标签:
摘要:最近要做这个主题的组内分享,所以准备了一个星期,查了比较多的资料。准备的过程虽然很烦很耗时间,不过因为需要查很多的资料,因此整个过程下来,对这方面的知识影响更加深刻。来来来,接下来总结总结
http中具有缓存功能的是:1、浏览器缓存、 2、缓存代理服务器。
http缓存的是指:当Web请求抵达缓存时, 如果本地有“已缓存的”副本,就可以从本地存储设备而 不是从原始服务器中提取这个文档。
1. 减少了冗余的数据传输,节省了网费。
2. 减少了服务器的负担, 大大提高了网站的性能
3. 加快了客户端加载网页的速度。优化用户体验
第一次请求:

第一次请求,无论是静态文件还是其他文件,都是从服务器那里读取的。因此没有缓存之说。等第一次请求完,浏览器就有缓存了,然后整个的加载过程就完全不一样了。看下图:
浏览器再次请求
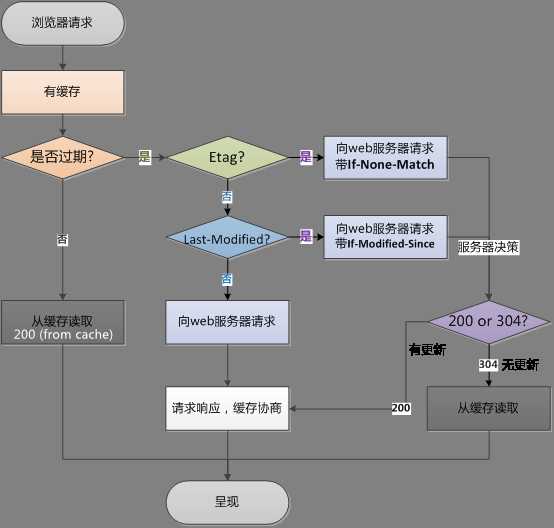
流程图解释:
浏览器再次请求,情况就不一样了。首先会读取缓存,然后判断缓存是否过期,如果不过期,就直接读取缓存。
否则,判断浏览器返回的头部信息是否存在Etag,如果存在,浏览器会像服务器发送带有If-None-Match的请求头,来和服务器返回的Etag做对比,
如果if-None-Match和Etag相等。说明缓存没有更新,服务器返回304,浏览器继续从缓存读取相应的内容。如果if-None-Match和Etag不等,则服务器返回200,浏览器重新需
要从服务器获取内容。
如果服务器的返回信息里面没有Etag,则判断浏览器的返回信息里是否有Last-Modified。如果有,浏览器会像服务器发送一个if-Modified-Since的请求头。然后if-Modified-
Since的值会和Last-Modified的值做对比,如果if-Modified-Since的值大于等于Last-Modified,则服务器返回304,文件没有更新,直接读取缓存即可。如果if-Modified-Since
的值小于Last-Modified。则说明浏览器的缓存不是最新的,需要从服务器重新读取。
如果服务器返回的头部信息既没有Etag,又没有Last-Modified,则缓存已经失效了,重新服务器抓取。
如果第一次接触浏览器缓存的同学,可能会晕掉。说的是什么鬼东西,头都晕了,尼玛。好的,接下来就解释一下上面说的那些概念。
Expires是web服务器 响应消息头字段,在响应http请求时告诉浏览器在过期时间前,浏览器可以直接从浏览器缓存读取数据,而无需再次请求,它的值对应一个GMT(格林尼治时间),比如“Mon, 22 Jul 2012 11:15:08 GMT”来告诉浏览器资源缓存过期时间,如果还没过该时间点则不发请求。
我们可以使用meta标签来告知页面。不过值对ie有效。如下:
<meta http-equiv="expires" content="sun, 19 apr 2016 14:30:00 GMT">
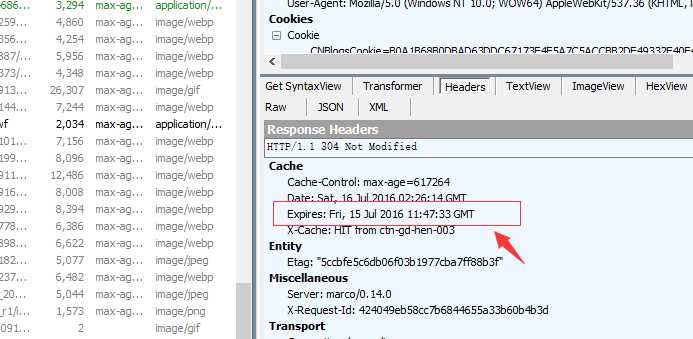
