标签:
一:概述
在实际中,经常需要用到字符串的模式匹配处理。即在指定文本串中定位指定的模式串,统计所有与模式串的偏移位置情况。而解决该问题的算法也有许多种,最为普通的算法莫过于“朴素匹配算法”。如果构成字符串的有限字符集全为数字类型的字符,则还可以考虑R-K匹配算法(即:Rabin & Karp提出的匹配算法)或有限自动机匹配算法。但相信在更多情况下,我们会选择KMP算法。
二:术语
T[1..n] 表示:长度为 n 个字符组成的字符串。可理论为源字符串、被匹配字符串。下面统一称为:文本串
P[1..m] 表示:长度为 m 个(m <= n)字符组成的字符串。下面统一称为:模式串
T.length 表示:文本串的长度。下面统一指上面的 n
P.length 表示:模式串的长度。下面统一指上面的 m
三:朴素匹配算法
朴素匹配算法算是最直接、最傻瓜式的字符串查找匹配算法。
思想:从 T[1..n] 的第 1 个字符到第 n - m + 1 个字符的第个位置 q 处,每次比较 T[q..q + m - 1] 的子串是否与 P[1..m] 模式串匹配。如果匹配成功,则 q 即为当次匹配成功的偏移位置。
时间复杂度:T(n) = O(f(n)) = O((n - m + 1) * m)。最坏情况下,当 m = 时,算法的时间复杂度为:O(
)。
算法的编码参考如下:

1 namespace string_match 2 { 3 4 // 5 // naive string matcher algorithm. 6 void naiveStringMatcher(const char cszText[/*nTextLen*/], const int nTextLen, const char cszPattern[/*nPatternLen*/], const int nPatternLen) { 7 // 8 // do something here like valid all parameters. 9 // 10 const auto nCompareMax = nTextLen - nPatternLen; 11 auto nPatternIndex = 0; 12 for (auto nTextIndex = 0; nTextIndex < nCompareMax; ++nTextIndex) { 13 for (nPatternIndex = 0; nPatternIndex < nPatternLen && cszText[nTextIndex + nPatternIndex] == cszPattern[nPatternIndex]; ++nPatternIndex); 14 if (nPatternIndex == nTextLen) { 15 printf("match pos offset: %d", nTextIndex); 16 } 17 } 18 } 19 20 }//namespace string_match
四:KMP字符串匹配算法
朴素字符串匹配算法是中规中矩地按顺序逐个位置处进行匹配检查,所以其效率低下。而KMP的漂亮之处是在于其能充分分析并利用模式串的信息来加快匹配检测速度,下面全面解析KMP算法相关细节。
以下假设
字符串:T[1..n] = bacbababaabcbab 即:此时 n = 15,并且当前处理到的下标记为 s
模式串:P[1..m] = ababaca 即:此时 m = 7,并且当前已比较到的字符下标记为 q
探讨:模式串
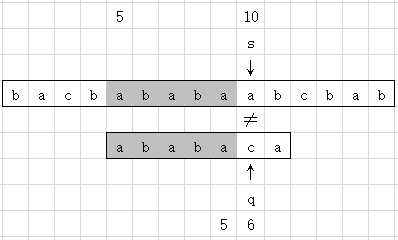
由上图已经明确 T[5..9] = P[1..5] 这5个字符已经匹配成功,但T[10] P[6]。因此,如果按朴素匹配算法,则下一轮比较循环,应该是从T[6]开始后的逐个字符与模式串P[1]开始的逐个字符一一比较,查看是否匹配成功。这也是朴素匹配算法效率低下的原因,因为每次循环时T串的当前偏移量s又重新倒退回去了(如该示例的当前这种情况就从s=10倒退到s=6了)。而在KMP算法中,T串指针s从不倒退,并且每次s前进时,P串的比较也不一定都是从第一个字符P[1]开始与T[s]进行比较的,从而其效率极其高效。它是如何做到这点的?
