标签:
Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
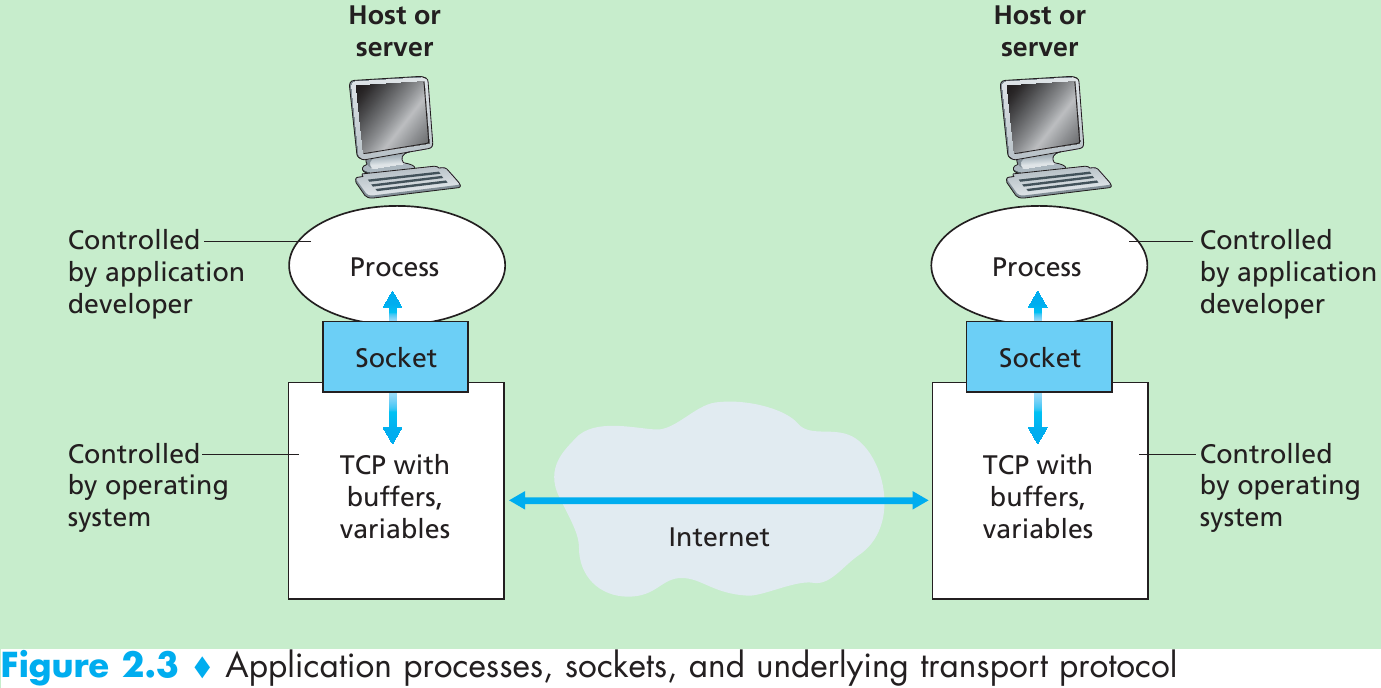
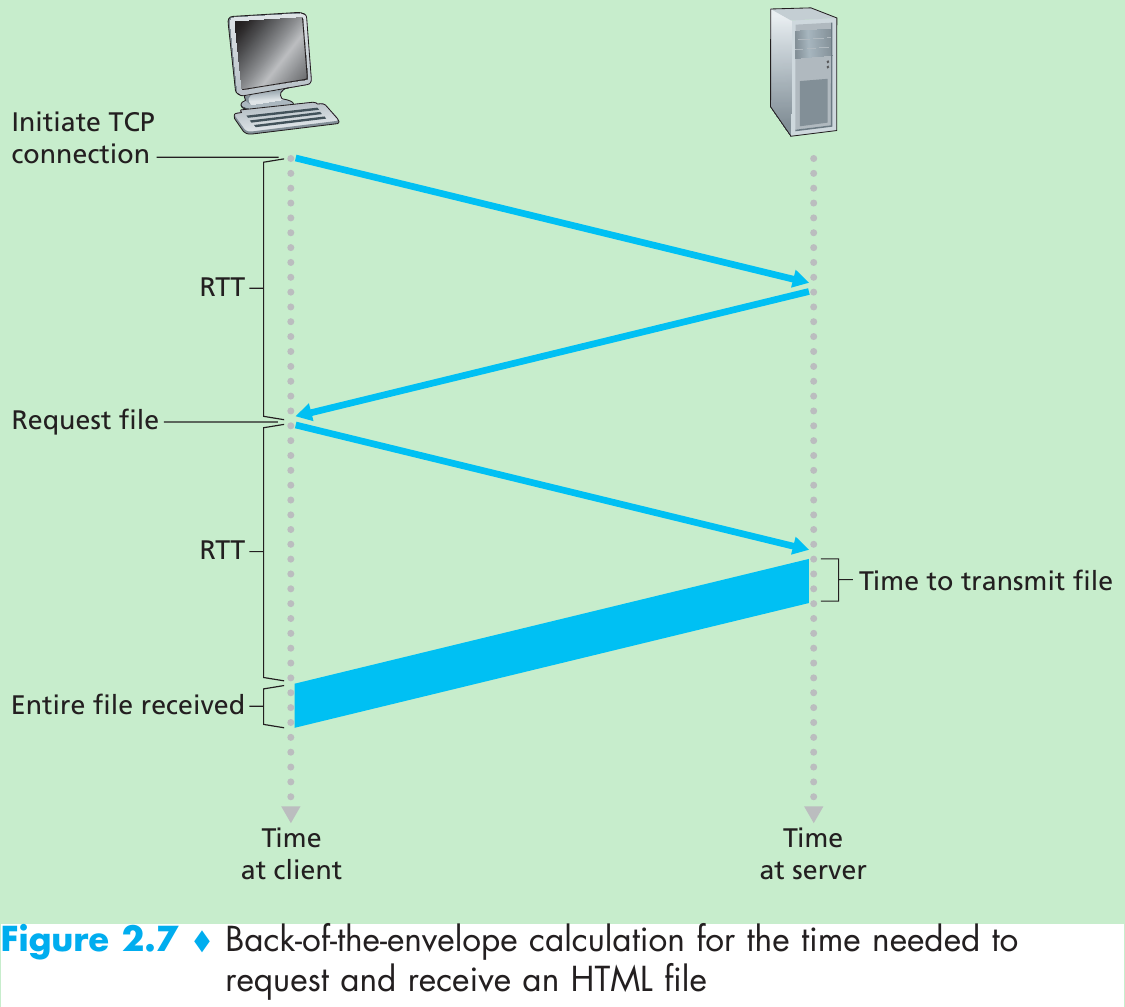
