标签:
1. 采用QQ浏览器 , 当前以获取qiushibaike里面的内容以及好笑,评论数为例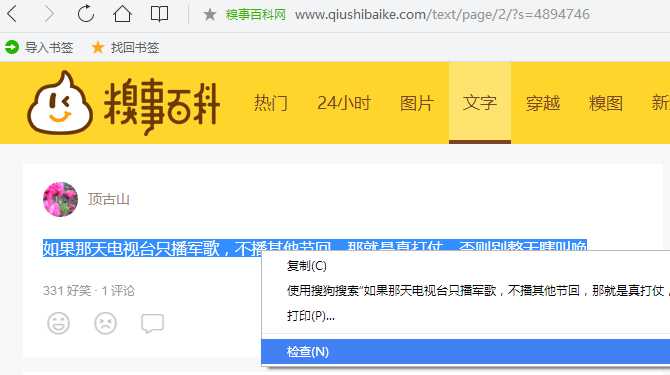
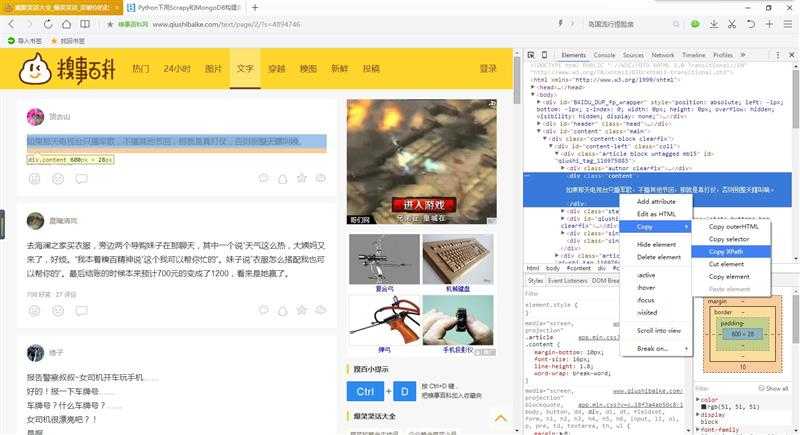
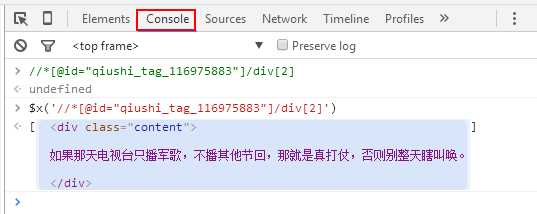
1.内容 //*[@id="qiushi_tag_116975883"]/div[2]2.好笑 //*[@id="qiushi_tag_116975883"]/div[3]/span[1]/i3.评论数 //*[@id="c-116975883"]/i
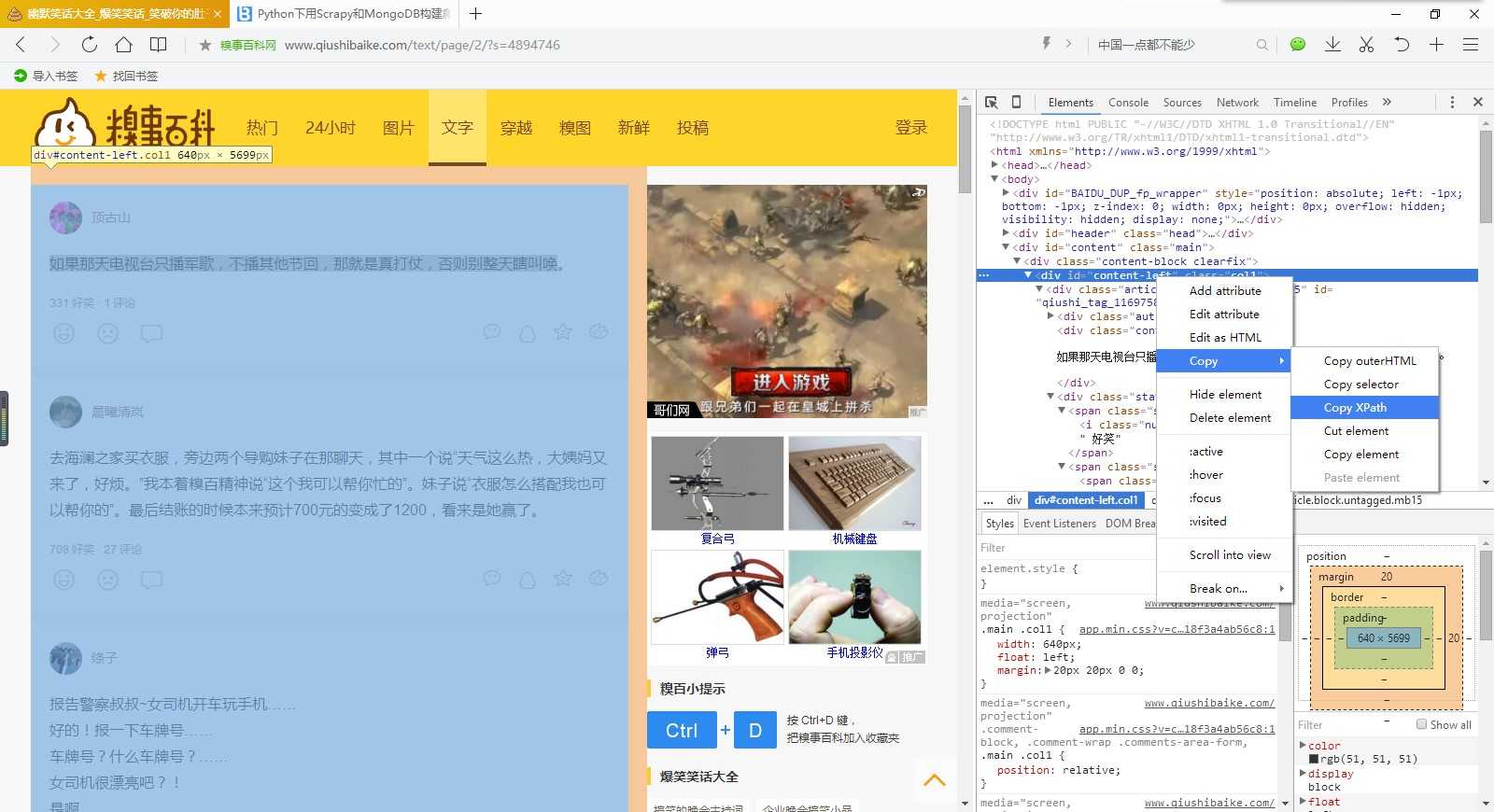
from scrapy import Spiderfrom scrapy.selector import Selectorfrom