标签:
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信
安装libevent memcached依赖于libevent API,因此要事先安装之,项目主页:http://libevent.org/,读者可自行选择需要的版本下载。本文采用的是目前最新版本的源码包libevent-2.0.16-stable.tar.gz。安装过程: # tar xf libevent-2.0.20-stable.tar.gz # cd libevent-2.0.20 # ./configure --prefix=/usr/local/libevent # make && make install # echo "/usr/local/libevent/lib" > /etc/ld.so.conf.d/libevent.conf # ldconfig 安装配置memcached 1、安装memcached # tar xf memcached-1.4.15.tar.gz # cd memcached-1.4.15 # ./configure --prefix=/usr/local/memcached --with-libevent=/usr/local/libevent # make && make install
memcached的常用选项说明-l <ip_addr>:指定进程监听的地址; -d: 以服务模式运行; -u <username>:以指定的用户身份运行memcached进程; -m <num>:用于缓存数据的最大内存空间,单位为MB,默认为64MB; -c <num>:最大支持的并发连接数,默认为1024; -p <num>: 指定监听的TCP端口,默认为11211; -U <num>:指定监听的UDP端口,默认为11211,0表示关闭UDP端口; -t <threads>:用于处理入站请求的最大线程数,仅在memcached编译时开启了支持线程才有效; -f <num>:设定Slab Allocator定义预先分配内存空间大小固定的块时使用的增长因子; -M:当内存空间不够使用时返回错误信息,而不是按LRU算法利用空间; -n: 指定最小的slab chunk大小;单位是字节; -S: 启用sasl进行用户认证;
安装python的memcached的模块
pip install python-memcached
import memcache host_port = ‘127.0.0.1:11211‘ #memcache的ip和端口 mc = memcache.Client([host_port], debug=True) #debug表示开启调试, mc.set(‘name‘,‘fuzj‘) #设置key mc.set(‘name‘,‘jeck‘) #设置key,key存在则更新 mc.set(‘name1‘,‘test‘) #设置key,key存在则更新 mc.set(‘name2‘,‘test‘) #设置key,key存在则更新 mc.set_multi({‘k1‘:‘v1‘,‘k2‘:‘v2‘}) #批量设置key print(mc.get(‘name‘)) #获取key print(mc.get(‘123‘)) #获取不存在的key,返回None print(mc.get_multi(‘k1‘,‘k2‘)) mc.add(‘age‘,‘22‘) mc.add(‘age‘,‘123‘) #key存在会抱错 mc.replace(‘age‘,‘26‘) #修改key的value mc.replace(‘abc‘,‘26‘) #修改不存在的key,会抱错 mc.delete(‘name1‘) #删除age键值对 mc.delete_multi(‘k1‘,‘k2‘) #删除k1 k2 键值对 mc.append(‘name‘,‘你好‘) #在name的value 的后面加 ‘你好‘ mc.prepend(‘name‘,‘hi‘) #在name的value 的前面加‘hi‘ mc.incr(‘age‘) #age对应的value增加1 mc.decr(‘age‘,10) #age对应的value 减少10 mc.decr(‘name‘) #name的value不能被加减,会抱错
python-memcached模块原生支持集群操作,其原理是在内存维护一个主机列表,且集群中主机的权重值和主机在列表中重复出现的次数成正比
主机 权重
1.1.1.1 1
1.1.1.2 2
1.1.1.3 1
那么在内存中主机列表为:
host_list = ["1.1.1.1", "1.1.1.2", "1.1.1.2", "1.1.1.3", ]
如果用户根据如果要在内存中创建一个键值对(如:k1 = v1
),那么要执行一下步骤:
根据算法将 k1 转换成一个数字
将数字和主机列表长度求余数,得到一个值 N( 0 <= N < 列表长度 )
在主机列表中根据 第2步得到的值为索引获取主机,例如:host_list[N]
连接 将第3步中获取的主机,将 k1 = v1
放置在该服务器的内存中
代码实现如下:
mc = memcache.Client([(‘1.1.1.1:12000‘, 1), (‘1.1.1.2:12000‘, 2), (‘1.1.1.3:12000‘, 1)], debug=True) mc.set(‘k1‘, ‘v1‘)
如果两个客户端同时操作一个key,就会导致数据冲突
如商城商品剩余个数,假设改值保存在memcache中,product_count = 900
A用户刷新页面从memcache中读取到product_count = 900
B用户刷新页面从memcache中读取到product_count = 900
如果A、B用户均购买商品
A用户修改商品剩余个数 product_count=899
B用户修改商品剩余个数 product_count=899
如此一来缓存内的数据便不在正确,两个用户购买商品后,商品剩余还是 899
如果使用python的set和get来操作以上过程,那么程序就会如上述所示情况!
