标签:
一、简介
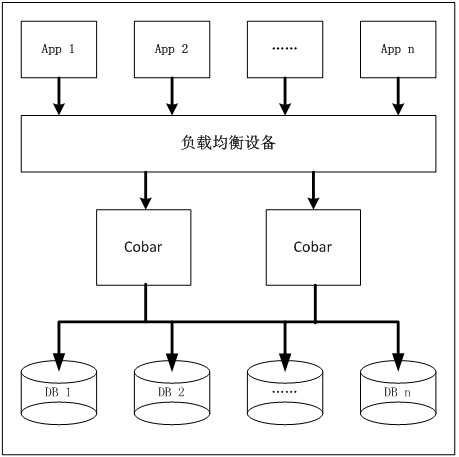
Cobar是一个对数据进行拆分后进行分布式存储的产品,可以支持使用后台的 MySQL或者Oracle数据库,通过配置,将数据按照一定规则存储入不同的数据库中。即用分布式数据库代替了集中式数据库。传统的集中式数据库系统有如下不足:集中式处理,势必造成性能瓶颈;应用程序集中在一台计算机上运行,一旦该计算机发生故障,则整个系统受到影响,可靠性不高;集中式处理引起系统的规模和配置都不够灵活,系统的可扩充性差。在这种形势下,集中式数据库将向分布式数据库发展。
分布式数据库系统的优点:降低费用。分布式数据库在地理上可以是分布的。其系统的结构符合这种分布的要求。允许用户在自己的本地录用、查询、维护等操作,实行局部控制,降低通信代价,避免集中式需要更高要求的硬件设备。而且分布式数据库在单台机器上面数据量较少,其响应速度明显提升;提高系统整体可用性。避免了因为单台数据库的故障而造成全部瘫痪的后果;易于扩展处理能力和系统规模。分布式数据库系统的结构可以很容易地扩展系统,在分布式数据库中增加一个新的节点,不影响现有系统的正常运行。这种方式比扩大集中式系统要灵活经济。在集中式系统中扩大系统和系统升级,由于有硬件不兼容和软件改变困难等缺点,升级的代价常常是昂贵和不可行的。
//优点: // 配置简单, 可以很方便的实现数据的分布式存储。 // 使用透明, 客户端几乎不需要为此做任何的特殊设定。 // 扩展方便, Cobar服务端可以通过负载均衡进行扩展, 数据库可以根据不同的压力进行扩张。 // //缺点: // 查询限制, 如果提交的请求不包含分表字段的限制, 则可能在多个分区执行, 效率和可行性都大打折扣 (碰到过一个普通查询抛出异常的情况, 具体场景还需要验证) // 联合查询限制, 对于在不同分区的数据, 无法进行联合查询。 // 扩展, 在初始时的分区数目如果无法应对后续需求, 需要增加分区的话 (如, 初始设计分为 64 个分区表, 因为单表通常限制数据量在 20G, // 后期发现无法满足容量需求, 需要扩展成 128/256 个分区), 没有现成的解决方案, 只能对数据进行人工拆分
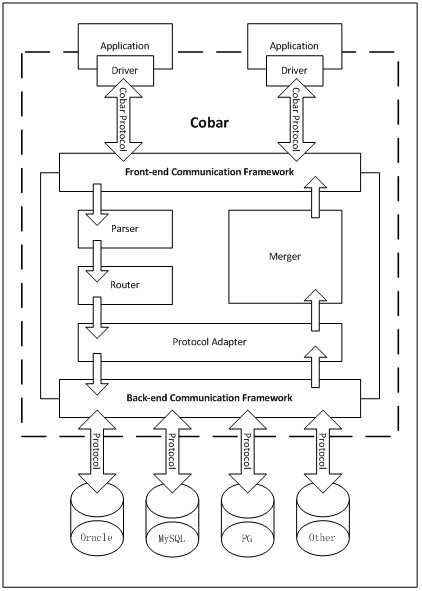
Cobar在分布式数据库领域将致力解决数据切分,应付客户端"集中式"处理分布式数据。这儿集中式是一个相对概念,客户端不需要知道某种数据的物理存储地。避免这种逻辑出现在业务端,大大简化了客户端操作分布式数据的复杂程度。 专注分布式数据库proxy开发。其架设在Client、DB Server(s)之间、对客户端透明、具有负载均衡、高可用性、sql过滤、读写分离、可路由相关的query到目标数据库、可并发请求多台数据库合并结果。
二、Cobar的使用验证
目前, 我在开发环境 10.20.130.119 上部署了 Cobar 和 MySQL 的测试环境:MySQL 分为 128 个 DataBase, 分别是 cobar_1 至 cobar_128, 端口是 3306, 用户名/密码: root/password。Cobar 的访问方式为使用 MySQL 连接, URL 为 jdbc:mysql://10.20.130.119:8066/cobar, 用户名/密码: root/12345。测试数据库表为 q_reportkeywordsum, 分区所用字段为 custid, int 型。如果使用JDBC方式连接Cobar, 则只需要使用 MySQL的JDBC驱动(注意,不能使用最新的 5.1.13 版本, 需要使用 Cobar 自带的 5.1.6 版 MySQL Connector),正常连接即可。示例代码如下:
import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.sql.Statement; public class CobarHelloWorld { public void mian(String[] args) { String url = "jdbc:mysql://10.20.130.119:8066/cobar"; String driver = "com.mysql.jdbc.Driver"; String user = "root"; String pwd = "12345"; Connection con = null; try { Class.forName(driver).newInstance(); con = DriverManager.getConnection(url, user, pwd); Statement stmt = con.createStatement(); // TODO stmt.close(); } catch (Exception e) { // ... } finally { if (con != null) { try { con.close(); } catch (SQLException e) { e.printStackTrace(); } } } } }
