标签:
grep命令
格式:grep [-acinv] [--color=auto] ‘查找字符串‘ filename
-a 将binary文件以text文件的
-c 计算找到 ‘查找字符串’ 的次数
-i 忽略大小写的不同,所以大小写视为相同
-n 顺便输出行号
-v 反向选择,即显示出没有 ‘查找字符串’ 内容的那一行
--color=auto 关键部分加上颜色显示

基础正则
^:行首
$:行尾
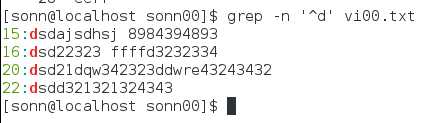
查找以0为行首:
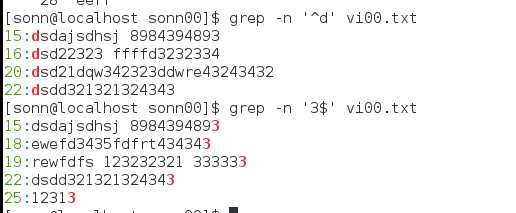
查找以3为行尾:
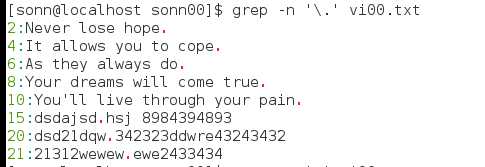
. 代表一定有一个任意字符的字符

\转义字符,将特殊字符的特殊含义去掉
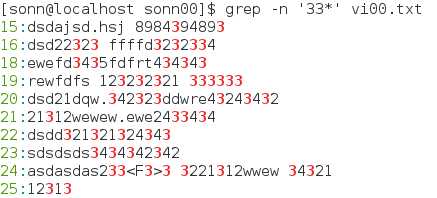
*重复0个到无穷多个的前一个字符(一定要切记是0到无穷多个,如果你想grep带有‘3’的行,用‘3*’是无效的,应该为‘33*’,其实grep ‘3’ = grep ‘33*’)
[list], [abc]则或a或b或c,[0-9]则0-9范围中任意一个,同理[a-z]或[A-Z]
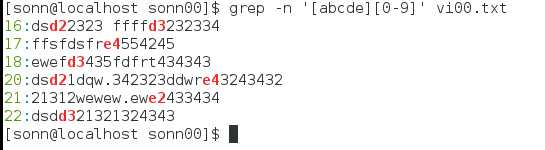
[^list] 取不在该范围内的字符,下面例子,grep一整行皆为非小写字母字符的行。*为0到无限多个的意思,如果有了扩展正则表达式,用+可以表达1到1个以上。
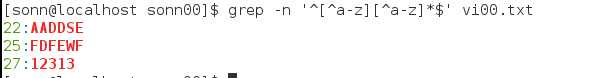
\{n,m\} \{n,\} \{\,m}
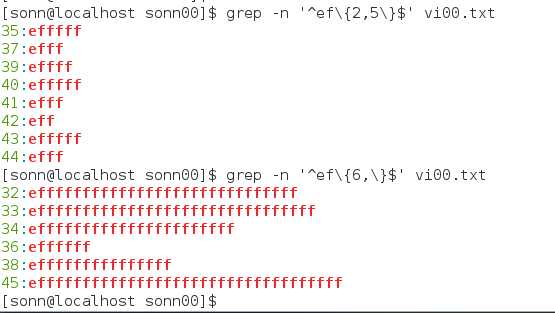
扩展正则表达式
一定要注意:扩展正则表达式要写为egrep
+ 与之前*相对应是一个或以上前一个字符
egrep ‘^[^a-z]+$‘ = grep ‘^[^a-z][^a-z]*$‘

? 0个或一个前一个字符
| 或
()一组字符
()+ 多个重复组

标识字符集,例如可以用[:digit:]代替[0-9] 实例:egrep -n ‘^(12|2[[:digit:]][[:digit:]]|(29|30|31|32)[[:digit:]][[:digit:]])$‘ file*
(查找n,n=12或200<=n<=299或2900<=n<=3299)
[:alnum:] 字母和数字
[:alpha:] \a 字母
[:lower:] \l 小写字母
[:upper:] \u 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] \s 所有空格符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] \d 十进制数字
[:xdigit:] \x 十六进制数字
[:graph:] 可打印的非空白字符
[:print:] \p 可打印字符
[:punct:] 标点符号
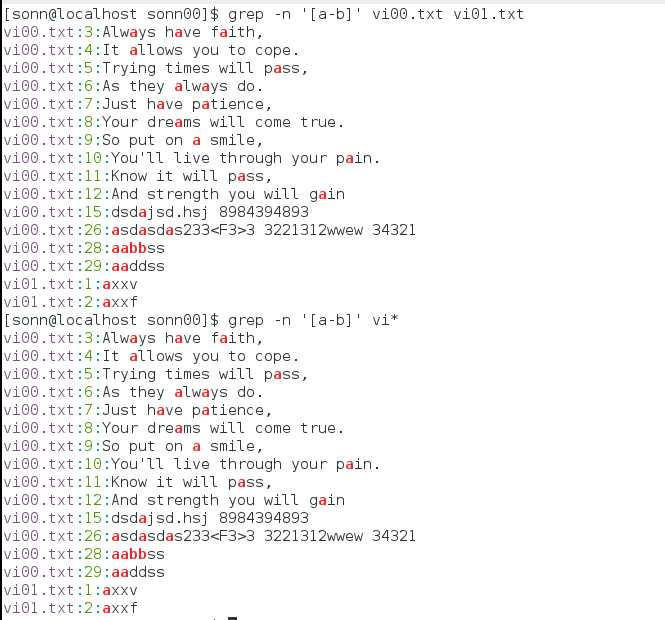
最后,grep可以抓取多个文件中的字符,grep -n ‘正则表达式’ file1 file2
标签:
原文地址:http://www.cnblogs.com/rixiang/p/5700706.html