如果采用CAS协议,则是如下的情景。
第一步,A取出product_count=900,并获取到CAS-ID1;
第二步,B取出product_count=900,并获取到CAS-ID2;
第三步,A购买时,修改product_count=899,在写入缓存前,检查CAS-ID与缓存空间中该数据的CAS-ID是否一致。结果是“一致”,就将修改后的带有CAS-ID1的product_count写入到缓存。
第四步,B购买时,修改product_count=899,在写入缓存前,检查CAS-ID与缓存空间中该数据的CAS-ID是否一致。结果是“不一致”,则拒绝写入,返回存储失败。
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
1. 下载Redis 目前,最新的Redist版本为3.0,使用wget下载,命令如下: # wget http://download.redis.io/releases/redis-3.0.4.tar.gz 2. 解压Redis 下载完成后,使用tar命令解压下载文件: # tar -xzvf redis-3.0.4.tar.gz 3. 编译安装Redis 切换至程序目录,并执行make命令编译: # cd redis-3.0.4 # make 执行安装命令 # make install make install安装完成后,会在/usr/local/bin目录下生成下面几个可执行文件,它们的作用分别是: redis-server:Redis服务器端启动程序 redis-cli:Redis客户端操作工具。也可以用telnet根据其纯文本协议来操作 redis-benchmark:Redis性能测试工具 redis-check-aof:数据修复工具 redis-check-dump:检查导出工具 备注 有的机器会出现类似以下错误: make[1]: Entering directory `/root/redis/src‘ You need tcl 8.5 or newer in order to run the Redis test …… 这是因为没有安装tcl导致,yum安装即可: yum install tcl 4. 配置Redis 复制配置文件到/etc/目录: # cp redis.conf /etc/ 为了让Redis后台运行,一般还需要修改redis.conf文件: vi /etc/redis.conf 修改daemonize配置项为yes,使Redis进程在后台运行: daemonize yes 5. 启动Redis 配置完成后,启动Redis: # cd /usr/local/bin # ./redis-server /etc/redis.conf 检查启动情况: # ps -ef | grep redis 看到类似下面的一行,表示启动成功: root 18443 1 0 13:05 ? 00:00:00 ./redis-server *:6379 6. 添加开机启动项 让Redis开机运行可以将其添加到rc.local文件,也可将添加为系统服务service。本文使用rc.local的方式,添加service请参考:Redis 配置为 Service 系统服务 。 