标签:
管道(pipe)
在linux中,管道也是一种文件,只不过比较特殊,我们可以用pipe函数创建一个管道,其原型声明如下:
#inlcude <unistd.h>
int
pipe(int fields[2]);
调?用pipe函数时在内核中开辟?一块缓冲区(称为管道)?用于通信,它有?一个读端?一个写端,然后通
过filedes参数传出给?用户程序两个?文件描述符,filedes[0]指向管道的读端,filedes[1]指向管道的
写端(很好记,就像0是标准输?入1是标准输出?一样)。所以管道在?用户程序看起来就像?一个打开
的?文件,通过read(filedes[0]);或者write(filedes[1]);向这个?文件读写数据其实是在读写内核缓冲
区。pipe函数调?用成功返回0,调?用失败返回-1。
下面的例子中,创建一个管道作为通信缓冲区,父进程创建了一个子进程,子进程通过管道的fields[1]描述符想管道中写入一个字符串,
而父进程则利用管道的fields[0] 从管道中读取这个字串并显示出来:
#include
管道的容量:
方法一:使用linux的ulimit -a来查看系统限制:
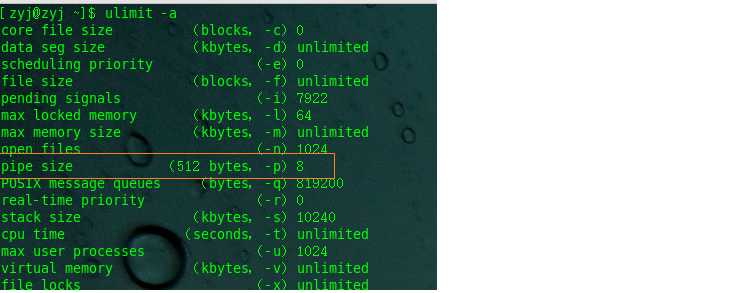
所以一次原子输入的大小为:512Byte * 8=4096Byte;
查看缓冲条目个数:cat /usr/src/kernels/3.10.0-327.el7.x86_64/include/linux/pipe_fs_i.h文件,
发现有16个缓冲条目,于是计算出管道的容量大小为:16*4096Byte=64kb;
方法二:我们也可以通过查手册:man 7 pipe查询管道的容量pipe capacity:
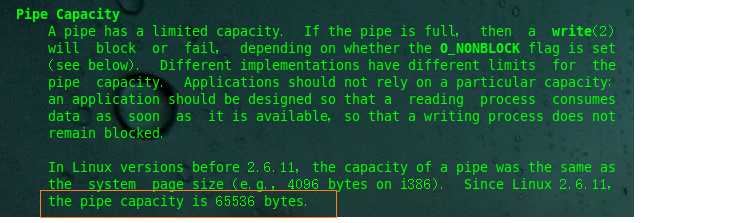
管道的内部组织方式:
在 Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。
通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。有两个
file 数据结构,但它们定义文件操作例程地址是不同的,其中一个是向管道中写入数据的例程地址,而另一个是从管
道中读出数据的例程地址。这样,用户程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管
道这一特殊操作。
标签:
原文地址:http://www.cnblogs.com/-zyj/p/5694787.html