注意,请一定认真看懂接下来这段内容的每一句,看懂了这些,就明白KMP的一切秘密(其实也没那么神秘)。
由上图可知已经明确 P[1..q - 1] 是匹配的了,但由于 P[q] 不匹配,所以导致前面的 P[1..q - 1] 不得不放弃掉。不过,此时我们可以尝试在前面已经匹配的 P[1..q - 1] 中找到一个最大的k位置(明显的 1 k
q),注意:是最大的,使得
P[1..k] = T[s - k, s - 1] = P[q - k, q - 1] (即:P串的最长的前k个长度的前缀与k长度的后缀匹配)
只要找到这样的k位置,则我们可以得到结论:此时对于字符串 T 仍可以直接从 s 处开始继续往下匹配比对,对于模式串 P 可直接从 q = k 位置处继续往下匹配比对。如下图所示。(注意:下面3幅图如果看不明白,请结合图后面的内容一起理解即可。)
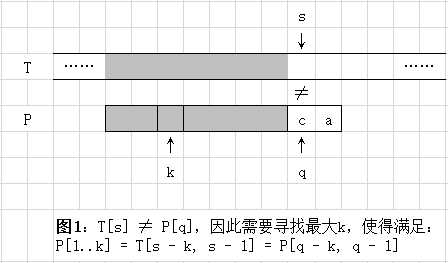
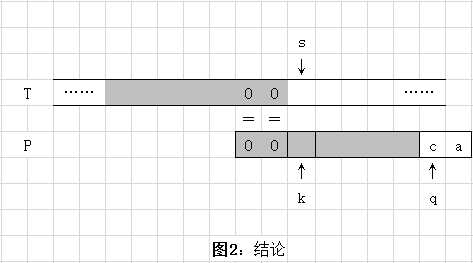
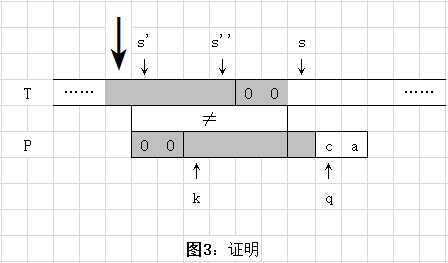
上面图1,仅假如已经找到符合条件的最大位置k(位置如图所示),因此,将 P 串往后移使得k与s位置对齐,得到图2。注意:图2中已经标明找到的最大k位置后,且所有匹配的字符位置都用 O 符号标注。因此,图1可不用太过操心。下面通过图2及图3证明前面结论的正确性。
先看图3,最粗的黑箭头表示原先s的起始位置,因为从该位置开始,一直到上图3中的s-1位置全都匹配,到图3的s位置时,发现不匹配。所以按朴素匹配算法,s需要后移一格,到了图3的s‘位置。非常明显的s‘位置可以不用比较了。因为图3中的 部分的字符串,明显是不可能匹配的,如果它们会匹配,则就违背了前面说的 k 是最大值了(即:如果这部分字符串会匹配,则k的位置就不是图1、图2、图3中的位置了),也就是说上图1、图2、图3中的匹配的字符,就不止图中标有 O 符号的那几个了。同理,一直从 s‘ 到 s‘‘ 位置的所有位置都不需要比较。
再接下来 s 的位置将要移到 s‘‘ 的下一个位置,即:s = s‘‘ + 1 位置处来比较匹配。因为从 s‘‘ + 1 位置到图3中的s位置,前面已经说明其与 P[1..k] 是匹配的,所以从 s‘‘ + 1 一直到 s 位置也全都不需要比较,可直接跳过,因为这时候其实就是图2的情况。所以只要找到了最大k位置,则 T 字符串就可以直接从 s 位置开始、P 字符串可直接从 k 位置开始进行继续后面的匹配了。于是前面结论得证。
因此,一切问题集中于:如何在模式串中,确定任意位置的最大可匹配的前、后缀的长度值k。其实这就是KMP算法中的另一个神秘地带:next数组!
