标签:
#include<stdio.h> int main() { if(2 > 0) { int i = 0; } printf("i = %d", i); return 0; }
在这段代码中,if子句引入了一个局部作用域,变量i就存在于这个局部作用域中,但对外不可见,因此,接下来在printf函数中对变量i的引用会引发编译错误,但是在python中并非如此
看下面代码:
if 1 == 1: name = ‘fuzj‘ print(name)
在这段代码中,if子句并没有引入一个局部作用域,变量i仍然处在全局作用域中,因此,变量i对于接下来的print语句是可见的
所以,python无块级作用域。
代码:
def f1(): name = ‘fuzj‘ print(name) #打印报错
函数f1已经将name的变量作用域隔离,所以在函数外print的时候会提示找不到name变量
name = ‘fuzj‘ def f1(): name = ‘jie‘ print(name) f1() 输出结果是jie
name = ‘fuzj‘ def f1(): print(name) def f2(): name = ‘jie‘ f1() f2() 输出结果:fuzj name = ‘fuzj‘ def f1(): print(name) def f2(): name = ‘jie‘ return f1 res = f2() res() 输出结果为fuzj
通过上面的例子说明,f1在python解释器解释完之后,其作用域已经确认,作用域链也确认,同样f2函数也已经确认,所以后面执行的时候,哪个函数被调用就执行那个函数,从而查找之前已经定义好的作用域
吊炸天的案例
>>> li = [x+1 for x in range(10)] #特殊语法,for后面循环生成了列表的元素,最终组成了一个列表,此时for循环10以内的数,并让每个x加1,最后组成li的列表 >>> print(li) [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> li = [x+1 for x in range(10) if x>7] #增加判断条件,x大于7的才加1 >>> print(li) [9, 10]
理解了上面的铺垫,请看下面案例
>>> li = [lambda :x for x in range(10)] >>> print(li) [<function <listcomp>.<lambda> at 0x101bdbae8>, <function <listcomp>.<lambda> at 0x101bdbb70>, <function <listcomp>.<lambda> at 0x101bdbbf8>, <function <listcomp>.<lambda> at 0x101bdbc80>, <function <listcomp>.<lambda> at 0x101bdbd08>, <function <listcomp>.<lambda> at 0x101bdbd90>, <function <listcomp>.<lambda> at 0x101bdbe18>, <function <listcomp>.<lambda> at 0x101bdbea0>, <function <listcomp>.<lambda> at 0x101bdbf28>, <function <listcomp>.<lambda> at 0x101bec048>] >>> print(li[0]) <function <listcomp>.<lambda> at 0x101bdbae8> >>> print(li[0]()) 9 >>> print(li[1]()) 9
是否已经懵B?
看下面解释:
python2.7和python3中类有差别,python2.7中将类分给经典类和新式类,python3中全部是新式类,他们在多继承时,类的不同,继承顺序不一样
详情请猛击这里:http://www.cnblogs.com/pycode/p/class.html
无继承其他类便是经典类
class Foo: pass
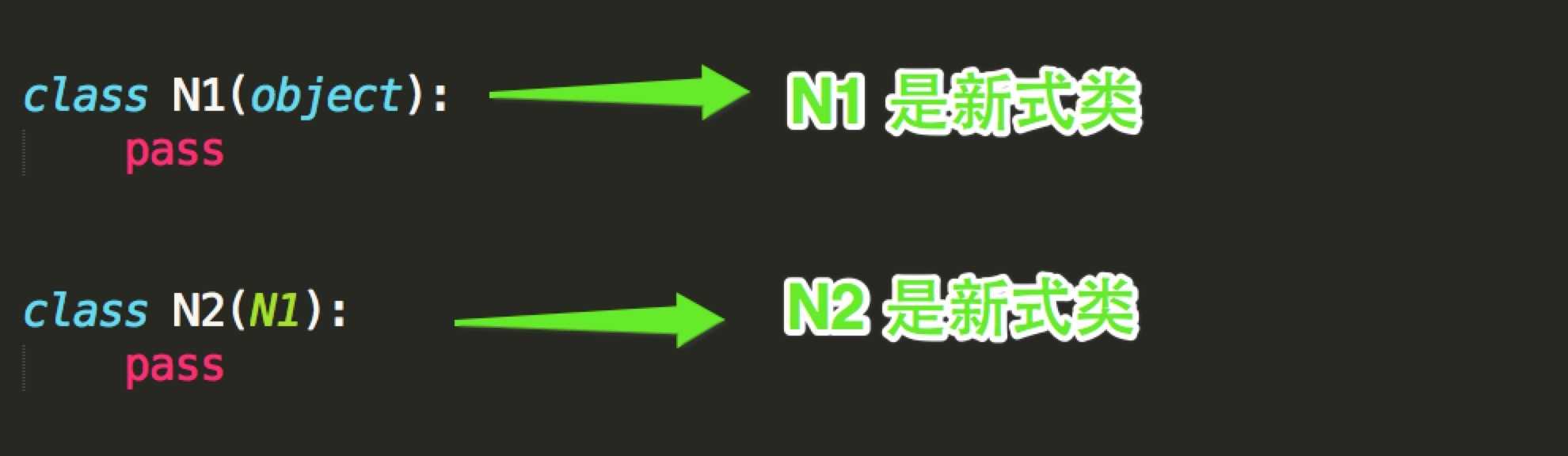
有继承其他父类,或者object类,此类便是新式类
class Foo(object): pass
 ?
