标签:
是这样的,有位学姐呢初学python ,问我怎么处理QQ聊天记录,当时就说了用正则,也没去写,现在闲着(被ajax虐哭。。。先放一放)就来简单写一下。
目标,统计近一个月来,QQ群在一天24个时间段的发言量。
Step1:获取QQ聊天记录
这个简单无脑了。。。直接导出消息记录即可。详情参考这里。导出时,记得要保存为txt格式,并和python文件放到同一文件夹下(只是为了方便)。
Step2:开始撸码
环境:python3+pycharm+xlsxwriter
上代码:
import re
import xlsxwriter
# 获取24个时间段----->time_list
# 用于之后时间的分段
time_list = []
for i in range(0,24):
# 这里的判断用于将类似的‘8’ 转化为 ‘08’ 便于和导出数据匹配
if i < 10:
i = ‘0‘+str(i)
else:
i = str(i)
time_list.append(i)
# 创建EXCEL表格并设置参数
workbook = xlsxwriter.Workbook(‘这里是表格名称.xlsx‘)
worksheet = workbook.add_worksheet()
worksheet.set_column(‘A:A‘, 5)
worksheet.set_column(‘B:B‘, 10)
# 定义一个函数,对每一个时间段进行计数
# times是正则匹配到的 “小时” 数据,在一个列表里面
def everytime(i):
num = 0
for time in times:
if time == i:
num += 1
print(i, ‘--->‘, num)
# 计数完毕,写入数据,write参数为:行,列,数据
worksheet.write(int(i), 0, str(i)+"点")
worksheet.write(int(i), 1, num)
# 打开文件,开始匹配“小时”数据,并计数保存
# 这里记得要转换编码为utf-8
with open("这里是txt文件名", encoding=‘utf-8‘) as f:
data = f.read()
# 例如20:50:52,要匹配其中的20
pa = re.compile(r"(\d\d):\d\d:\d\d")
times = re.findall(pa, data)
for i in time_list:
everytime(i)
# 记得关闭工作薄
workbook.close()
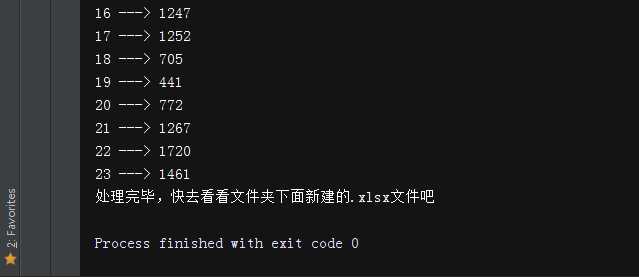
print("处理完毕,快去看看文件夹下面新建的.xlsx文件吧")
代码比较丑。。。欢迎指正。
输出如下:
之后那,就要可视化了,嗯,Python的matplotlib对我来说太高大上,那就用EXCEL来吧。。。
Step3:EXCEL可视化
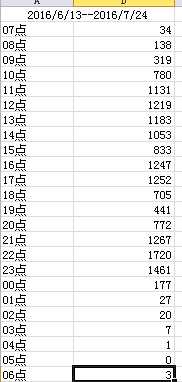
可视化,嗯,其实就是简单做个折线图,23333.为了折线图方便观察,可以适当调整一下时间的前后顺序。
我按照这个顺序来的:(将凌晨数据量小的放在两边)
最后:
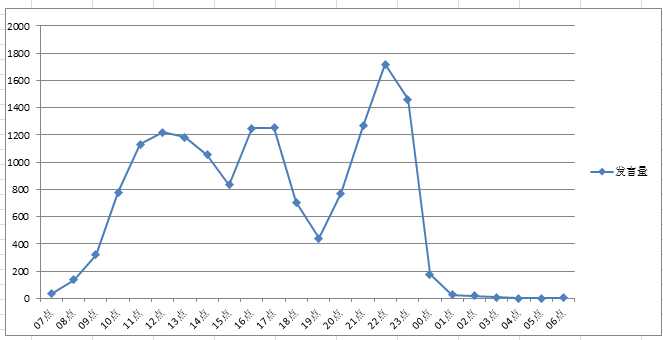
这是加的编程的群,我来猜测一下这个图吧,不负责的猜测那种。。。。
7点爬起来去上班,越到临近中午下班越激动,中午饭后来个午睡,开始一下午昏昏欲睡的撸码工作,终于熬到下班,吃完晚饭开始愉快的撸码。。。没错还是撸码。。
勤奋的程序员们,学习到23点,渐渐有点虚,嗯,就去睡觉啦,毕竟明天还要上班,还要撸码。。。(以上内容,开个玩笑而已2333333)
标签:
原文地址:http://www.cnblogs.com/buzhizhitong/p/5701299.html