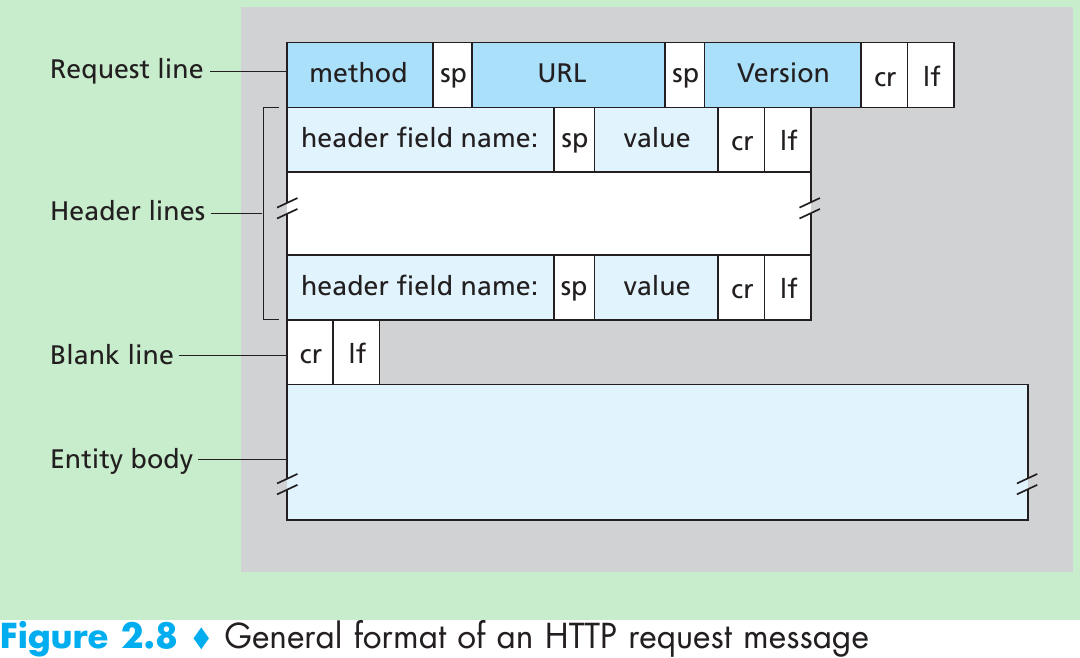
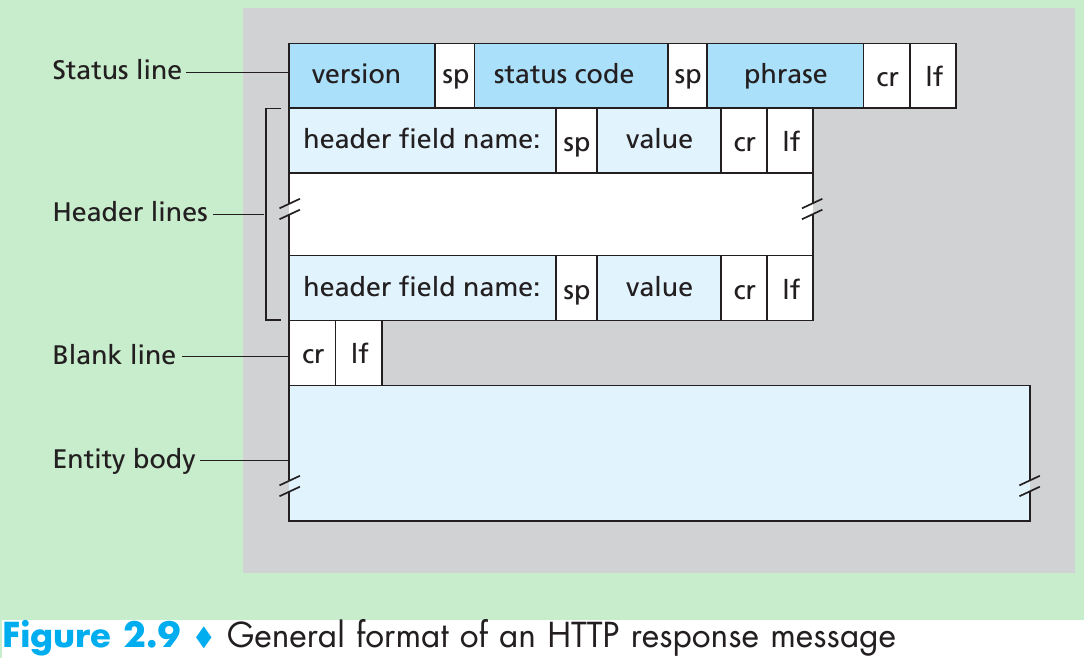
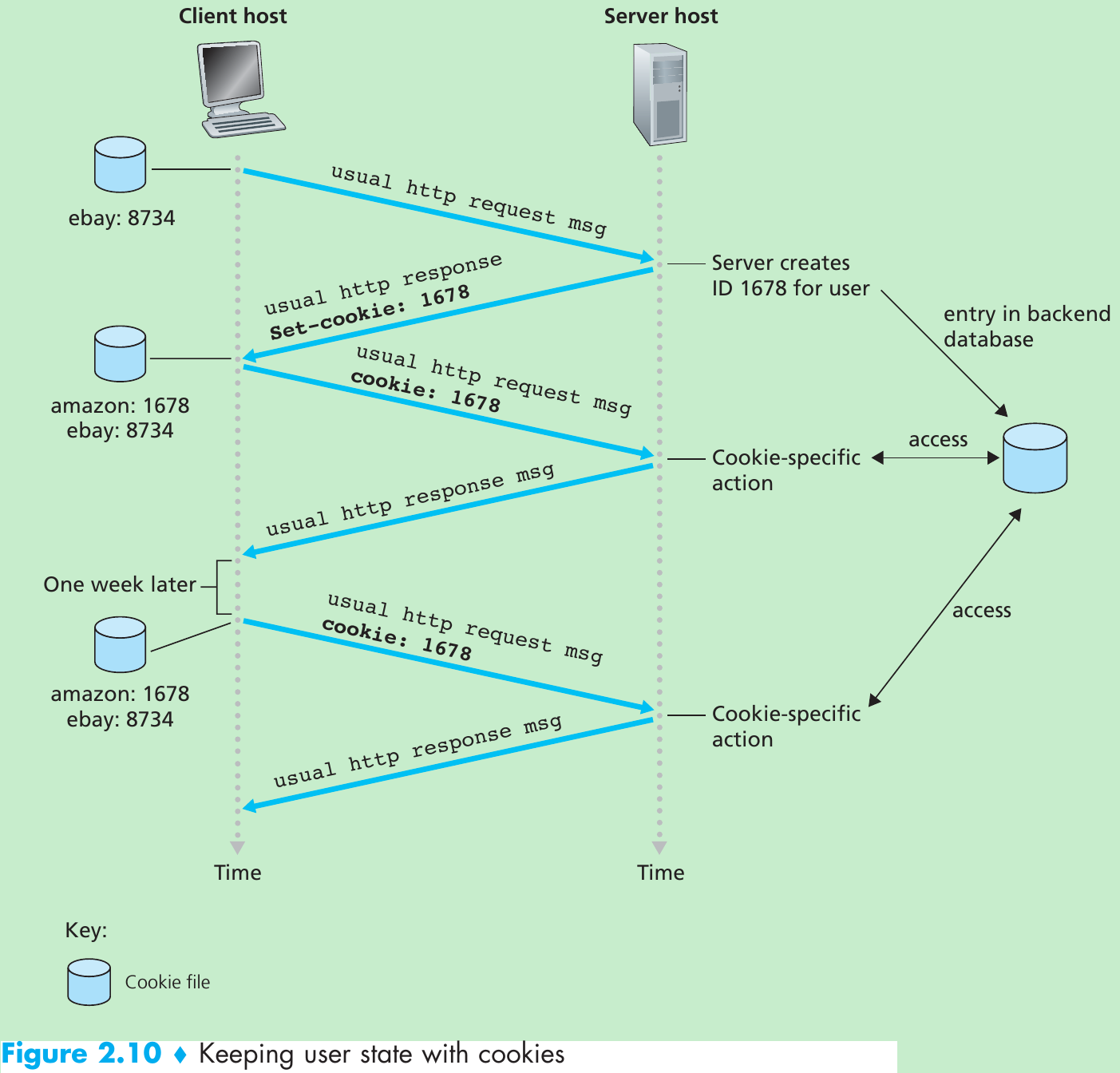
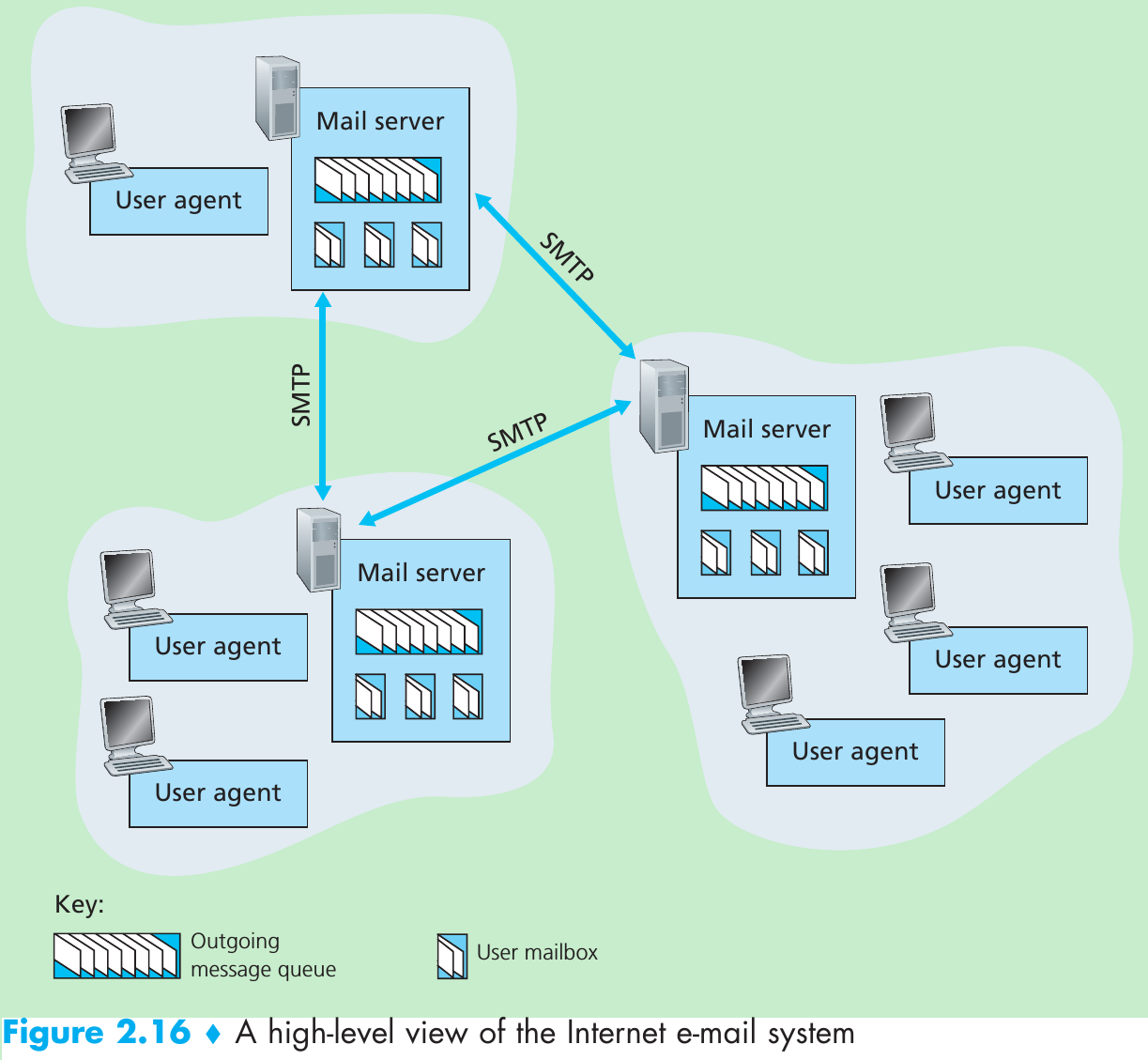