?
 ?
?
继承规则
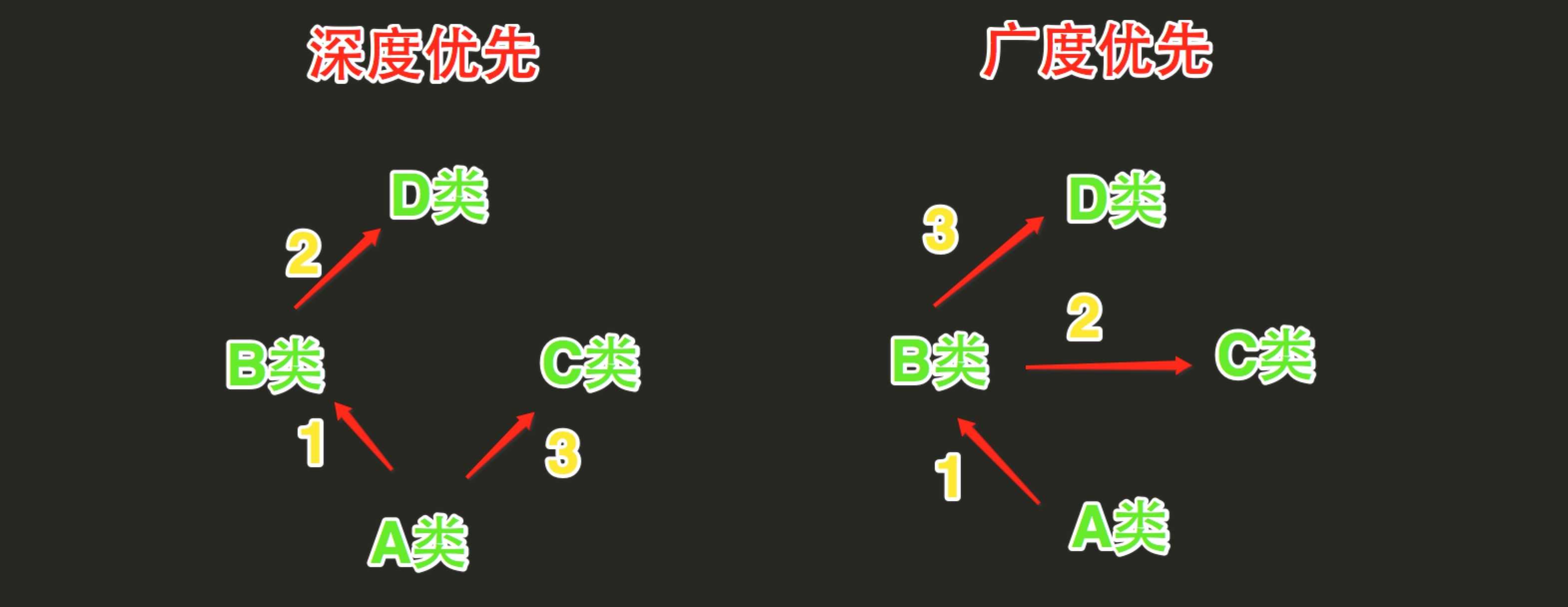
Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先
 ?
?
当类是经典类时,多继承情况下,会按照深度优先方式查找
当类是新式类时,多继承情况下,会按照广度优先方式查找
案例
class D: def f1(self): print("D.f1") class B(D): def f(self): print("B.f1") class C(D): def f1(self): print("C.f1") class A(B, C): def f(self): print("A.f") a = A() a.f1() 输出结果: D.f1 由于class D 是一个经典类,其中B和C都继承D,A继承C和B,ABC是新式类,,所以会根据深度优先的继承规则,所以输出的结果为class D的f1
class D(object): def f1(self): print("D.f1") class B(D): def f(self): print("B.f1") class C(D): def f1(self): print("C.f1") class A(B, C): def f(self): print("A.f") a = A() a.f1() 输出结果: C.f1 由于class D继承了object,所以ABCD都是新式类。按找广度优先的原则最后输出的是C.f1
标签:
原文地址:http://www.cnblogs.com/pycode/p/class3.html