不过Expires是HTTP 1.0的东西。现在浏览器都是默认HTTP 1.1的了。所以基本可以忽略它。Expires有一个缺点,就是它的过期时间是服务器的时间,比如我的客户端时间和服务器时间相差很大,那误差就很大。比如服务器返回的是2016年7月16号过期,我的电脑时间被我修改了,快了一天为2016年7月17号,那客户端缓存就过期了。所以它被Cache-Control:max-age=秒 替代了。
Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据。
只不过Cache-Control的选择更多,设置更细致,如果同时设置的话,其优先级高于Expires。
Cache-Control可拥有如下值:
Public
任何情况下都得缓存该资源。
Private
指示对于单个用户的整个或部分响应消息,不能被共享缓存处理。缓存只开放给某些特定的用户,比如服务器的用户,其他用户则不能缓存这些数据。
no-cache
指示请求或响应消息不能缓存,该选项并不是说可以设置”不缓存“,容易望文生义~。要求向服务器发起新鲜度检验
no-store
用于防止重要的信息被无意的发布。在请求消息中发送将使得请求和响应消息都不使用缓存,完全不存下來。主要用于一些机密文件
max-age
指示客户端该端时间内缓存都是最新的。以秒为单位。比如:Cache-Control:max-age=120 表示2分钟之后过期。
min-fresh
指示客户端希望获取一个在小于指定的时间内被更新过的资源,单位为秒:例如:Cache-Control:min-fresh =120 。向服务器获取2分钟内被更新过的资源
max-stale
指示客户端可以接收超出超时期间的响应消息。例如:Cache-Control:max-stale =120 ,向服务器获取超过缓存时间2分钟的资源。
例:
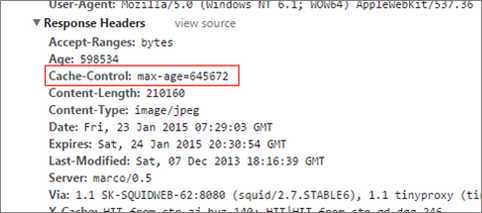
Cache-Control:max-age=645672
指定页面645672秒(7.47天)后过期。
Last-Modified:
标示这个响应资源的最后修改时间,web服务器在响应请求时,告诉浏览器资源的最后修改时间。
If-Modified-Since:
当资源过期时(也就是 Cache-Control:max-age=0,),发现资源具有Last-Modified声明,则再次向web服务器请求时带上头 If-Modified-Since,表示请求时间。web服
务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。若Last-Modified的时间较新,说明最后修改时间较新,说明资源又被改动过,则响应整
的资源重新从服务器读取,而不是读取缓存,返回200状态吗;若If-Modified-Since的时间比Last-Modified新或者相等,说明服务器的内容没有更新,直接读取缓存即可,