stack.items import StackItemclass StackSpider(Spider):name = "stack"allowed_domains = ["stackoverflow.com"]start_urls = ["http://stackoverflow.com/questions?pagesize=50&sort=newest",]def parse(self, response):questions = Selector(response).xpath(‘//div[@class="summary"]/h3‘)for question in questions:item = StackItem()item[‘title‘] = question.xpath(‘a[@class="question-hyperlink"]/text()‘).extract()[0]item[‘url‘] = question.xpath(‘a[@class="question-hyperlink"]/@href‘).extract()[0]yield item我们将遍历问题,从抓取的数据中分配标题和URL的值。一定要利用Chrome开发者工具的JavaScript控制台测试XPath的选择器,例如$x(‘//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()‘) 和 $x(‘//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href‘)。
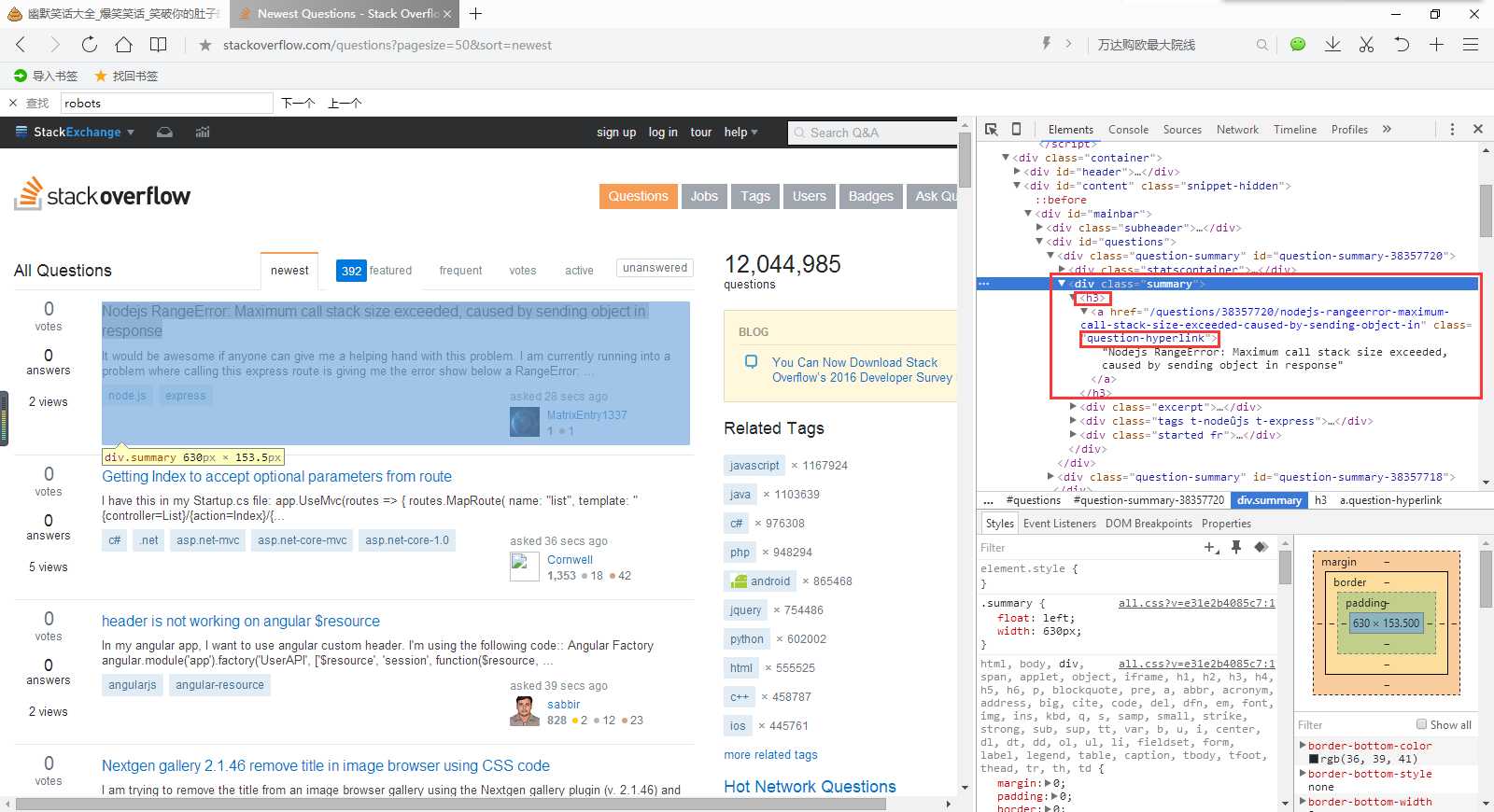
2016/7/13 23:39:43 xPath 分析网页元素
标签:
原文地址:http://www.cnblogs.com/topshooter/p/5687855.html