标签:
这两天看了一下python的基础语法,跟着网上的教程爬了一下百度百科和python相关联的词条。采用了beautifulsoup4插件
下面是流程
首先是一个url管理器,负责增加/获取/判断是否有url

1 # coding:UTF8 2 #url管理器 3 class UrlManager(object): 4 def __init__(self): 5 self.new_urls=set() 6 self.old_urls=set() 7 8 def add_new_url(self,url): 9 if url is None: 10 return 11 12 if url not in self.new_urls and url not in self.old_urls: 13 self.new_urls.add(url) 14 15 def add_new_urls(self,urls): 16 if urls is None or len(urls)==0: 17 return 18 19 for url in urls: 20 self.add_new_url(url) 21 22 def has_new_url(self): 23 return len(self.new_urls)!=0 24 25 26 def get_new_url(self): 27 new_url=self.new_urls.pop() 28 self.old_urls.add(new_url) 29 return new_url
然后是一个网页下载器,实现网页的下载
1 import urllib2 2 3 class HtmlDownloader(object): 4 5 6 def download(self, url): 7 if url is None: 8 return None 9 10 #下载网页 11 response = urllib2.urlopen(url) 12 13 #如果状态不为200 即失败,返回空 14 if response.getcode() != 200: 15 return None 16 17 #以字符串形式返回网页 18 return response.read()
然后是网页解析器,实现获取网页中的url和内容的保存
1 from bs4 import BeautifulSoup 2 import re 3 import urlparse 4 5 6 class HtmlParser(object): 7 8 9 def _get_new_url(self, page_url, soup): 10 new_urls=set() 11 # /view/123.htm 12 links=soup.find_all(‘a‘,href=re.compile(r"/view/\d+\.htm")) 13 for link in links: 14 new_url=link[‘href‘] 15 new_full_url=urlparse.urljoin(page_url,new_url) 16 new_urls.add(new_full_url) 17 18 return new_urls 19 20 def _get_new_data(self, page_url, soup): 21 res_data={} 22 23 #url 24 res_data[‘url‘]=page_url 25 26 #<dd class="lemmaWgt-lemmaTitle-title"> <h1>Python</h1> 27 title_node=soup.find(‘dd‘,class_="lemmaWgt-lemmaTitle-title").find("h1") 28 res_data[‘title‘]=title_node.get_text() 29 30 # <div class="lemma-summary"> 31 summary_node=soup.find(‘div‘,class_="lemma-summary") 32 res_data[‘summary‘]=summary_node.get_text() 33 34 return res_data 35 36 def parse(self,page_url,html_cont): 37 if page_url is None or html_cont is None: 38 return 39 40 soup =BeautifulSoup(html_cont,‘html.parser‘,from_encoding=‘utf-8‘) 41 new_urls=self._get_new_url(page_url,soup) 42 new_data=self._get_new_data(page_url,soup) 43 return new_urls,new_data
然后是网页内容输出,将我们需要的内容保存下来
1 class HtmlOutputer(object): 2 def __init__(self): 3 self.datas=[] 4 5 def collect_data(self,data): 6 if data is None: 7 return 8 self.datas.append(data) 9 10 11 def output_html(self): 12 fout=open(‘output.html‘,‘w‘) 13 14 fout.write("<html>") 15 fout.write("<body>") 16 fout.write("<table>") 17 18 #ascii 19 for data in self.datas: 20 fout.write("<tr>") 21 fout.write("<tr>%s</td>" % data[‘url‘]) 22 fout.write("<tr>%s</td>" % data[‘title‘].encode(‘utf-8‘)) 23 fout.write("<tr>%s</td>" % data[‘summary‘].encode(‘utf-8‘)) 24 fout.write("/tr") 25 26 fout.write("</html>") 27 fout.write("</body>") 28 fout.write("</table>") 29 30 fout.close()
最后是主函数的调用,注释还算明白
1 # coding:UTF8 2 # 以入口url为参数爬取相关页面 3 from baike_spider import url_manager, html_downloader, html_parser, html_outputer 4 5 6 class SpiderMain(object): 7 #构造函数声明url管理器,网页下载器,网页解析器,网页输入器 8 def __init__(self): 9 self.urls = url_manager.UrlManager() 10 self.downloader = html_downloader.HtmlDownloader() 11 self.parser = html_parser.HtmlParser() 12 self.outputer = html_outputer.HtmlOutputer() 13 14 def craw(self, root_url): 15 #记录爬取的网页数 16 count = 1 17 18 #把入口url传入 19 self.urls.add_new_url(root_url) 20 #当new_urls里面还有元素时 21 while self.urls.has_new_url(): 22 try: 23 #获取一个新的url 24 new_url = self.urls.get_new_url() 25 print ‘craw %d:%s‘ % (count, new_url) 26 27 #接收网页的内容 28 html_cont = self.downloader.download(new_url) 29 30 #获取新的url 和需要的网页上的内容 31 new_urls, new_data = self.parser.parse(new_url, html_cont) 32 self.urls.add_new_urls(new_urls) 33 34 #拼接数据字符串 35 self.outputer.collect_data(new_data) 36 37 if count == 1000: 38 break 39 40 count = count + 1 41 42 except: 43 print ‘craw failed‘ 44 45 #向output.html写入数据 46 self.outputer.output_html() 47 48 if __name__ == "__main__": 49 root_url = "http://baike.baidu.com/view/21087.htm" 50 obj_spider = SpiderMain() 51 obj_spider.craw(root_url)
然后是输出结果的截图
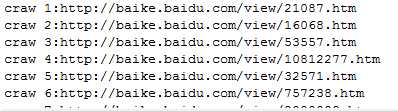
另外网页的信息保存到了output.html文件中
标签:
原文地址:http://www.cnblogs.com/wangkaipeng/p/5697134.html