探讨:next数组

根据前文所述,next数组是指这样一个数组:其长度与模式串P一样长,且next数组的所有元素都是数字,其每个位置处的数字所代表的意义是模式串中对应位置处字符的最大可匹配前缀、后缀的长度值k。如上图示,next数组中的 y1、y2、y3、... 全都是数值,且y1表示的是x1的最大可匹配前、后缀的长度;y2、y3分别代表x2、x3的最大可匹配前、后缀的长度。
并且由前文也已经分析,KMP算法现在最重要的问题就在于如何确定模式串中的next数组。即:我们需要如何生成这个next数组。请看下图:
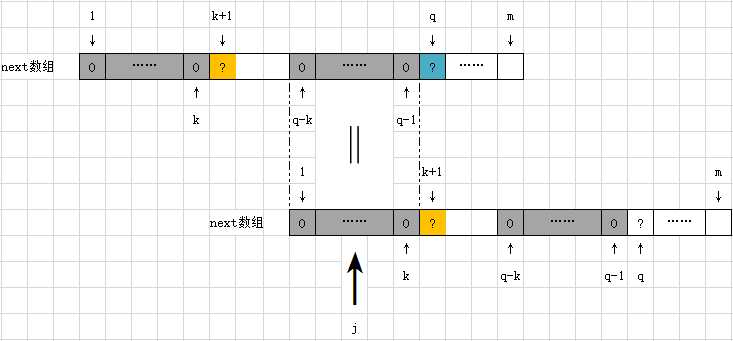
KMP算法之next数组生成细节:
next的长度与模式串一样,因此,next数组为:next[1..m]。(注意:我们这边的下标统一都是以1开始,但在真正实现时,不同语言可能起始下标会不同。如C/C++语言,下标就是从0开始)。
01.第一个元素值直接设置为0。因为第一个永远不可能有相同的前、后缀这一说法,而且对于模式串的任何位置的最大可匹配前、后缀长度值必需小于该位置下标值。所以 next[1] = 0;
02.对于除 next[1] 以外的任何位置 q,它的 next[q] = ?既然分析到 q 位置,则 q 之前的 q - 1 个字符中的任何一个字符的最大可匹配前、后缀长度值就都已经分析过,所以它们的数值都已经明确。即:next[1]、next[2]、...、next[q - 1] 的值都已知。假如 next[q - 1] = k,即:P的前 q - 1 个字符中的最大可匹配前、后缀长度为k,如上图所示。则当前 q 位置的最大可匹配长度值为:
a) 如果 P[k + 1] = P[q],则 q 的最大可匹配前、后缀值为 P[q] = K + 1;
b) 如果 P[k + 1] P[q],则此时就只能再次放弃 k 这个长度值,必需要再次在前 k 个字符中,再次找到一个新的最大可匹配位置 j (1
j < k),使得满足 P[1..j] = P[q - j..q - 1]。而我们其实是知道 j 的值 j = next[k] (注意、注意:其实这时的 j 就相当于 k 的角色)。于是,当前 q 位置的最大可匹配长度值为:
c) 如果 P[j + 1] = P[q],则 q 的最大可匹配前、后缀长度为 P[q] = j + 1;
d) 如果 P[j + 1] P[q],则又得再次放弃前 j 这个长度值,必需要再次在前 j 个字符串,找最大可匹配位置。这其实就是一直在重复 02 步骤,其实就是一个递归的过程。我们要一直到找到这样一个 j 位置:使得 P[j + 1] = P[q] 为止或者直到 j = 1 为止。
下面用C++语言作为描述next数组生成细节的总结:
1 void makeNext(const char P[/*m*/], const int m, int next[/*m*/]) { 2 next[0] = 0; // !!!note: 01.C++中,数组下标是从0开始的. 3 for (auto q = 1, k = 0; q < m; ++q) { 4 for (; k > 0 && P[q] != P[k]; k = next[k - 1]); // !!!note: 01.这边 P[q] 不是与 P[k + 1] 比较,因为C++中,数组下标是从0开始的. 5 // 02.这个for循环其实相当于下面这下写法(如果想要调试具体细节,可使用 6 // 语句代替).只是前面这种写法更为简洁. 7 // 写法二: 8 // for (; k > 0 && P[q] != P[k];) 9 // k = next[k - 1]; 10 // 写法三: 11 // while (k > 0 && P[q] != P[k]) 12 // k = next[k - 1]; 13 14 next[q] = (P[q] == P[k]) ? ++k : k; // !!!note: 01.该语句其实如果按前面文章介绍的,是相当于下面的语句,只是这种写法更为简洁 15 // if (P[q] == P[k]) 16 // ++k; 17 // next[q] = k; 18 } 19 }