返回304状态码,告知浏览器继续使用所保存的cache。
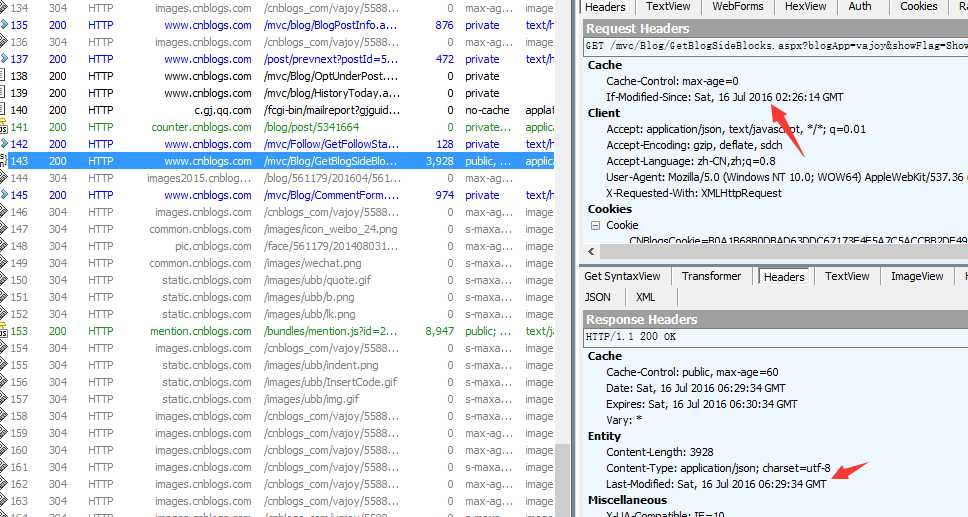
如下图,用fidder读取博客园的缓存:
If-Modified-Since的时间等于Last-Modified,直接读取缓存,返回304状态码
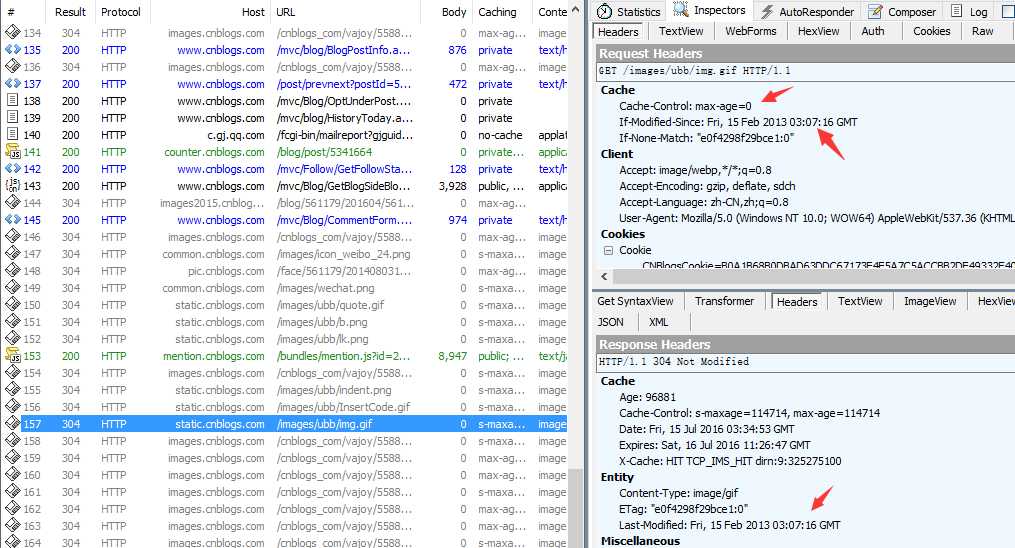
Last-Modified的时间较新,资源有改动,不读取缓存,重新从服务器获取资源,返回200状态码
Etag:
web服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。所以我们不用管它是怎么生成的。
它就像一个哈希或者指纹,每个文件都有一个单独的标志,只要这个文件发生了改变,这个标志就会发生变化。
Apache中,ETag的值,默认是对文件的索引节(INode),大小(Size)和最后修改时间(MTime)进行Hash后得到的。
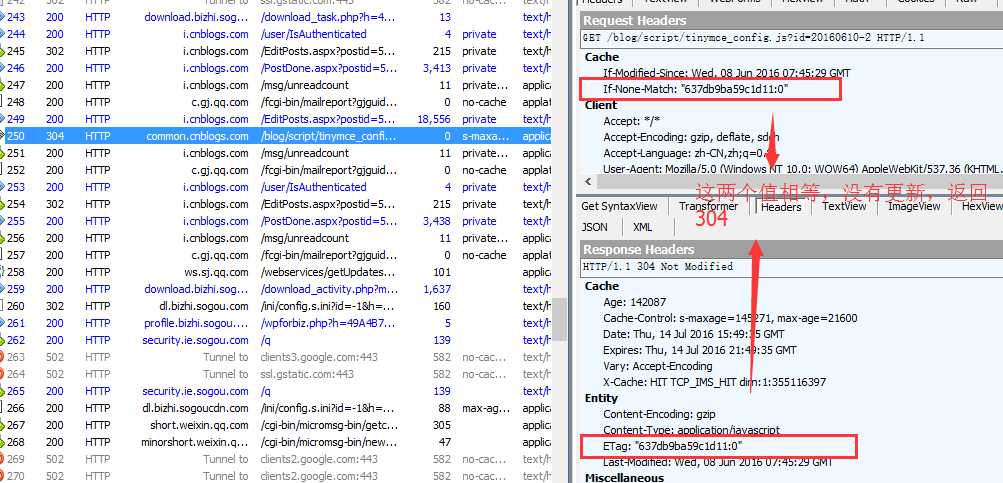
If-None-Match:
当资源过期时(也就是 Cache-Control:max-age=0),如果客户端发现服务端返回的头部信息具有Etage声明,则客户端会再次向web服务器请求时带上头If-None-
Match (Etag的值)。web服务器收到请求后发现有头If-None-Match 则与被请求资源的相应校验串进行比对,决定返回200或304。
如果Etag的值和If-None-Match的值相等,说明服务器的资源没有更新,返回304状态码,客户端直接读取缓存即可。如果Etag的值和If-None-Match的值不等,说明服务器的资
源有更新,返回200状态码,不读取缓存,重新从服务器获取资源。
实例如下:
读到这里,是不是有个小小的疑问,为啥Last-Modified已经可以判断了,那还要Etag来干嘛?是不是多此一举了。答案:非也
本文还是主要介绍缓存,其实cdn穿插进来不知道会不会很不好,不过本文是根据做分享的文件来总结的,所以也顺便总结一下cdn啦
CDN也叫内容分发网络,是一个经策略性部署的整体系统,包括分布式存储、负载均衡、网络请求的重定向和内容管理4个要件。而其中呢,内容管理和全局的网络流量管理是CDN的核心所在。通过用户就进行和服务器负载的判断,CDN确保内容以一种极为高效的方式为用户的请求提供服务。
(1)CDN节点解决了跨运营商和跨地域访问的问题,访问延时大大降低;
(2)大部分请求在CDN边缘节点完成,CDN起到了分流作用,减轻了源站的负载,解决网站高流量、大并发的问题
我国的网络是划江而治的格局,因为利益之争,各网络服务商之间并不是通力协作,而是采取各种手段相互限制。
这就导致各网之间的互联互通存在很大的问题,具体表现为:电信的用户访问放置在网通机房的服务器,响应时间特别长,反之亦然。
使用CDN技术,可以让电信的用户访问电信的内容缓存服务器,网通的用户访问网通的内容缓存服务器。通过这样一种策略,绕开了网络运
营商之间人为设置的障碍。
