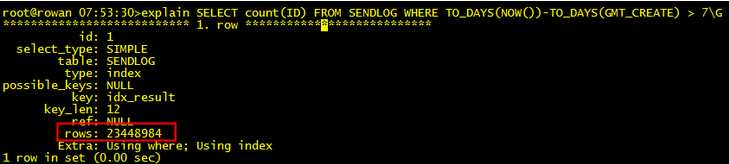
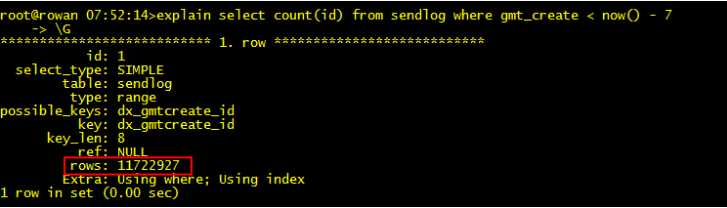
SELECT * FROM SENDLOG where result = 1 and gmt_create > ‘2013-10-29 12:40:44‘ limit 2000;
分析:result类型为char,传递的值1为整型,数据类型不一致,导致没法用索引,对于时间类型gmt_create > ‘2013-10-29 12:40:44‘,可以直接使用。
SELECT * FROM SENDLOG where result = ‘1‘ and gmt_create > ‘2013-10-29 12:40:44‘ limit 2000;
场景:获取某个卖家未读的消息。
select count(*) from mc_msg where receiver=‘sun098‘ and status=‘UNREAD‘ and title is not null;
问题:有时候db负载飙高,sql响应时间变慢。
分析:导致db负载飙高的原因是多个大卖家并发查询的时,cpu和逻辑读增加,load飙高。由于receiver,status已有索引,sql本身已经没有优化空间,了解业务后发现其实业务不需要精确值,如果大于99条,页面就直接显示为99+
优化后sql:
select count(*) from (select id from mc_msg where receiver=‘sun098‘ and status=‘UNREAD‘ and title is not null limit 100) a;
例子4:
场景:查看历史订单留言记录,未读留言的放在前面,已读的放在后面,并且按时间递减排序
select * from(
select ID,GMT_CREATE,GMT_MODIFIED,SENDER_ALI_ID,RECEIVER_ALI_ID,UNREAD_COUNT,STATUS,LAST_MESSAGE_ID,RELATION_ID,SELLER_ADMIN_SEQ,IS_READ
from message_relation_sender
WHERE SENDER_ALI_ID = 119545671 and UNREAD_COUNT > 0
order by LAST_MESSAGE_ID desc) m
union all
select * from(
select ID,GMT_CREATE,GMT_MODIFIED,SENDER_ALI_ID,RECEIVER_ALI_ID,UNREAD_COUNT,STATUS,LAST_MESSAGE_ID,RELATION_ID,SELLER_ADMIN_SEQ,IS_READ from message_relation_sender
WHERE SENDER_ALI_ID = 119545671 and UNREAD_COUNT = 0
order by LAST_MESSAGE_ID desc) n limit 5000,15;
分析:
(1)unread_count表示未读的订单留言记录数目;
(2)第一个子查询获取未读留言记录,第二子查询获取已读留言记录;
(3)LAST_MESSAGE_ID 递增,最新的订单留言,LAST_MESSAGE_ID最大。
(4)limit 5000,15是分页查询
这里使用union all,主要特点在于union all 不对结果集排序,直接合并,达到了“未读留言的放在前面,已读的放在后面”的效果,但同时也造成了两次扫描索引的结果,每个子查询都需要排序;而且union all还会产生临时表,执行代价会更大。
优化:
这里看到unread_count实际值对这个查询没有实际意义,我们只需要区分已读和未读即可。由于sql本身已经没有优化余地,考虑对表结构进行修改,加一个字段is_read,表示已读和未读。is_read=2表示未读;is_read=1表示已读。通过组合索引(SENDER_ALI_ID,is_read, LAST_MESSAGE_ID),既可以完成过滤,还可以完成排序。
优化后sql:
select ID,GMT_CREATE,GMT_MODIFIED,SENDER_ALI_ID,RECEIVER_ALI_ID,UNREAD_COUNT,STATUS,LAST_MESSAGE_ID,RELATION_ID,SELLER_ADMIN_SEQ,IS_READ from message_relation_sender
where SENDER_ALI_ID = 119545671 order by is_read desc, LAST_MESSAGE_ID desc limit 5000,15
第二次优化:
由于索引不包含所有的返回字段,因此需要回表,而mysql对于limit 5000,15的查询却需要返回5015次,这种无效的返回很影响查询效率。
分页的优化写法:
select t1.ID,GMT_CREATE,GMT_MODIFIED,SENDER_ALI_ID,RECEIVER_ALI_ID,UNREAD_COUNT,STATUS,LAST_MESSAGE_ID,RELATION_ID,SELLER_ADMIN_SEQ,IS_READ from message_relation_sender t1,
(select id
from message_relation_sender
where SENDER_ALI_ID = 119545671 order by is_read desc, LAST_MESSAGE_ID desc limit 5000,15
)t2 where t1.id = t2.id