
|
$\bar{\theta}=\sum_{s=1}^S \theta^{(s)}/S\rightarrow E[\theta|y_{1},...,y_{n}] $ $\sum_{s=1}{S}(\theta^{(s)}-\bar{\theta})^2/(S-1)\rightarrow Var[\theta|y_{1},...,y_{n}] $ $\#(\theta^{(s)}\leq c)/S\rightarrow Pr(\theta\leq c|y_{1},...,y_{n}) $ $the\;empirical\;of\;\{\theta^{(1)},...,\theta^{(S)}\}\rightarrow p(\theta|y_{1},...,y_{n})$ $the\; median\; of\; \{\theta^{(1)},...,\theta^{(S)}\}\rightarrow \theta_{1/2} $ $the\;\alpha-percentile\;of\;\{\theta^{(1)},...,\theta^{(S)}\}\rightarrow \theta_{\alpha} $ |
2. Gibbs采样
$Monto Carlo $方法是通过产生伪随机数,使之服从一个概率分布$\pi(X) $。当$X$是一维的情况下,这很容易做到,但当$X\in R^k $,往往要么样本不独立,要么不符合$\pi$。解决该问题目前最常用的是$MCMC $方法,其样本的产生与马氏链有关。基于条件分布的迭代采样是另外一种重要的$MCMC $方法,最著名的就是$Gibbs $采样。
已知$p(\theta|\sigma^2,y_{1},...,y_{n}) $和$p(\sigma^2|\theta,y_{1},...,y_{n}) $分别是$\theta $和$\sigma^2$的全条件分布,给定当前参数$\phi^{(s)}=\{\theta^{(s)},\tilde{\sigma}^{2(s)}\} $,我们按下列方式生成新参数:
|
1. $sample\;\theta^{(s+1)}\sim p(\theta|\tilde{\sigma}^{2(s)},y_{1},...,y_{n}) $ 2. $sample\;\tilde{\sigma}^{2(s+1)}\sim p(\tilde{\sigma}^2|\theta^{(s+1)},y_{1},...,y_{n}) $ 3. $let\;\phi^{(s+1)}=\{\theta^{(s+1)},\tilde{\sigma}^{2(s+1)}\} $ |
最终生成一个相关马氏序列$\{\phi^{(1)},\phi^{(2)},...,\phi^{(S)}\} $。
3 Methopolis-Hastings算法
当先验分布是共轭或是半共轭的时候,后验分布可以用$Monte\; Carlo $方法或是$Gibbs$采样的方法进行估计。但当先验分布不能采用共轭分布的时候,参数的全条件分布就没有标准形式,因此很难采用$Gibbs$采样进行估计。$Methopolis-Hastings $算法作为一种一般的后验概率估计算法,可以用于任何先验分布和采样模型。
让我们考虑一般的情况,我们的采样模型为$Y\sim p(y|\theta) $,先验分布为$p(\theta) $,虽然对大多数问题来说,我们可以用$p(\theta|y)=p(\theta)p(y|\theta)/\int p(\theta‘)p(y|\theta‘)d\theta‘ $来计算$p(\theta|y) $,但是通常情况下,积分是很难算的。如果我们能够从$p(\theta|y) $中采样$\theta^{(1)},...,\theta^{(S)}\sim^{i.i.d.} p(\theta|y) $,那么就可以采用$Monte\; Carlo $方法来估计后验,使得$$ E[g(\theta)|y]\approx \frac{1}{S}\sum_{s=1}^S g(\theta^{(s)}) $$
但是如果我们不能够直接从$p(\theta|y) $中采样呢?其实在估计后验分布的过程中,最重要的事情不是从$p(\theta|y) $中获取独立同分布的样本,而是要构造一个很大的数据集使得对于任何两个不同的参数来说有$$ \frac{\#\{\theta^{(s)}\;in\;the\;collection\;=\;\theta_{a}\}}{\#\{\theta^{(s)}\;in\;the\;collection\;=\;\theta_{b}\}}\approx \frac{p(\theta_{a}|y)}{p(\theta_{b}|y)} $$
假定现在的工作集合是$\{\theta^{(1)},...,\theta^{(s)}\} $,我们考虑是否将新参数$\theta^{(s+1)} $加到该集合当中。基本思路是:$$ r=\frac{p(\theta^*|y)}{p(\theta^{(s)|y})}=\frac{p(y|\theta^*)p(\theta^*)}{p(y)}\frac{p(y)}{p(y|\theta^{(s)})p(\theta^{(s)})}=\frac{p(y|\theta^*)p(\theta^*)}{p(y|\theta^{(s)})p(\theta^{(s)})} $$
如果$r>1 $,因为$\theta^{(s)} $已经在我们的数据集当中,由于$\theta^* $拥有更高的概率,我们应该接受$\theta^* $到我们的数据集当中,即$\theta^{(s+1)}=\theta^* $。
如果$r<1 $,我们以$r$或$1-r$的概率来接受$\theta^* $或$\theta^{(s)} $。
我们在抽取$\theta^* $时要服从对称分布$J(\theta^*|\theta^{(s)}) $,即$J(\theta_{b}|\theta_{a})=J(\theta_{a}|\theta_{b}) $,通常很好选取,如$J(\theta^*|\theta^{(s)}) = normal(\theta^{(s)},\sigma^2)$
综上,$Methopolis $算法如下
|
$Methopolis-Hastings $算法如下:
利用该算法估计$p_{0}(u,v) $
|
1. 更新$U$ a) 采样$u^*\sim J_{u}(u|u^{(s)},v^{(s)}) $ b) 计算接受率$$r=\frac{p_{0}(u^*,v^{(s)})}{p_{0}(u^{(s)},v^{(s)})}\times \frac{J_{u}(u^{(s)}|u^*,v^{(s)})}{J_{u}(u^*|u^{(s)},v^{(s)})} $$ c) 以$\min(1,r) $和$\max(0,1-r) $的概率将$u^{(s+1)} $设为$u^* $和$u^{(s)} $ 2. 更新$V$ a) 采样$v^*\sim J_{v}(v|u^{(s+1)},v^{(s)}) $ b) 计算接受率$$r=\frac{p_{0}(u^{(s+1)},v^*)}{p_{0}(u^{(s+1)},v^{(s)})}\times \frac{J_{v}(v^{(s)}|u^{(s+1)},v^* )}{J_{v}(v^*|v^{(s+1)},v^{(s)})} $$ c) 以$\min(1,r) $和$\max(0,1-r) $的概率将$v^{(s+1)} $设为$v^* $和$v^{(s)} $ |
$Methopolis $算法是$Methopolis-Hastings $算法的一种特殊形式,$Gibbs $抽样算法也是$Methopolis-Hastings $算法。
参考文献:Hoff, Peter D. A first course in Bayesian statistical methods. Springer Science & Business Media, 2009.
标签:
原文地址:http://www.cnblogs.com/huangxiao2015/p/5665101.html