标签:
什么是缓存:
缓存是介于应用程序和物理数据源之间,缓存内的数据是对物理数据源中的数据的复制,其作用是为了降低应用程序对物理数据源访问的频次,从而提高了应用的运行性能。
1.缓存的范围:
1.1 事务范围:缓存只能被当前事务访问。缓存的生命周期依赖于事务的生命周期,当事务结束时,缓存也就结束生命周期。在此范围下,缓存的介质是内存。事务可以是数据库事务或者应用事务,每个事务都有独自的缓存,缓存内的数据通常采用相互关联的的对象形式。
1.2进程范围:缓存被进程内的所有事务共享。这些事务有可能是并发访问缓存,因此必须对缓存采取必要的事务隔离机制。缓存的生命周期依赖于进程的生命周期,进程结束时,缓存也就结束了生命周期。进程范围的缓存可能会存放大量的数据,所以存放的介质可以是内存或硬盘。缓存内的数据既可以是相互关联的对象形式也可以是对象的松散数据形式。松散的对象数据形式有点类似于对象的序列化数据,但是对象分解为松散的算法比对象序列化的算法要求更快。
1.3 集群范围:在集群环境中,缓存被一个机器或者多个机器的进程共享。缓存中的数据被复制到集群环境中的每个进程节点,进程间通过远程通信来保证缓存中的数据的一致性,缓存中的数据通常采用对象的松散数据形式。
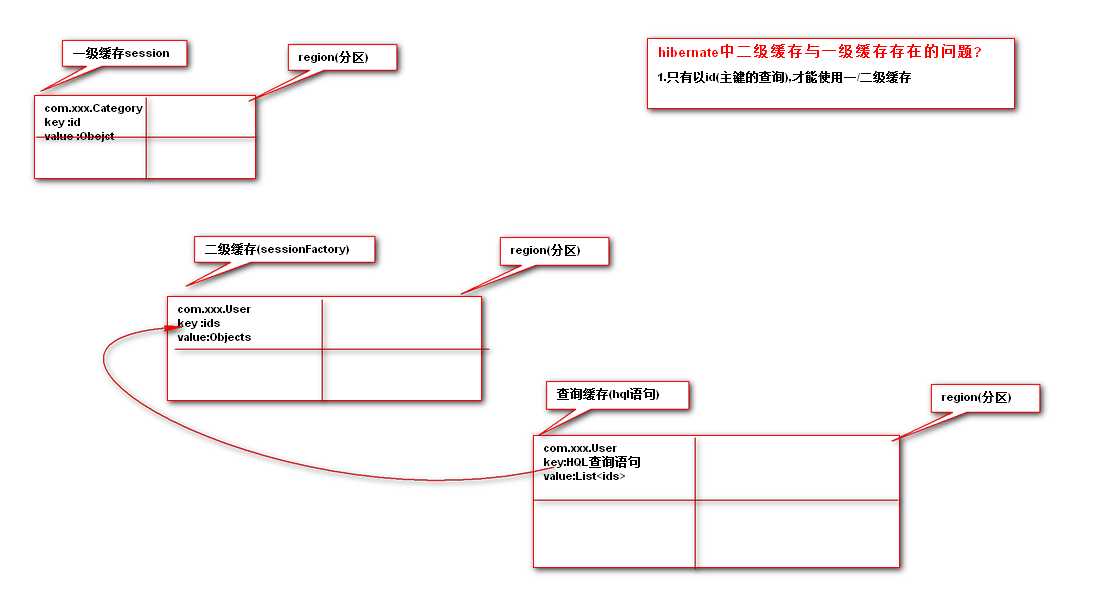
2.Hibernate:一级缓存
:缓存位置:session中
:生命周期:一个事务中。
:缓存规格:{ID:实体}
:默认开启
2.1 何时数据会进入缓存:事务中加载过的数据,都会进入缓存,并以{ID:实体}存储在session中。
2.2 何时可以检查缓存:以ID为条件的查询可以检查缓存。
*session.get();//可以检查
*Query.list();//不能检查
.uniqueResult();//不能检查
.iterate();//可以检查
*细节:iterate()运作流程
String hql="from User u where u.name=?";
Query.iterate(hql);
1>保留查询条件,到数据库中查询ID,
select id from t_user where t_name=?