至此,KMP算法的所有奥秘已经全部解开。
五:实现
根据前文介绍,KMP算法实现起来就不难了。下面以C++语言实现,实际编码参考如下:
1 void makeNext(const char P[/*m*/], const int m, int next[/*m*/]) { 2 next[0] = 0; // !!!note: 01.C++中,数组下标是从0开始的. 3 for (auto q = 1, k = 0; q < m; ++q) { 4 for (; k > 0 && P[q] != P[k]; k = next[k - 1]); // !!!note: 01.这边 P[q] 不是与 P[k + 1] 比较,因为C++中,数组下标是从0开始的. 5 // 02.这个for循环其实相当于下面这下写法(如果想要调试具体细节,可使用 6 // 语句代替).只是前面这种写法更为简洁. 7 // 写法二: 8 // for (; k > 0 && P[q] != P[k];) 9 // k = next[k - 1]; 10 // 写法三: 11 // while (k > 0 && P[q] != P[k]) 12 // k = next[k - 1]; 13 14 next[q] = (P[q] == P[k]) ? ++k : k; // !!!note: 01.该语句其实如果按前面文章介绍的,是相当于下面的语句,只是这种写法更为简洁 15 // if (P[q] == P[k]) 16 // ++k; 17 // next[q] = k; 18 } 19 } 20 21 void kmpMatcher(const char T[/*n*/], const int n, const char P[/*m*/], const int m) { 22 if (n <= 0 || m <= 0) { 23 return; 24 } 25 int* next = new int[m]; 26 if (nullptr == next) { 27 return; 28 } 29 makeNext(P, m, next); 30 for (auto q = 0, k = 0; q < n; ++q) { 31 for (; k > 0 && T[q] != P[k]; k = next[k - 1]); // !!!note: 01.这边 T[q] 不是与 P[k + 1] 比较,因为C++中,数组下标是从0开始的. 32 // 02.这个for循环其实相当于下面这下写法(如果想要调试具体细节,可使用 33 // 语句代替).只是前面这种写法更为简洁. 34 // 写法二: 35 // for (; k > 0 && T[q] != P[k];) 36 // k = next[k - 1]; 37 // 写法三: 38 // while (k > 0 && T[q] != P[k]) 39 // k = next[k - 1]; 40 if (T[q] == P[k]) { 41 ++k; 42 } 43 if (k == m) { 44 //printf("the match position offset: %d", q - m + 1); 45 CCLOG("the match position offset: %d", q - m + 1); 46 } 47 } 48 49 delete[] next; 50 next = nullptr; 51 } 52 53 void testKMP() { 54 auto T = "abcabcabccabacaabc"; 55 auto P = "abcc"; 56 const auto n = strlen(T); 57 const auto m = strlen(P); 58 kmpMatcher(T, n, P, m); 59 }
标签:
原文地址:http://www.cnblogs.com/tongy0/p/5682646.html