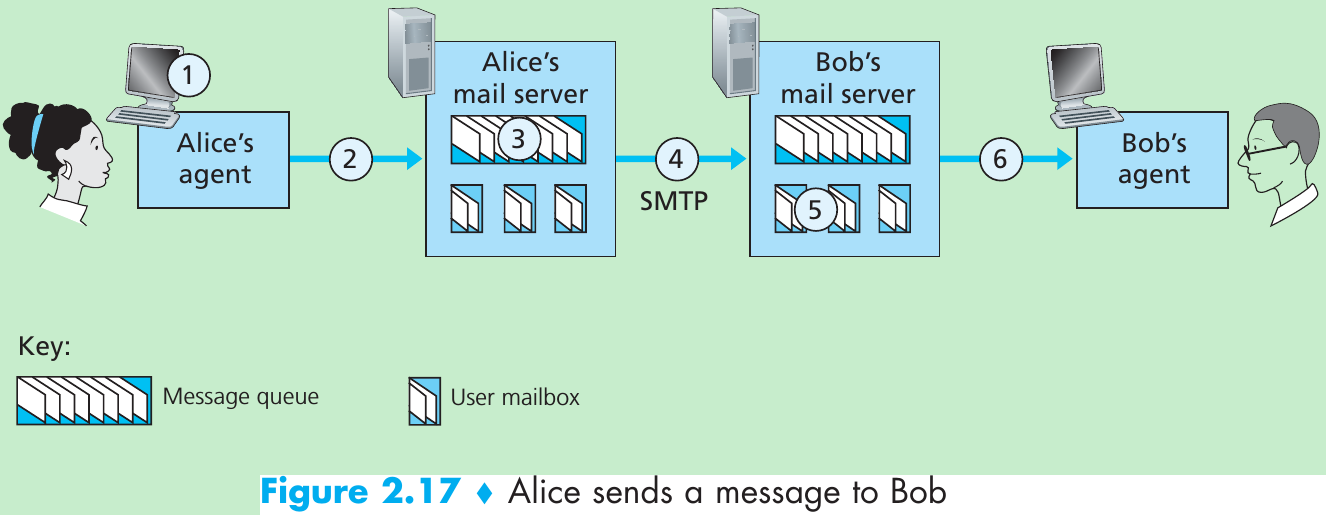
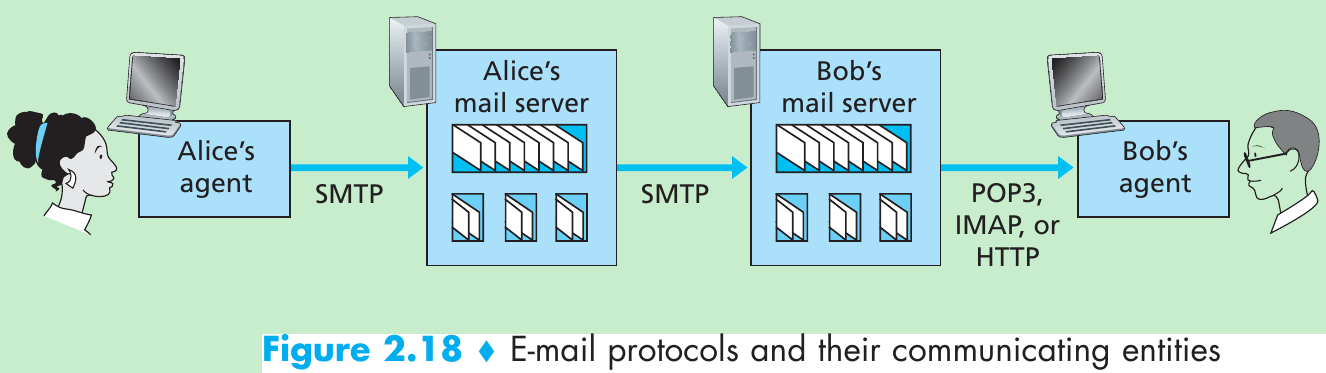
The path an e-mail message takes when it is sent from Alice to Bob:
