标签:
l WEB,在英语中web即表示网页的意思,它用于表示Internet主机上供外界访问的资源。
l Internet上供外界访问的Web资源分为:
• 静态web资源(如html 页面):指web页面中供人们浏览的数据始终是不变。
• 动态web资源:指web页面中供人们浏览的数据是由程序产生的,不同时间点访问web页面看到的内容各不相同。
l 静态web资源开发技术
• Html
l 常用动态web资源开发技术:
• JSP/Servlet、ASP、PHP等 ruby python
• 在Java中,动态web资源开发技术统称为Javaweb,我们课程的重点也是教大家如何使用Java技术开发动态的web资源,即动态web页面。
但是我们做java开发,不是做网页。
网络上的资源分为两种
早期:静态页面 html实现。 观看
现在:动态页面 php asp jsp 交互.
lamp =linux +apache+ mysql+php----->个人网关或小型企业首选
asp现在没人用,但是网络上遗留下来的比较多。miscrosoft的技术
.net技术。
jsp--->java去做网页所使用的技术。jsp本质上就是servlet
使用jsp开发成本高。
BS====>浏览器+服务器 只要有浏览器就可以
CS----->客户端+服务器. 必须的在客户端安装程序.
现在基本上开发的都是BS程序
BS怎样通信:
必须有请求有响应。
有一次请求就应该具有一次响应,它们是成对出现的。
大型服务器:websphere(IBM),weblogic(Oracle) J2EE容器 -
支持EJB (EnterPrice Java Bean (企业级的javabean)) – Spring
weblogic BEA公司产品,被Oracle收购,全面支持JavaEE规范,收费软件,企业中非常主流的服务器 -------- 网络上文档非常全面
WebSphere 文档非常少,IBM公司产品,价格昂贵,全面支持JavaEE 规范
Tomcat- apache,开源的。Servlet容器。
tomcat 开源小型web服务器 ,完全免费,主要用于中小型web项目,只支持Servlet和JSP 等少量javaee规范 ,Apache公司jakarta 一个子项目
Jboss – hibernate公司开发。不是开源免费。J2EE容器
注意路径中不要包含空格与中文。
Ø 安装步骤
1、tomcat.apache.org 下载tomcat安装程序
Tomcat7安装程序 ---- zip免安装版
2、解压tomcat
3、配置环境变量 JAVA_HOME 指向JDK安装目录 D:\Program Files\Java\jdk1.6.0_21
*CATALINA_HOME指定tomcat安装目录
4、双击tomcat/bin/startup.bat
5、在浏览器中 输入 localhost:8080 访问tomcat主页了
Ø 注意问题:
启动黑色不能关闭
1、CATALINA_HOME 指定tomcat安装位置 --- 可以不配置
2、JAVA_HOME 指定JDK安装目录,不要配置bin目录,不要在结尾加;
3、端口被占用
启动cmd
netstat -ano 查看占用端口进程pid
任务管理器 查看---选择列 显示pid -- 根据pid结束进程
* 有些进程无法关系(系统服务 --- 必须结束服务) win7 自带 World wide web publish IIS服务 默认占用端口80
* xp 安装apache服务器后,会占用80 端口 ,关闭apache服务
通过运行 services.msc 打开服务窗口 关闭相应服务
-----bin 它里面装入的是可执行的命令 如 startup.bat
-----conf 它里面是一个相关的配置文件,我们可以在里面进行例如端口,用户信息的配置
<Connector port="80" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
-----lib tomcat类库。
-----logs tomcat 日志文件
-----temp 临时文件
-----webapps 它里面放的是的 web site(web项目)
-----work 存放的是页面(例如 jsp)转换成的.class文件。
在根目录下 创建静态web资源和动态web资源
Web site
---- *.html *.css *.js 图片 音频 视频 、*.jsp
---- WEB-INF目录 存放java程序和配置文件
--- classes 存放.class文件
--- lib 存放.jar 文件
--- web.xml 网站核心配置文件
*** 如果静态网站可以不存在 WEB-INF目录的 ,WEB-INF目录,客户端无法直接访问(在服务器内存通过程序访问)
虚似目录的映射方式有三种
1.在开发中应用的比较多 直接在webapps下创建一个自己的web site就可以.