为了能让Redis在服务器重启后自动启动,需要将启动命令写入开机启动项: echo "/usr/local/bin/redis-server /etc/redis.conf" >>/etc/rc.local 7. Redis配置参数 在前面的操作中,我们用到了使Redis进程在后台运行的参数,下面介绍其它一些常用的Redis启动参数: daemonize:是否以后台daemon方式运行 pidfile:pid文件位置 port:监听的端口号 timeout:请求超时时间 loglevel:log信息级别 logfile:log文件位置 databases:开启数据库的数量 save * *:保存快照的频率,第一个*表示多长时间,第三个*表示执行多少次写操作。在一定时间内执行一定数量的写操作时,自动保存快照。可设置多个条件。 rdbcompression:是否使用压缩 dbfilename:数据快照文件名(只是文件名) dir:数据快照的保存目录(仅目录) appendonly:是否开启appendonlylog,开启的话每次写操作会记一条log,这会提高数据抗风险能力,但影响效率。 appendfsync:appendonlylog如何同步到磁盘。三个选项,分别是每次写都强制调用fsync、每秒启用一次fsync、不调用fsync等待系统自己同步
python操作redis
安装redis模块
pip install redis
单连接
使用redis.Redis()方法,直接和redis建立连接,操作完成之后,连接释放
import redis r = redis.Redis(host=‘127.0.0.1‘, port=6379) r.set(‘foo‘, ‘Bar‘) print(r.get(‘foo‘))
import redis pool = redis.ConnectionPool(host=‘127.0.0.1‘, port=6379,) r = redis.Redis(connection_pool=pool) r.set(‘foo1‘, ‘Bar‘) print(r.get(‘foo1‘))
字符串存储操作
存储形式:
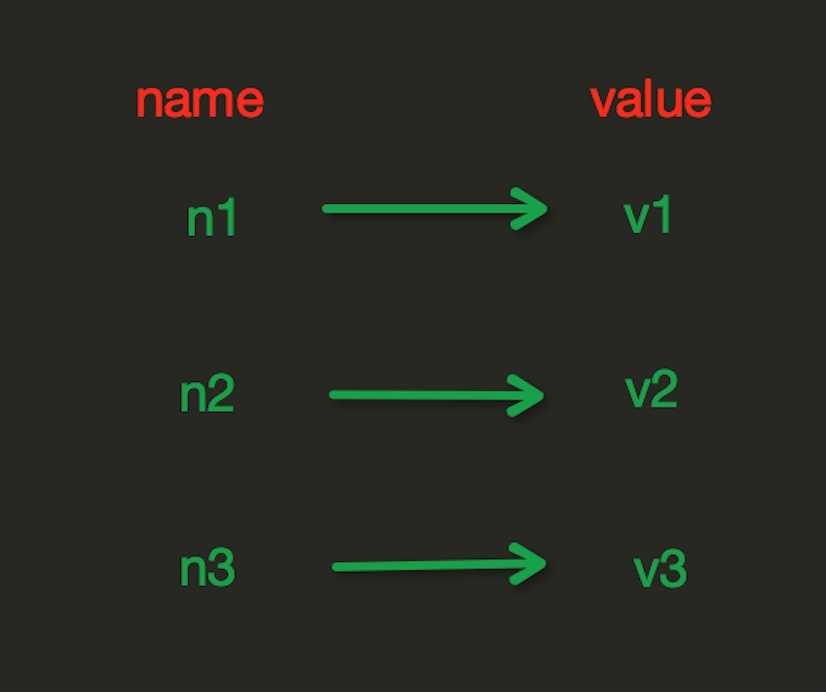 ?
?
set(name, value, ex=None, px=None, nx=False, xx=False)
参数:
name:key的名称
value:key的值
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,当前set操作才执行
setnx(name, value) 设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time) 设置值,同时支持设置过期时间,单位:秒s
psetex(name, time_ms, value) 设置值,同时支持设置过期时间,单位:毫秒ms
mset(*args, **kwargs) 批量设置值 ,支持 字典形式{‘k1‘:‘v1‘,‘k2‘:‘v2‘}和key=value形式k1=v1,k2=v2
get(name) 获取key的value
mget(keys, *args) 批量获取值 支持k1,k2,k3形式和[k1,k2]形式
getset(name, value) 获取原来的值,并设置新的值
getrange(key, start, end) 获取指定key的value的子序列 start和end为value的起始位置
setrange(name, offset, value) 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加),offset,字符串的索引,字节(一个汉字三个字节),value,要设置的值