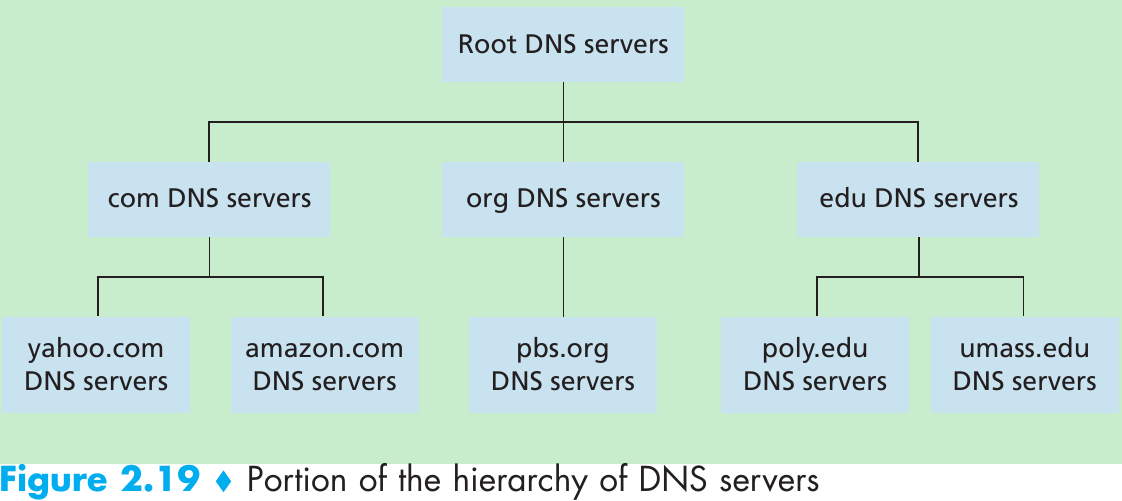
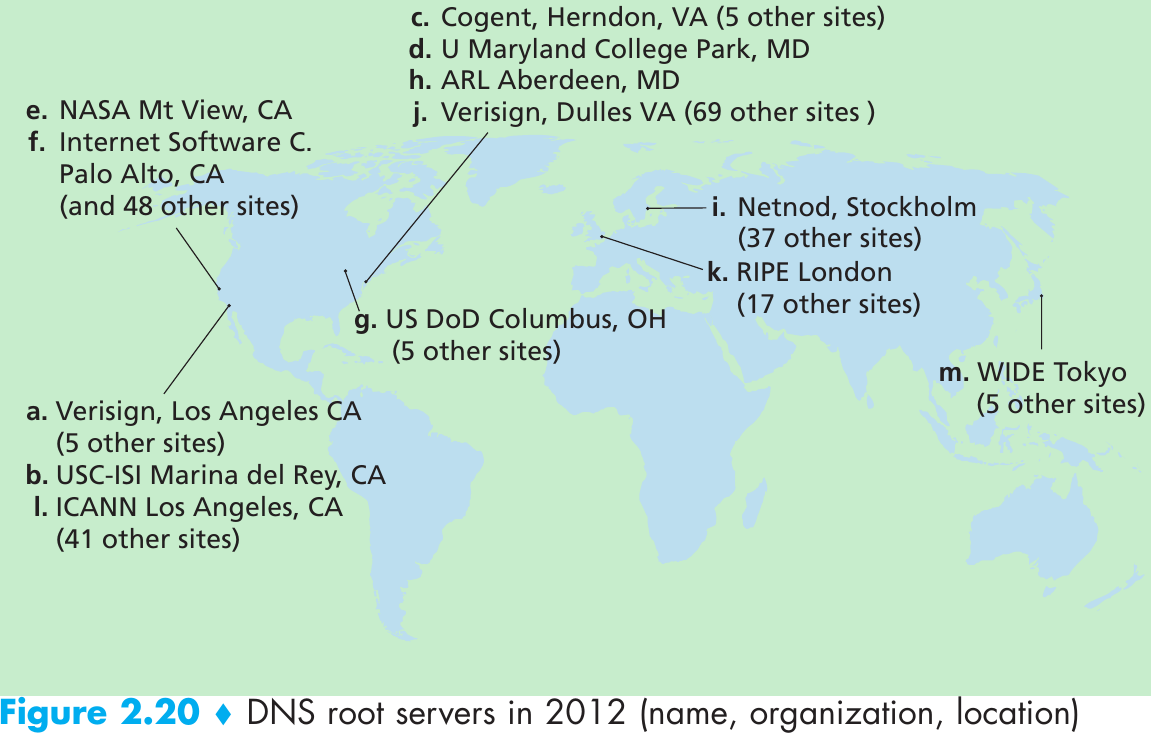
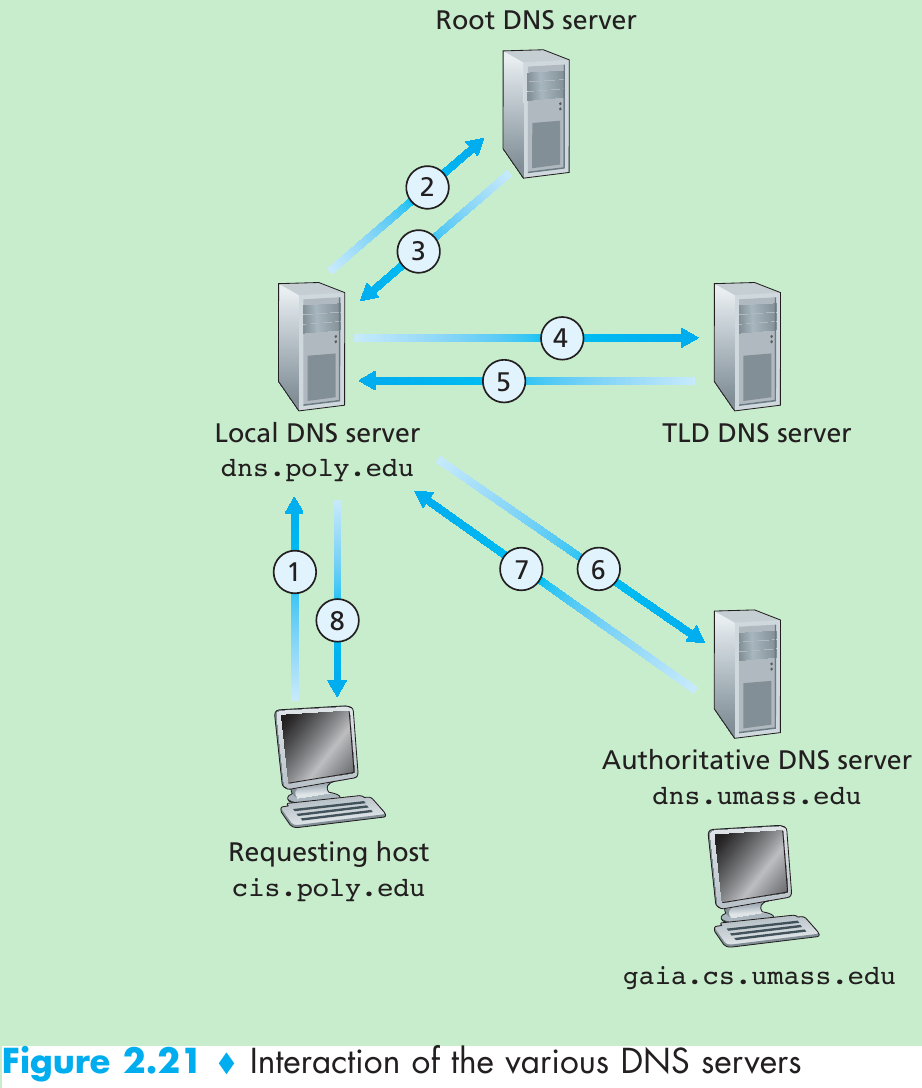

| Name | Value | Type | Example |
|---|---|---|---|