步骤 1.在webapps下创建一个myweb目录
2.在myweb下创建WEB-INF目录,在这个目录下创建web.xml
3.将web.xml文件中的xml声明与根元素声明在其它的web site中copy过来。
4.在myweb下创建一个index.html文件
5.启动tomcat
6.在浏览器中输入 http://localhost/myweb/index.html
以下两种方式,可以将web site不放置在tomcat/webapps下,可以任意放置
2.在server.xml文件中进行配置
<Context path="/abc" docBase="C:\myweb1"/>
</Host>
在Host结束前配置
path:它是一个虚拟路径,是我们在浏览器中输入的路径
docBase:它是我们web sit的真实路径
http://localhost/abc/index.html
3.不在server.xml文件中配置
而是直接创建一个abc.xml文件
在这个xml文件中写
<Context path="" docBase="C:\myweb1"/>
将这个文件放入conf\Catalina\localhost
http://localhost/abc/index.html
war文件是web项目的压缩文件。
要想生成,先将要压缩的内容压缩成zip文件,
然后将后缀改成war就可以,
war文件可以直接在服务器上访问。
关于tomcat-manager
可以在conf/tomcat-users.xml中进行用户信息添加
<role rolename="manager"/>
<user username="xxx" password="xx" roles="manager"/>
这样就添加了一个用户
注意,用户权限要是比较大的话,会出现安全问题.
做自己的一个http://www.baidu.com
1.访问一个网站的过程
http://www.baidu.com
http 协议
www 服务器
.baidu.com 域名 IP
步骤
1.上网将baidu首页下载下来
2.做一个自己的web site 首页就是下载下来的页面。
别忘记创建WEB-INF在它下面的web.xml文件中
<welcome-file-list>
<welcome-file>index.html</welcome-file>
</welcome-file-list>
这句话的作用是默认访问页面是index.html
3.在tomcat中的conf文件夹下的server.xml中修改
<Host name="www.baidu.com" appBase="c:\baidu"
unpackWARs="true" autoDeploy="true"
xmlValidation="false" xmlNamespaceAware="false">
<Context path="" docBase="c:\baidu"/>
</Host>
4.在windows/system32/drivers/etc/hosts中添加
127.0.0.1 www.baidu.com
目的是当访问www.baidu.com时其实访问的是本机。
5.打开浏览器在地址栏中输入www.baidu.com
这时其时访问的是我们自己
web site中的页面。
我们在myeclipse中创建web project有一个WebRoot目录。
但是我们发布到tomcat中没有这个,它其时就是我们工程的名称.
步骤
1.创建web工程
2.在eclipse中配置tomcat服务器
window/属性/myeclipse/service中配置自己的tomcat目录.
注意到tomcat根目录就可以了。不要到bin中。
如果不好使用,看一些jdk是否配置.

1. 将webproject部署到tomcat中
HTTP是hypertext transfer protocol(超文本传输协议)的简写,它是TCP/IP协议的一个应用层协议,用于定义WEB浏览器与WEB服务器之间交换数据的过程。
HTTP协议是学习JavaWEB开发的基石,不深入了解HTTP协议,就不能说掌握了WEB开发,更无法管理和维护一些复杂的WEB站点。
telnet怎样使用
1.telnet localhost 8080
2 ctrl+]
3.按回车
注意 在里面写错的内容不能修改
GET /index.html HTTP/1.1
host:localhost
4.要敲两次回车
HTTP/1.0版本只能保持一次会话
HTTP/1.1版本可能保持多次会话.
是根据telnet得到的响应信息
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
ETag: W/"7347-1184876416000"
Last-Modified: Thu, 19 Jul 2007 20:20:16 GMT
Content-Type: text/html
Content-Length: 7347
Date: Thu, 25 Apr 2013 08:06:53 GMT
Connection: close
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Apache Tomcat</title>
<style type="text/css">
..........