setbit(name, offset, value) 对name对应值的二进制表示的位进行操作,offset,字符串的索引,字节(一个汉字三个字节),value,要设置的值
getbit(name, offset) 获取name对应的值的二进制表示中的某位的值 (0或1)
bitcount(key, start=None, end=None) 获取name对应的值的二进制表示中 1 的个数
bitop(operation, dest, *keys) 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
参数:
operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
dest, 新的Redis的name
*keys,要查找的Redis的name
strlen(name) 返回name对应值的字节长度(一个汉字3个字节)
incr(name, amount=1) 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增 ,amount必须为整数
incrbyfloat(name, amount=1.0) 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增,amount为浮点数
decr(name, amount=1) 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减
decrbyfloat(name, amount=1.0) 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减,amount为浮点数
append(key, value) 在redis name对应的值后面追加内容
用法示例:

import redis pool = redis.ConnectionPool(host=‘127.0.0.1‘, port=6379,) r = redis.Redis(connection_pool=pool) r.set(‘k1‘,‘v1‘,ex=2) r.setnx(‘k2‘,‘v2‘) #设置k1 v1 r.mset({‘k3‘:‘v3‘,‘k4‘:‘v4‘}) #批量设置kv print(r.get(‘k1‘)) #获取k1的value print(r.mget([‘k2‘,‘k3‘])) #批量获取k2,k3 print(r.getset(‘k2‘,‘v22‘)) #获取k2的值,并将k2的值设置为v22 print(r.get(‘k2‘)) print(r.getrange(‘k2‘,1,2)) #获取k2的value的子序列1-2,默认从0开始 r.setrange(‘k4‘,2,‘12313‘) print(r.get(‘k4‘)) print(r.strlen(‘k4‘)) #获取k4的value长度 r.set(‘k5‘,‘123‘) r.incr(‘k5‘,10) #设置k5的值自增10 r.append(‘k5‘,‘元‘) #在k5的值后面追加元 print(r.get(‘k5‘).decode())
hash存储操作
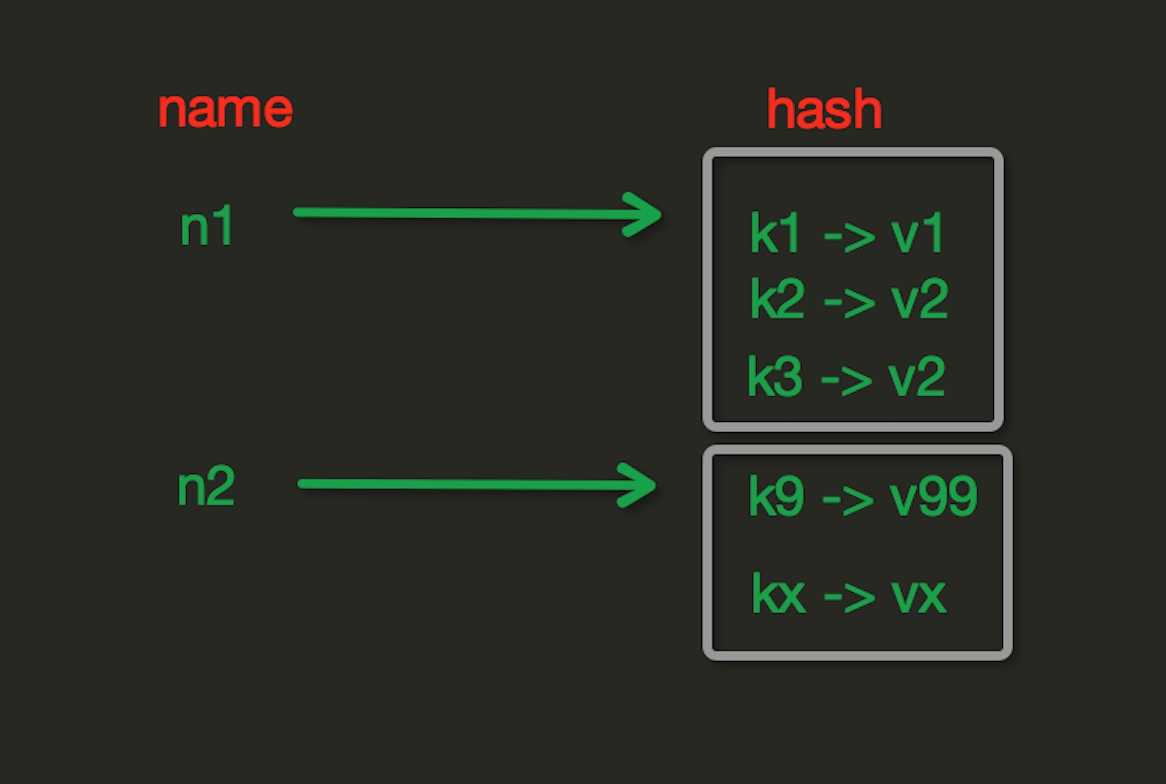 ?
?