如果使用 Spring + iBatis 访问, 则需要对配置文件作少许改动, 将原org.springframework.orm.ibatis.SqlMapClientTemplate 替换为 Cobar Client 提供的com.alibaba.cobar.client.CobarSqlMapClientTemplate。同时, 将TransactionManager从原 org.springframework.jdbc.datasource.DataSourceTransactionManager替换为 com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager,其他部分不需要改动, 修改后的配置代码类似以下示例:
<bean id="sqlMapClientTemplate" class="com.alibaba.cobar.client.CobarSqlMapClientTemplate"> <property name="sqlMapClient" ref="sqlMapClient"/> ... </bean> <bean id="transactionManager" class="com.alibaba.cobar.client.transaction.MultipleDataSourcesTransactionManager"> ... </bean> <bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="configLocation" value="classpath:META-INF/ibatis/sqlmap-config.xml" /> </bean> <bean id="dataSource" ...> ... </bean>
开发注意点:如果查询条件不包含分区字段条件, 则会将请求在所有的分区执行后返回全部结果集, 如执行:
select count(*) from q_reportkeywordsum
则返回所有分区中的查询结果 (如分区为 128 个, 则结果集中包含 128 个记录). 而且, 在这样的情况下, 效率会很差, 需要等待 128 个分区全部执行完后才会返回结果集.解决: 所有查询都 必须 限定在某一指定的分区字段, 如
select count(*) from q_reportkeywordsum where custid=1
但是,要注意:select count(*) from q_reportkeyworsum where custid < 10; 代码是不能正确返回结果的。同样的,如果插入记录时不指定分区字段, 则会在所有分区表内均插入记录, 如执行:
insert into q_reportkeywordsum (id, keywordid) values (2, ...)
将会在全部 128 个分区内均插入本条记录。解决: 对于用作分区规则的字段 (如示例中所用 custid) 必须设置为非空 (NOT NULL) 字段,以避免此类问题。对于不同的分区表, 数据库主键可以重复, 这一点从上一段即可看出, id 作为主键字段, 插入过程会在所有分区中均插入一条 id 为 2 的记录, 因此, 需要额外使用主键生成机制保障在不同表内的主键不会发生重复。
三、Cobar使用约束
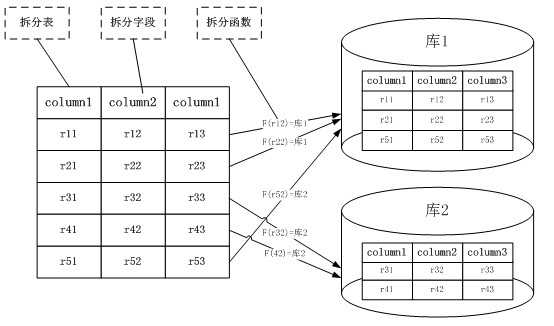
Cobar表的水平拆分,上图中,数据库表被水平拆分成2份,分别放到两个库中。F( x )是拆分函数,它根据每一条记录的拆分字段的取值,决定将这条记录拆分到哪个库里。拆分函数可以是多元函数,即 F(x1,x2,..xn)。但是对任意一个拆分函数,不存在该函数的两个自变量xi,xj,使得 xi 和 xj 是来自不同拆分表的拆分字段。
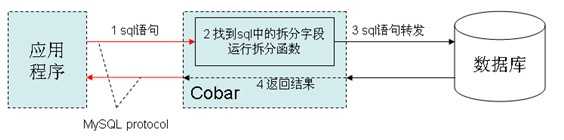
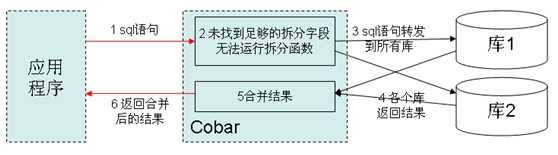
左图所示,cobar位于应用和数据库之间,cobar与应用通过mysql protocol交互。若应用发来的sql语句中包含拆分字段(拆分函数的自变量),以左图方式工作:否则,根据配置,以右图方式工作,或直接报错。
// 如果应用和cobar之间通过F5连接,那么F5与cobar的连接保持时间设置为1小时。 // 应用必须通过mysql-connector-5.0.4连接cobar,拆分函数值域元素数最大1024 // 不支持DDL,不支持事务,不允许跨库的join、跨库的子查询、跨库的分页排序 // 对于操作拆分表的sql语句,需包含拆分字段,方式如下: // 1.对select, delete, update语句,拆分字段存在于where中,以c[i]=xx的形式存在(运算符必须是=、xx必须是某个具体值,不能是字段名或子查询结果) // 2.insert语句(insert into table (c1, c2 ...) values (value1,value2); insert into table set // c1=value1,c2=....)中拆分字段出现在红色部分中,同时拆分字段对应的valueXX也必须是某个具体值。 // 建议: // 1. 记录数小于1千万或表空间小于10G的,不做拆分。 // 2. F(拆分字段取值)服从均匀分布,其中F是拆分函数。
备注:
利用Redis解决MySQL分表自增ID的问题。采用redis的ID自增生成器 就行,每次插入之前,都去调用一个自增长的函数,返回的数值永远是唯一,全局唯一的。
标签:
原文地址:http://www.cnblogs.com/RunForLove/p/5694968.html