是根据httpwatch得到的请求信息与响应信息
请求
GET / HTTP/1.1
Accept: application/x-shockwave-flash, image/gif, image/jpeg, image/pjpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*
Accept-Language: zh-cn
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)
Accept-Encoding: gzip, deflate
Host: localhost
Connection: Keep-Alive
响应
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
ETag: W/"7347-1184876416000"
Last-Modified: Thu, 19 Jul 2007 20:20:16 GMT
Content-Type: text/html
Content-Length: 7347
Date: Thu, 25 Apr 2013 08:12:57 GMT
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang
GET /books/java.html HTTP/1.1 ---------->请求行
Get是请求方式 /books/java.html 请求资源 HTTp/1.1协议版本
POST与GET的区别
1.什么样是GET 请求 1)直接在地址栏输入 2.超连接 <a></a> 3.form表单中method=get
什么样是POSt请求 form表单中method=POST
2.以get方式提交请求时,在请求行中会将提交信息直接带过去
格式 /day03_1/login?username=tom&password=123
以post方式提交时,信息会在正文中。
POST /day03_1/login HTTP/1.1
Accept: application/x-shockwave-flash, image/gif, image/jpeg, image/pjpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*
Referer: http://localhost/day03_1/login.html
Accept-Language: zh-cn
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Host: localhost
Content-Length: 25
Connection: Keep-Alive
Cache-Control: no-cache
username=tom&password=123
3. get方式最多能提交1kb
post可以提交大数据,做上传时必须是post
Accept: */* 允许访问mime类型,类型都在tomcat 的conf/web.xml文件中定义了。
这个需要知道,因为做下载时要知道mime类型
Accept-Language: en-us 客户端的语言
Connection: Keep-Alive 持续连接
Host: localhost 客户端访问资源
Referer: http://localhost/links.asp (重点) 防盗链。
User-Agent: Mozilla/4.0 得到浏览器版本 避免兼容问题
Accept-Charset: ISO-8859-1 客户端字符编码集
Accept-Encoding: gzip, deflate gzip是压缩编码.
If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT 与Last-MOdified一起可以控制缓存。
Date: Tue, 11 Jul 2000 18:23:51 GMT
示例1
防盗链程序
referer.htm页面
<body>
<a href="referer">referer</a>
</body>
RefererServlet类似
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String msg = request.getHeader("Referer");
if (msg != null && "http://localhost/day03_1/referer.html".equals(msg)) {
// 如果你是正常访问,我们给其一个友好信息
response.getWriter().write("hello");
} else {
// 如果是盗链过来的,对不。骂它一句
response.getWriter().write("fuck...");
}
}
怎样破解
URL url = new URL("http://localhost/day03_1/referer"); //得到一个url
URLConnection con = url.openConnection(); //访问这个url,并获得连接对象
con.addRequestProperty("Referer",
"http://localhost/day03_1/referer.html");
InputStream is = con.getInputStream(); // 读取服务器返回的信息.
byte[] b = new byte[1024];
int len = is.read(b);
System.out.println(new String(b, 0, len));
HTTP/1.1 200 OK 响应状态行
HTTP/1.1 200 OK
1xx 什么都没做直接返回
2xx 成功返回
3xx 做了一些事情,没有全部完成。
4xx 客户端错误
5xx 服务器错误
200 正确
302 重定向
304 页面没有改变
404 未找到页面
500 服务器出错.
Location: http://www.it315.org/index.jsp 响应路径(重点)+302
Server:apache tomcat
Content-Encoding: gzip 响应编码 gzip 压缩
Content-Length: 80 响应长度
Content-Language: zh-cn 响应语言
Content-Type: text/html; charset=GB2312 响应字符编码
Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT 要与请求中的 If-Modified-Since处理缓存
Refresh: 1;url=http://www.it315.org 自动跳转
Content-Disposition: attachment; filename=aaa.zip (重要) 文件的下载
//下面三个是禁用浏览缓存
Expires: -1
Cache-Control: no-cache
Pragma: no-cache
Connection: close/Keep-Alive
Date: Tue, 11 Jul 2000 18:23:51 GMT
重点
今天可以讲
Location: http://www.it315.org/index.jsp 响应路径(重点)+302
Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT 要与请求中的 If-Modified-Since处理缓存
Refresh: 1;url=http://www.it315.org 自动跳转
我们在得到响应信息,经常得到的是压缩后的。
这种操作
1.服务器配置方式
tomcat配置实现压缩
80端口没有配置 00:00:00.000 0.228 7553 GET 200 text/html http://localhost/
8080端口配置 00:00:00.000 0.027 2715 GET 200 text/html http://localhost:8080/
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" compressableMimeType="text/html,text/xml,text/plain" compression="on"/>
2.通过我们编程实现.(后面会讲)
后面会讲
Content-Disposition: attachment; filename=aaa.zip (重要) 文件的下载
//下面三个是禁用浏览缓存
Expires: -1
Cache-Control: no-cache
Pragma: no-cache

4.启动服务器
5.在浏览器中访问web资源.