hscan(name, cursor=0, match=None, count=None) 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
参数:
name,redis的name
cursor,游标(基于游标分批取获取数据)
match,匹配指定key,默认None 表示所有的key
count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
hscan_iter(name, match=None, count=None) 利用yield封装hscan创建生成器,实现分批去redis中获取数据
参数:
match,匹配指定key,默认None 表示所有的key
count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
pool = redis.ConnectionPool(host=‘127.0.0.1‘, port=6379,) r = redis.Redis(connection_pool=pool) r.hset(‘k1‘,‘hk1‘,‘hv1‘) #设置k1 对应的键值对 hk1 hv1 print(r.hget(‘k1‘,‘hk1‘)) #获取k1下的对应键值对hk1的值 r.hmset(‘k22‘,{‘hk2‘:‘hv2‘,‘hhk2‘:‘hhv2‘}) print(r.hmget(‘k22‘,[‘hk2‘,‘hhk2‘])) print(r.hgetall(‘k22‘)) #返回一个字典 print(r.hlen(‘k22‘)) #获去k22对应的键值对个数 print(r.hkeys(‘k22‘)) #获取k22对应键值对的keys print(r.hvals(‘k22‘)) #获取k22对应键值对的values print(r.hexists(‘k22‘,‘jkkk‘)) #判断k22对应键值对中是否存在jkkk的key 返回True和False
list存储操作
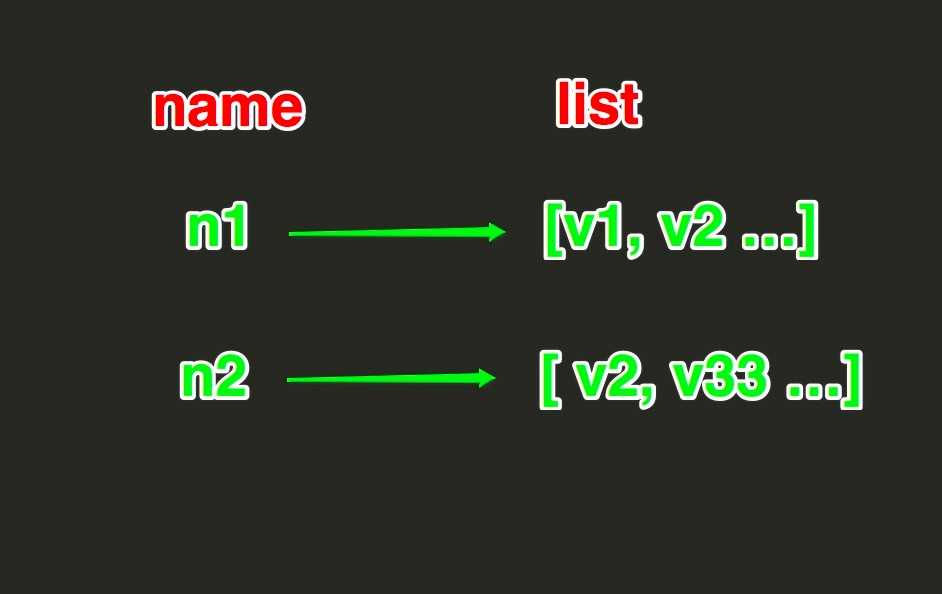 ?
?
linsert(name, where, refvalue, value)) 在name对应的列表的某一个值前或后插入一个新值
参数:
name,redis的name
where,BEFORE或AFTER
refvalue,标杆值,即:在它前后插入数据
value,要插入的数据
lset(name, index, value) 对name对应的list中的某一个索引位置重新赋值
参数:
name,redis的name
index,list的索引位置
value,要设置的值
lrem(name, value, num) 在name对应的list中删除指定的值
参数:
name,redis的name
value,要删除的值
num, num=0,删除列表中所有的指定值;
num=2,从前到后,删除2个;
num=-2,从后向前,删除2个
lpop(name) 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
rpop(name) 表示从右向左操作
lindex(name, index) 在name对应的列表中根据索引获取列表元素
lrange(name, start, end) 在name对应的列表分片获取数据
ltrim(name, start, end) 在name对应的列表中移除没有在start-end索引之间的值
rpoplpush(src, dst) 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边,src,要取数据的列表的name,dst,要添加数据的列表的name
blpop(keys, timeout) 将多个列表排列,按照从左到右去pop对应列表的元素
参数:
keys,redis的name的集合
timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞;r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0) 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:
src,取出并要移除元素的列表对应的name
dst,要插入元素的列表对应的name
timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要: # 1、获取name对应的所有列表 # 2、循环列表 # 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能: def list_iter(name): """ 自定义redis列表增量迭代 :param name: redis中的name,即:迭代name对应的列表 :return: yield 返回 列表元素 """ list_count = r.llen(name) for index in xrange(list_count): yield r.lindex(name, index) # 使用 for item in list_iter(‘pp‘): print item
pool = redis.ConnectionPool(host=‘127.0.0.1‘, port=6379,) r = redis.Redis(connection_pool=pool) # 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 r.lpush("k11",2) r.lpush("k11",3,4,5)#保存在列表中的顺序为5,4,3,2 r.rpush(‘k11‘,0) #从右边添加 r.lpushx(‘k11‘,‘abc‘) #从左边添加元素,切name必须存在 print(r.llen(‘k11‘)) #打印k11对应的列表长度 print(r.lrange(‘k11‘,0,r.llen(‘k11‘))) #获取k11对应的列表所有值 print(r.lindex(‘k11‘,0)) #根据索引去值 print(r.lpop(‘k11‘)) #移除第一个元素,并返回 r.ltrim(‘k11‘,0,5) #删除索引0-5之外的值 print(r.lrange(‘k11‘,0,-1))