| hostname | hostname’s IP address | A | (relay1.bar.foo.com, 145.37.93.126, A) |
| domain | hostname of an authoritative DNS server that knows IP addresses for hosts in the domain | NS | (foo.com, dns.foo.com, NS) |
| hostname | canonical hostname | CNAME | (foo.com, relay1.bar.foo.com, CNAME) |
| hostname | canonical name of a mail server | MX | (foo.com, mail.bar.foo.com, MX) |
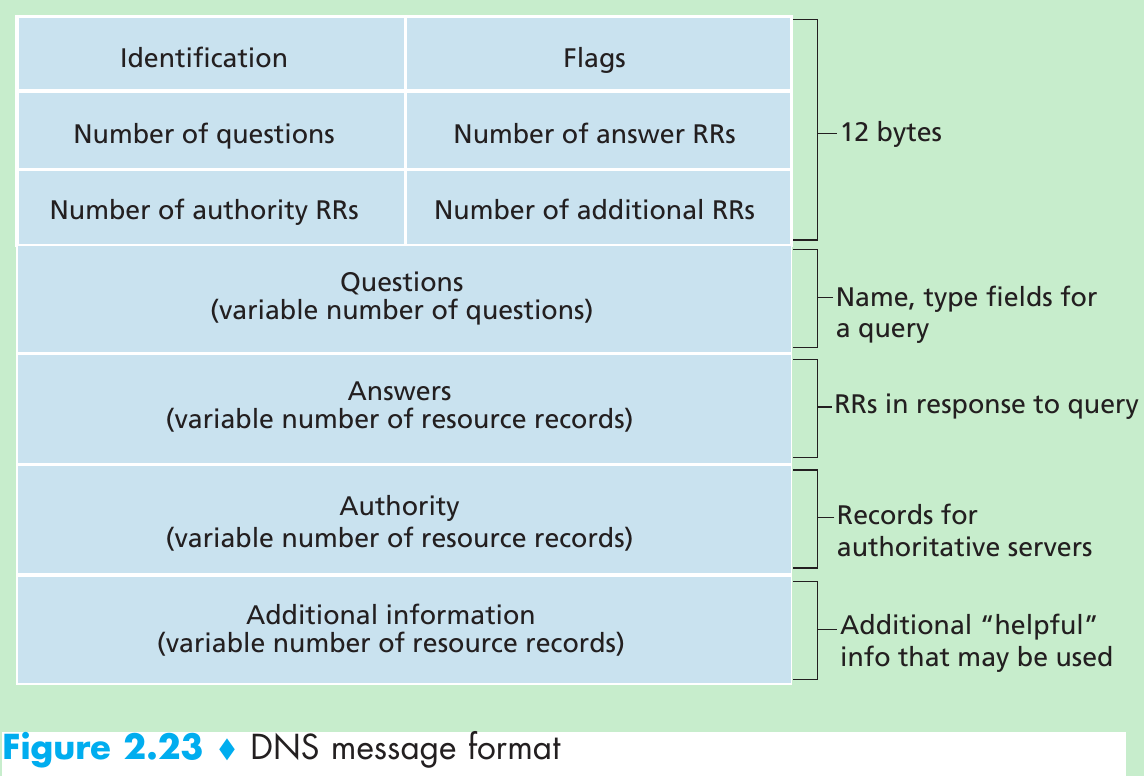
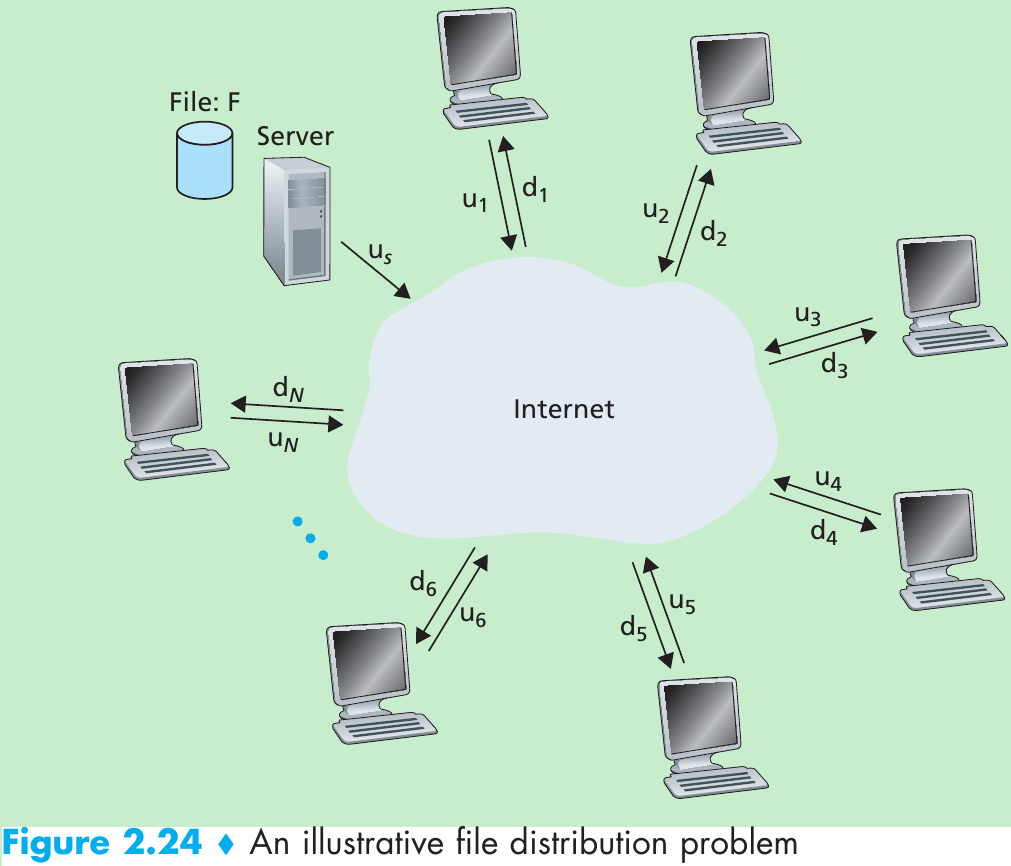
Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
标签:
原文地址:http://blog.csdn.net/gaoxiangnumber1/article/details/51954685
{kind=link}
{kind=link}