l Servlet是一个功能,如果你希望你的项目功能多一些,那就要多写一此Servlet;
l Servlet是JavaWeb三大组件之一,也是最重要的组件!
Ø 三大组件:Servlet、Filter、Listener
l Servlet是一个我们自定义的Java类,它必须要实现javax.servlet.Servlet接口。
l Servlet是动态资源!
l Servlet必须在web.xml中进行配置后,才能被访问。(把Servlet与一个或多个路径绑定在一起)
l 实现Servlet有三种方式:
Ø 实现Servlet接口;
Ø 继承GenericServlet类;
Ø 继承HttpServlet类(最佳选择)。

看代码
看代码
l Servlet接口中一共是5个方法,其中有三个是生命周期方法。
Ø void init(ServletConfig):这个方法会在Servlet被创建后,马上被调用。只会被调用一次!我们可以把一些初始化工作放到这个方法中,如果没有什么初始化工作要做,那么这个方法就空着就可以了。
² Servlet有两个时间点会被创建:一是在第一次被请求时,会被创建;二是Tomcat启动时被创建,默认是第一种,如果希望在tomcat启动时创建,这需要在web.xml中配置。
Ø void destroy():这个方法会在Servlet被销毁之前被调用。如果你有一些需要释放的资源,可以在这个方法中完成,如果没有那么就让这个方法空着。这个方法也只会被调用一次!
² Servlet轻易不会被销毁,通常会在Tomcat关闭时会被销毁。
Ø void service(ServletRequest,ServletResponse):它会在每次被请求时调用!这个方法会被调用0~N次。
Ø String getServletInfo():它不是生命周期方法,也就是说它不会被tomcat调用。它可以由我们自己来调用,但我们一般也不调用它!你可以返回一个对当前Servlet的说明性字符串。
Ø ServletConfig getServletConfig():这个方法返回的是ServletConfig,这个类型与init()方法的参数类型相同。它对应的是web.xml中的配置信息,即<servlet>
l ServletRequest:封装了请求信息;
l ServletResposne:用于向客户端响应;
l ServletContext:它可以在多个Servlet中共享数据。
l ServletConfig:它与<servlet>对应!
Ø 在<servlet>中可以配置<init-param>,即初始化参数,可以使用ServletConfig的getInitParameter(String),方法的参数是初始化参数名,方法的返回值是初始化参数值。
Ø getInitParameterNames(),该方法返回一个Enumeration对象,即返回所有初始化参数的名称。
Ø String getServletName(),它返回的是<servlet-name>元素的值
Ø ServletContext getServletContext(),它可以获取Servlet上下文对象。
l 它代理了ServletConfig的所有功能。所有使用ServletConfig才能调用的方法,都可以使用GenericServlet的同名方法来完成!
l 不能覆盖父类的init(ServltConfig)方法,因为在父类中该方法内完成了this.config=config,其他的所有ServletConfig的代理方法都使用this.config来完成的。一旦覆盖,那么this.config就是null。
l 如果我们需要做初始化工作,那么可以去覆盖GenericServlet提供的init()方法。

l 它提供了与http协议相关的一些功能。
l 只需要去覆盖doGet()或doPost()即可。这两个方法,如果没有覆盖,默认是响应405!
l Servlet是的单例的。所以一个Servlet对象可能同时处理多个请求;
l Servlet不是线程安全的。
Ø 尽可能不创建成员变量,因为成员变量多个线程会共享!
Ø 如果非要创建,那么创建功能性的,只读!
* Servlet可以在第一次请求时被创建,还可以在容器启动时被创建。默认是第一次请求时!