set集合存储操作
Set集合就是不允许重复的列表
sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)
同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
用法举例:
pool = redis.ConnectionPool(host=‘127.0.0.1‘, port=6379,) r = redis.Redis(connection_pool=pool) r.sadd("k12","aa") r.sadd("k12","aa","bb",‘123‘) #往k12对应的集合添加元素 r.sadd("k13","aa","bb",‘cc‘,‘00‘) #往k12对应的集合添加元素 print(r.smembers(‘k12‘)) #获取对应的集合的所有成员 print(r.scard(‘k12‘)) #获取k12对应集合元素的个数 print(r.sdiff(‘k12‘,‘k13‘)) #比较k12中不在k13 的元素 r.sdiffstore(‘k123‘,‘k12‘,‘k13‘) #比较k12中不在k13 的元素 ,并将结果添加到k123中 print(r.smembers(‘k123‘)) print(r.sinter(‘k12‘,‘k13‘)) #取k12和k13的并集 print(r.sismember(‘k12‘,‘555‘)) #判断555是否是k12的元素 r.smove(‘k12‘,‘k13‘,‘123‘) #将k12下的123移动到k13 print(r.smembers(‘k12‘)) print(r.smembers(‘k13‘))
有序集合存储操作
在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
# 按照索引范围获取name对应的有序集合的元素 # 参数: # name,redis的name # start,有序集合索引起始位置(非分数) # end,有序集合索引结束位置(非分数) # desc,排序规则,默认按照分数从小到大排序 # withscores,是否获取元素的分数,默认只获取元素的值 # score_cast_func,对分数进行数据转换的函数 # 更多: # 从大到小排序 # zrevrange(name, start, end, withscores=False, score_cast_func=float) # 按照分数范围获取name对应的有序集合的元素 # zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float) # 从大到小排序 # zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员 # 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大 # 参数: # name,redis的name # min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间 # min,右区间(值) # start,对结果进行分片处理,索引位置 # num,对结果进行分片处理,索引后面的num个元素 # 如: # ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga # r.zrangebylex(‘myzset‘, "-", "[ca") 结果为:[‘aa‘, ‘ba‘, ‘ca‘] # 更多: # 从大到小排序 # zrevrangebylex(name, max, min, start=None, num=None)
使用举例:
pool = redis.ConnectionPool(host=‘127.0.0.1‘, port=6379,) r = redis.Redis(connection_pool=pool) r.zadd("k999", "a1", 6, "a2", 2,"a3",5) #往k999有序集合中添加值 #或 r.zadd(‘k888‘, b1=10, b2=5) print(r.zcard(‘k999‘)) #获取k999的元素个数 print(r.zcount(‘k999‘,4,6)) #获取k999中分数在4-6之间的元素个数 r.zincrby(‘k999‘,‘a1‘,10) #自增k999中a1的分数 print(r.zrevrank(‘k999‘,‘a3‘)) #获取a3的分数在k999所有元素的排行,默认从0开始
import redis import time pool = redis.ConnectionPool(host=‘203.130.45.173‘, port=6379,) r = redis.Redis(connection_pool=pool) def without_pipeline(): for i in range(1000): r.ping() return def with_pipeline(): pipeline=r.pipeline() for i in range(1000): pipeline.ping() pipeline.execute() return def bench(desc): start=time.clock() desc() stop=time.clock() diff=stop-start print("%s has token %s" % (desc.__name__,str(diff))) bench(without_pipeline) #不使用管道 bench(with_pipeline) #使用管道
输出结果:发现差别很大,不使用管道耗时将近是使用管道的10倍 without_pipeline has token 0.349842 with_pipeline has token 0.03180000000000005
标签:
原文地址:http://www.cnblogs.com/pycode/p/cache.html