此外,还有以下的几个案例,使用CDN技术也很好的解决了下面所遇到的问题
1.一个企业的网站服务器在北京,运营商是电信,在广东的联通用户访问企业网站时,因为跨地区,跨运营商的原因,网站打开速度就会比
北京当地的电信客户访问速度慢很多,很容易造成这个企业的客户流失
2.一个网站的服务器性能比较差,承载能力有限,有时面临突发流量,招架不住,直接导致服务器崩溃,网站打不开,比如淘宝的双十一期,
因为这种情况网站打不开,那损失必然很大。而CDN也很好的解决了这一问题。
3.再比如一些中小企业租用的虚拟主机,因为跟好几个网站共用一台服务器,每个网站所分带宽有限,带宽过小经常导致流量稍微一多,
网站打开速度就很慢,甚至打不开。这些也是CDN可以解决的问题
1、CDN 对于不经常访问的资源是无效的。通常只有在 CDN缓存过期前有至少两次访问的资源才算有效。
2、CDN 对于不断变化的资源不适用。
3、CDN 对于不想公开资源可能是一个糟糕的选择。
cdn机制:
一般来说,互联网更快速度地数据传输与源数据和客户端有密切关系。将源数据的缓存副本放置得与客户端比较接近,当用户需要访问数据时,从最接近的位置检索它将比从原
始结点检索会更快儿些。这种做法通常称为分布式缓存,这也是CDN 的作用所在。
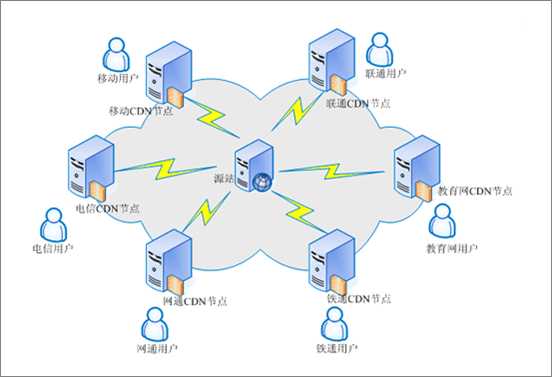
具体地说,我们将关注是通过 HTTP 访问的文件。虽然所有用户看到相同的 URL文件,不同的用户将被路由到不同的 CDN 节点。这是 CDN的要点 : 将请求路由到就近的
CDN 节点,以提高响应速度。
如图所示:
cdn的缓存机制:
CDN边缘节点缓存策略因服务商不同而不同,但一般都会遵循http标准协议,通过http响应头中的Cache-control: max-age的字段来设置CDN边缘节点数据缓存时间。当客
户端向CDN节点请求数据时,CDN节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则,CDN节点就会向源站发出回源请求,从源站拉
取最新数据,更新本地缓存,并将最新数据返回给客户端。所以,如果我们修改了内容,最好加个版本号,来容CDN重新获取资源,从而减少不必要的麻烦,比如 :
app.js?v=20160717 或者 style.css?v=2016071701
CDN服务商一般会提供基于文件后缀、目录多个维度来指定CDN缓存时间,为用户提供更精细化的缓存管理。CDN缓存时间会对“回源率”产生直接的影响。若CDN缓存时间较
短,CDN边缘节点上的数据会经常失效,导致频繁回源,增加了源站的负载,同时也增大的访问延时;若CDN缓存时间太长,会带来数据更新时间慢的问题。开发者需要增对特定的业务,来做特定的数据缓存时间管理。
小小总结,有误指出,欢迎指出
如果您觉得文章有用,也可以给咸鱼老弟发个微信小额红包鼓励鼓励,哈哈

标签:
原文地址:http://www.cnblogs.com/xianyulaodi/p/5670291.html