标签:
大数据我们全知道hadoop,但并不全都是hadoop。我们该如何构建大数据库项目。对于离线处理,hadoop还是比较适合的,但是对于实时性比较强的,数据量比较大的,我们可以采用storm,那么storm和什么技术搭配,才能做一个适合自己的项目。
1.一个好的项目架构应该具备什么特点?
2.本项目架构是如何保证数据准确性的?
3.什么是kafka?
4.flume+kafka如何整合?
5.使用什么脚本可以查看flume是没有往kafka传输数据?
做软件开发的全知道模块化思想,这样设计的原因有两方面:
一方面是可以模块化,功能划分更加清晰,从“数据采集--数据接入--流失计算--数据输出/存储”

1》数据采集
负责从各节点上实时采集数据,选用cloudera的flume来实现
2》数据接入
由于采集数据的速度和数据处理的速度不一定同步,因此添加一个消息中间件来作为缓冲,选用Apache的kafka
3》流式计算
对采集到的数据进行实时分析,采用Apache的storm
4》数据传输
对分析后的结果持久化,暂定用mysql
另一方面是模块化之后,假如当storm挂掉了之后,数据采集和数据接入还是继续在跑着,数据不会丢失,storm起来之后可以继续进行流式计算;
那么接下来我们来看下整体的架构图
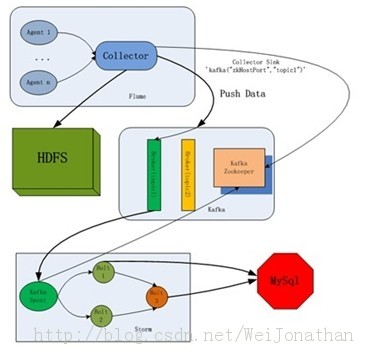
详细介绍各个组件及安装配置:
flume
flume是cloudera提供的一个分布式、可靠、和高可用的海量日志采集、聚合和传输的日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据;同时,flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力,在我们的系统中目前使用exec方式进行日志采集。
Flume的数据接受方,可以是console(控制台)、text(文件)、dfs(HDFS文件)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日志系统)等。在我们系统中由kafka来接收。
$tar zxvf apache-flume-1.4.0-bin.tar.gz
Flume启动命令:
$bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name producer -Dflume.root.logger=INFO,console

大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
标签:
原文地址:http://www.cnblogs.com/tian880820/p/5685495.html