标签:
Flume是一种高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。
可以看一下模型:
每一个flume代理(agent)可以提供一项flume服务。每一个代理有三个成员:source、channel、sink
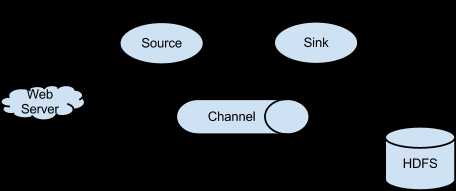
如上图所示,由source获取数据并发送给channel,channel就好比一个缓冲区,由sink来从channel里读取数据。
----------------------------------------------
暂时没有图写个思路先:
模型1:多source---1channel---1sink
模型2:单source---多channel---多sink
-----------------------------------------------
一个JVM环境仅仅只能运行一个agent
but..如果在同一台机器上起多个JVM环境则可以运行多个agent一样的道理。
应用场景的话多数据源接入且要汇入到同一类型sink且地址相同的不同路径下(好吧我语法比较差不知道这句话怎么描述,后续补图)
关于多JVM环境运行的话需要更深入的了解FLUME的配置..后续有时间了解一下。
==========================
关于FLUME的源码,在flume官网上可以下载它的源码包,用哪里读哪里,对配置和使用的帮助很大。
=============================================
关于shell脚本:
if[[ $? -ne 0 ]]
$? :指的是上一条脚本执行的返回结果,如上一条脚本是一条基本的ls -l命令,如果成功查询,当然返回就是0了,可如果出错,返回值不为0。
如果要修改某一文件中的某一个字段,或者某一行或某几行,sed指令会帮上你大忙。
如果要获取路径:那么pwd、dirname这些都是你的好帮手。
脚本里可以将你想要的到的结果直接赋值给变量,好像这样:
hadoop_path=`hadoop fs -ls /path1/path2/path3/path4`
注意这里的``可是数字1左边的键呦。
得到这个path了以后我就可以判断这个path是不是存在了呀呀呀。
活学活用活记。脚本可以干很多事。
====================================
SQL,如果别人写了一条非常长非常长非常绕的SQL命令。
不要觉得看不懂,看不懂放到数据库跑一把,就懂了。不要死死的一行一行盯着看,看半天也不会看出来的。浪费时间。
慢慢写。
标签:
原文地址:http://www.cnblogs.com/wowostudy/p/5679703.html