[1,2,3,4,5]
2>通过查到的ID去检查缓存。如果有缓存可用,则不用再查询数据库。
但是,注意,如果没有缓存可用,则要再次发起对数据库的查询:
select * from t_user where t_id=5;
select * from t_user where t_id=4;
select * from t_user where t_id=3;
select * from t_user where t_id=2;
select * from t_user where t_id=1;
综上,再使用iterate()方法时,可能导致n+1次查询问题。n=满足条件的数据行数。
3>使用:
Iterator it=query2.iterate();
while(it.hasNext()){
User user=(User)it.next();
System.out.println(user);
}
=====================================================================================================
3.hibernate:二级缓存
:缓存位置:SessionFactory中
:生命周期:全局可用
:缓存规格:{ID:实体}
:默认关闭:通过配置开启。
:*开启二级缓存
<!-- 开启二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!-- 二级缓存类别:EhCache,OSCache,JbossCache -->
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
*导包 并 引入ehcahe.xml
*为要进入二级缓存的实体,增加权限。
//只读缓存权限
//@Cache(usage=CacheConcurrencyStrategy.READ_ONLY)
//读写缓存权限
@Cache(usage=CacheConcurrencyStrategy.READ_WRITE)
3.1 何时数据会进入缓存:事务中加载过的数据,都会进入缓存,并以{ID:实体}存储在session中。
3.2 何时可以检查缓存:以ID为条件的查询可以检查缓存。
get();
iterate();
=====================================================================================================
4.hibernate: 查询缓存:依赖二级缓存
: 缓存位置:SessionFactory中
: 生命周期:全局可用,但不稳定,如果和缓存数据相关的表有任何的改动,则缓存数据失效,在一般的应用程序中,sessionfactory会以单例的形式存在,所以在整个应用程序的生命周期里,sessionfactory会一直存在。既二级缓存也一直存在直到关闭应用程序
: 缓存规格: {hql:查询结果(字段)}
: 默认关闭:<property name="hibernate.cache.use_query_cache">true</property>
在查询前://本次查询要使用查询缓存
query.setCacheable(true);
4.1 何时数据会进入缓存:用hql查询字段的查询结果,都可以进入查询缓存:{HQL:结果(字段)}
4.2 何时可以检查缓存:只要再次用同样的hql查询,则可以检查查询缓存。
4.3 使用场景
什么样的数据适合存放到第二级缓存中?
1、很少被修改的数据
2、不是很重要的数据,允许出现偶尔并发的数据
3、不会被并发访问的数据
4、参考数据
不适合存放到第二级缓存的数据?
1、经常被修改的数据
2、财务数据,绝对不允许出现并发
3、与其他应用共享的数据。
*细节:如果查询的实体,则查询缓存只能缓存:{HQL:实体的ID字段}
=====================================================================================================
5.缓存总结:
5.1 缓存规格:
*一级缓存,二级缓存,缓存的是实体:{ID:实体}
session.get(User.class,1);
"from User u";
*查询缓存:{HQL:查询结果}
tx
"select u.id,u.age from User u";
commit();
5.2 使用:
*如果查询时是查询字段的话:select a,b,c,d from XXX;
查询缓存足矣。
*如果查询时是查询实体的话:from User u;
二级缓存+查询缓存。
5.3 查询缓存和二级缓存的联合使用:
*如果查询时是查询实体的话:from User u;
初次query.list();时,检查查询缓存,没有可用数据,则转向数据库,获得一个实体User,
将{HQL:User的ID}存入查询缓存,将{User的ID:User}存入二级缓存
再次query.list();时,检查查询缓存,获得缓存数据:User的ID,通过UserID检查二级缓存,
如果有数据,则直接使用,否则以各个ID为条件分别发起查询
================================================================================================
6. 为什么这样设计
一般情况下,我们查询的数据一般是实时的,使用二级缓存肯定不行,使用一级缓存既利用了缓存又不会影响实时。使用二级缓存是为了存储一些比较稳定的数据,二级缓存策略,是针对于ID查询的缓存策略,对于条件查询则毫无作用。为此,Hibernate提供了针对条件查询的Query缓存。
==================================================================================================
7.图解缓存
分区:是以全类名为单位分区
标签:
原文地址:http://www.cnblogs.com/liuconglin/p/5693846.html