* 在<servlet>添加一个<load-on-startup>大于等于0的整数</load-on-startup>
* 如果有多个Servlet在容器启动时创建,那么<load-on-startup>的值就有用了,创建的顺序使用它的值来排序!
l <url-pattern>中可以使用“*”表示所有字符,但它不匹配“/”。它的使用要求:
Ø 它要么在头,要么在尾。不能在中间;
Ø 如果不使用通配符,那么必须使用“/”开头。
l 如果一个访问路径,匹配了多个<url-pattern>,那么谁更加明确就匹配谁。
l 每个项目都有一个web.xml,但tomcat下也有一个web.xml,在${CATALINA_HOME}\conf\web.xml
l conf\web.xml是所有项目的web.xml父文件,父文件中的内容等于同写在子文件中。
Servlet三大域对象:
l ServletContext:范围最大,应用范围!
l HttpSession :会话范围!
l HttpServletRequest:请求范围!
域对象之一
域对象都有存取功能:
setAttribute(“attrName”, attrValue );//put
Object attrValue = getAttribute(“attrName”);//get
removeAttribute(“attrName”);//remove
l 存取域属性,ServletContext是一个域对象;
l 可以用来获取应用初始化参数;
l 获取资源
l ServletContext在容器启动时就被创建了;
l ServletContext在容器关闭时才会死!
l 一个项目只有一个ServletContext对象。
l 通过ServletConfig的getServletContext()方法来获取!
Ø ServletConfig是init()方法的参数,那只能在init()方法中获取了;
Ø GenericServlet代理了ServletConfig的所有方法,而且还提供了getServletConfig(),所以在GenericServlet的子类中可以使用如下方式来获取ServletContext对象:
² this.getServletContext()
² this.getServletConfig().getServletContext()
Ø HttpSession也有这个方法,session.getServletContext()。
l void setAttribute(String name, Object value):存储属性;
l Object getAttribute(String name):获取属性;
l void removeAttribute(String name):移除属性;
l Enumeration getAttributeNames():获取所有属性名称;
一个 项目不只是可以配置servlet的初始化参数,还可以配置应用初始化参数
下面就是在web.xml中配置应用的初始化参数,这些参数需要使用ServletContext来获取
|
<context-param> <param-name>p1</param-name> <param-value>v1</param-value> </context-param> <context-param> <param-name>p2</param-name> <param-value>v2</param-value> </context-param> |
l String getInitParameter(String name):通过参数名获取参数值;
l Enumeration getInitParameterNames():获取所有参数的名称;
l 获取真实路径:getRealPath(String path):路径必须以“/”开头!它相对当前项目所在路径的。
l 获取指定路径下的所有资源路径:Set set = sc.getResourcePaths(“/xxx”)
l 获取资源流:InputStream in = sc.getResourceAsStream(“/xxx”)
User.class如何变成Class<User>的呢,由ClassLoader完成的!把硬盘上的User.class加载到内存,变成Class对象。
使用它们获取资源流!它们相对类路径(classpath)
l response的类型为HttpServletResponse,它是Servlet的service()方法的参数。
l 当客户端发出请求时,tomcat会创建request和rsponse来调用Servlet的service()方法,每次请求都会创建新的request和response。
l response是用来向客户端完成响应。
l response.getWriter() ,返回值为PrintWriter,用响应字符数据。
l response.getOutputStream(),返回值为ServletOutputStream,用来响应字节数据。
l 在一个请求范围内,这两个流不能同时使用!不然会输出非法状态异常。
l response的字符流默认使用ISO-8859-1编码,可以使用response.setCharaceterEncoding(“utf-8”)来设置编码;
l 浏览器在没有得到Content-Type头时,会使用GBK来解读字符串,当如果你设置了Content-Type,会使用你指定编码来解读字符串。response.setContentType(“html/texgt;charset=utf-8”);
l response字符流缓冲区大小为8KB;
l 可以调用response.getWriter().flush()方法完成刷新,这会把当前缓冲区中的数据发送给客户端。
l 当response一旦开始了发送,那么response的内部会有一个提交状态为true。可以调用response的isCommitted()方法来查看当前的提交状态。
l 有一个响应头:Refresh,它的作用是在指定的时间后,自动重定向到指定路径。例如:response.setHeader(“Refresh”, “5;URL=http://www.baidu.com”);,表示在5秒后自动跳转到百度。
l response.sendError(404, “没找到您访问的资源”)
l response.sendStatus(302);
l 重定向:两个请求。
Ø 第一个请求,服务器响应码:302
Ø 第一个请求的响应头有一个Location头,它说明了要重定向的URL;
Ø 第二个请求,浏览器重新向Location头指定的URL发出。
l 重定向:可以重定向到本项目之外的页面。例如可以重定向到百度!
