标签:
主从不一致性的3种可能原因
1、binlog format是不是row
2、session级关闭binlog
3、人工在slave修改数据
set sql_log_bin=0
session级别关闭binlog,有可能导致主从不一致
kill 实例很久都没有停下来,查看error log并发出来
kill -9
查看 show engine innodb status undo是否太大
查看三个表innodb_trx 、 innodb_locks 、 innodb_lock_waits
mysql5.7
innodb_status_output=1
innodb_status_output_locks=1
相当于开了mysql5.5 的innodb_lock_monitor
死锁
innodb_print_all_deadlocks=1
无法打印涉及死锁的两个sql的整个事务里的语句无法打印出来,只能打印sql
20课:InnoDB引擎
1、避免行溢出,每行平均长度最好不高于8KB,针对page size是16KB
2、5.6及以上版本,最好使用独立undo表空间
3、共享表空间初始化时稍微大一些,比如1GB
使用独立表空间设置
innodb_file_per_tables=1
4、不用compressed行格式,压缩带来性能有限,使用dynamic行格式
5、少用select * text、blob
6、innodb表最好使用自增类型列做主键
7、innodb_flush_log_at_trx_commit
0,事务提交时不将redo log buffer写入磁盘
1,事务提交时将redo log buffer写入磁盘
2,事务提交时仅将redo log buffer写入操作系统缓存
通常建议设置为1,并且设置sync_binlog=1,以保证数据可靠性
8、innodb_log_file_size ib_logfile* 一般设置为512MB – 4GB
purge 线程
删除辅助索引中不存在的记录
删除已被打了delete-marked标记的记录
删除不再需要的undo log
从5.6开始,将purge thread独立出来
--innodb_purge_threads = 1 5.6只能有一个,5.7可以设置多个
--innodb_max_purge_lag = 0
--innodb_purge_batch_size = 300
除非unpurge的list太大了,否则没必要调整,增大innodb_purge_batch_size
show engine innodb status里的History list length(unpurge的list)
select min(userid) from t 很慢 锁等待,等待delete会话提交事务,释放排他锁
select max(userid) from t 很快
背景事件:删除大量数据后
背景:删除大量旧数据后
delete from t where pkid<3000万 order by pkid
后续逐渐清理
max不影响
采用小步快跑
扫描history list,确认每个记录对应的事务版本号,在其他事务中,是否还需要被用到

innodb的purge过程
update_undo产生的日志会放到history list中,当这些旧版本无人访问时
需要进行清理操作
另外页面进行标记删除操作也需要从物理上清理掉
后台purge线程负责这些工作
具体过程
确认可见性(创建readview,类似基准点)
确认需要purge的记录(确认哪些是旧事务,可purge的)
执行purge
清理history list,释放undo segment
insert buffer/change buffer
作用是
将非唯一辅助索引上的IUD操作从随机I/O变成顺序I/O,提高I/O效率
工作机制
先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入
若不在,则先放入到一个Insert Buffer对象中
当读取辅助索引页到缓冲池,将insert buffer中的记录合并到辅助索引页
相关的2个选项:
--innodb_change_buffer_max_size 默认为 25%
--innodb_change_buffering 默认为all (insert\delete\purge\change\all\none)
show engine innodb status里查看下
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 1289, seg size 1291, 316623 merges
merged operations:
insert 249806, delete mark 1123127, delete 85482
--seg size:当前插入缓冲区的大小 1291*16KB
-- insert buffer的效果 = merges / (insert + delete mark + delete)= 316623 / (249806+1123127+85482)= 21.71%
-- size 1 => 正在使用的page
-- free list len 1289 => 空闲的page
-- seg size => size + (free list len + 1) = 1 + (1289 + 1) = 1291
double write buffer,双写
innodb存在partial write问题
目的/作用:保证数据写入的可靠性
防止数据页损坏,又无从修复
因为InnoDB有partial write问题
16K的页只写入了部分数据时发生crash
redo里记录的是逻辑操作,不是物理块,无法通过redo log恢复 crash recovery
操作系统的block是4KB,innodb页面是16KB,那么需要4次IO才能写入一个完整的页面
怎么解决partial write问题
双写,doublewrite
2个1M的空间,共2M(既有磁盘文件,也有内存空间)
页在写入时首先顺序地写入到doublewrite
然后再刷新回磁盘
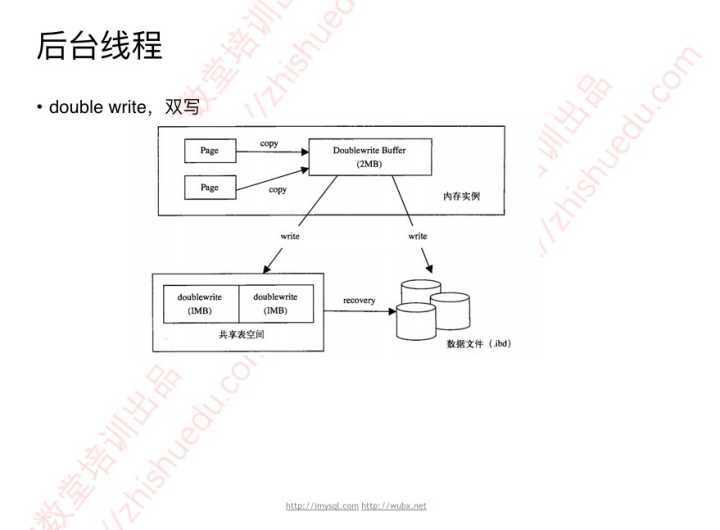
double write
性能损失
double write写入是顺序的,性能损失很小
slave上可关闭
btrfs,zfs文件系统支持原子写,不用打开double write
ssd等支持原子写的存储设备不用打开double write
innodb_doublewrite=0
status
innodb_dblwr_pages_written
innodb_dblwr_writes
innodb_dblwr_pages_written:innodb_dblwr_writes=64:1(一次刷新64个脏页),当系统写入压力并不是很高时,应小于64:1
adaptive hash index(AHI)
目的:提高buffer pool的检索效率
buffer pool本身其实也是个B+树
O(B+Tree高度) vs O(1)
对热点buffer pool建立AHI,非持久化
只支持等值查询,比如:
idx_a_b(a,b)
WHERE a=xxx
WHERE a=xxx and b=xxx
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Hash table size 42499381, node heap has 68063 buffer(s)
1640.60 hash searches/s, 3709.46 non-hash searches/s
1640/(1640+3709) = 30.6%
innodb的crash recovery
通常的恢复做法:先redo、后undo

redo,redo结束后,server开始对外提供服务,后面过程放在后台线程继续工作
当实例从崩溃中恢复时,需要将活跃事务从undo中提取出来,对于active状态的事务直接回滚,对于prepare状态的事务,如果该事务对应的binlog已经记录,则提交,否则回滚事务
change buffer merge
purge
xa recover

加快crash recovery速度
升级到5.5以后版本
提供IO设备性能
适当调低innodb_max_dirty_pages_pct,50以下
设置innodb_flush_log_at_trx_commit=1,让每个事务尽快提交,避免有其他事务等待,产生大量undo,增加purge工作量
innodb重要参数


innodb_stats_on_metadata=0
执行show table status ,show index from xx 时是否更新统计信息
innodb监控
innodb_lock_table
innodb_lock_monitor
innodb_table_monitor
innodb_tablespace_monitor
sys schema
P_S、I_S、sys
3个系统视图

f
标签:
原文地址:http://www.cnblogs.com/zengkefu/p/5698975.html