标签:
最近一直在撸Python Data Analysis上的代码(书是基于Python2的,小白我用的python3),所以我下的时候多少有些改动。
这是9.4中的nltk词频分析关于Dict_key的问题。
源码是这样的:
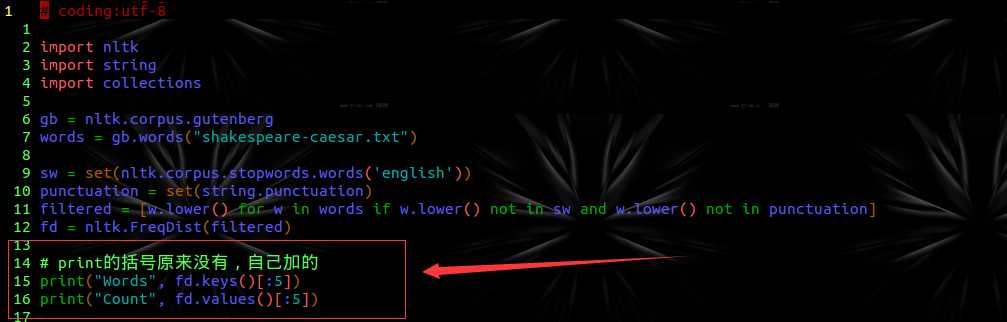
运行报错:

查了一下subscriptable,这个链接解释的还是比较清楚的。简单讲就是说,dict_key不再和list,tuple等一样包含可脚本化的对象。
之后尝试几下均告失败,想着跳过这里,但后面词频分析用的也不少,只好硬着头皮上啦!Google半天,发现了它(ps:stackoverflow还是相当不错的)。
也就是加个list。不过,这样的话,要取出词频最高的item的value容易,但对应的key却应为打乱了顺序而无法找到。于是,继续寻找解决的方案。感谢群里面大神相助,得知有个固定字典顺序的方法——collections.OrderredDict。具体使用可以参考这篇博文。
有了这个,就开始工作啦,工作目标——找出乱序字典{‘关键字’:‘次数’}中次数最多的几个词及其出现次数。
于是,就有了它:
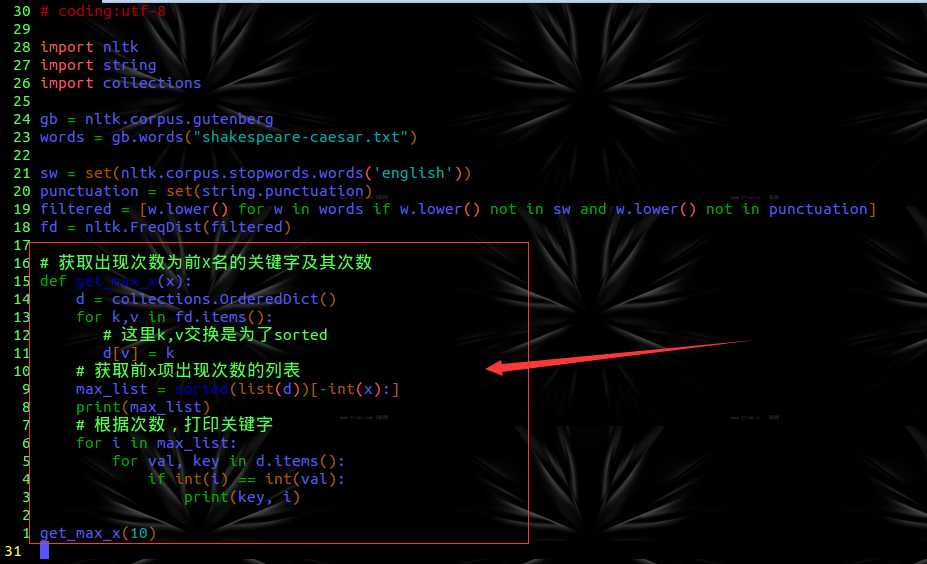
运行结果:
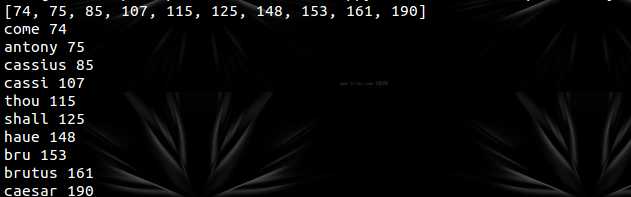
总算是成功了。。。不过总感觉好像走了弯路——不过至少学会了collections.OrderresDict——希望有哪位大侠看到能给出更好的解决方案。
至于Python Data Analysis,看完有时间也打算在这里总结一下。
我与python3擦肩而过(一)—— Dict与collections.OrderredDict邂逅
标签:
原文地址:http://www.cnblogs.com/buzhizhitong/p/5683131.html