l 重定向:可以重定向到本项目内的其他资源,可以使用相对路径,以“/项目名”开头
l 重定向:会使浏览器的地址栏发生变化!
注意事项:
l 当response为以提交状态,就不能再重定向了!
l 当使用了response的输出流响应后,再重定向。如果没有造成response提交,那么说明数据还在缓冲区中,tomcat会把缓冲区清空,然后重定向。
l 有主体(正文)
l 有Content-Type,表示主体的类型,默认值为application/x-www-form-urlencoded;
l 可以获取请求方式:String getMethod()
l 可以获取请求头:String getHeader(String name)
l 可以获取请求参数(包含主体或路径后面的参数):String getParameter(String name)
l 地址栏的参数是GBK的;
l 在页面中点击链接或提交表单,参数都由当前页面的编码来决定,而页面的编码由当初服务器响应的编码来决定。
l 服务器请求form.html,服务器响应utf-8的页面给浏览器,然后在form.html页面上点击链接和提交表单发送的参数都是utf-8。
l 如果服务器的所有页面都是utf-8的,那么只要不在浏览器的地址栏中给出中文,那么其他的参数都是utf-8的。
服务器:
l 服务器默认使用ISO-8859-1来解读请求数据。(tomcat7以前是这个编码)
l 可以使用request.setCharacterEncoding(“utf-8”)设置编码来解读请求参数。这个方法只对请求主体有效,而GET请求没有主体。说白了就是只对POST请求有效!
l 设置Tomcat 其中GET请求的默认编码:
|
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8"/> |
l 因为编码的设置不能依赖tomcat的配置,所以还是需要我们自己手动转码
Ø String name = request.getParamter(“username”);//使用默认的iso来解码
Ø byte[] bytes = name.getBytes(“iso-8859-1”);//使用iso回退到字节数组
Ø name = new String(bytes, “utf-8”);//重新使用utf-8来解码
l *String getParameter(String name) :通过参数名称获取参数值!
l String[] getParameterValues(String name):通过参数名称获取多个参数值!一般复选框会出现一个名称多个值的情况。
l *Map<String,String[]> getParameterMap():获取所有参数,封装到Map中,基参数名为key,参数值为value。
l Enumeration getParameterNames():获取所有参数的名称
域功能:
l void setAttribute(String name,Object value)
l Object getAttribute(String name)
l void removeAttribute(String name)
request 的存储范围:整个请求链!如果一个请求经过了多个Servlet,那么这些Servlet可以共享request域!
l String getHeader(String name):通过头名称,获取头信息;
l Enumeration getHeaderNames() :获取所有头的名称;
l Enumeration getHeaders(String name):通过头名称,获取多个头信息;
l int getIntHeader(String name):通过头名称,获取头信息,本方法再把String的头信息转换成int类型。
如何请求转发
l 一个请求内经过多个资源(Servlet,还有jsp,而且经常是jsp)
l 请求转发需要使用RequestDispatcher的forward(HttpServletRequest,HttpServletResponse)
l RequestDispatcher rd = request.getRequestDispatcher(“/BServlet”);//参数是要转发的目标
l rd.forward(request,response);//转发到BServlet
其实你可以理解成在一个Servlet中,调用另一个Servlet的service()方法。
请求转发的注意事项
l 在第一个Servlet中可以使用request域保存数据,在第二个Servlet中可以使用request域获取数据。因为这两个Servlet共享同一个request对象。
l
l 在转发语句之后,其他语句是否会执行?答案是“可以”!
l 不能在一个Servlet中即重定向,又转发。
请求转发与重定向比较
l 请求转发后,地址栏中的地址不变!重定向变
l 请求转发是一个请求,重定向是两个请求;
l 请求转发可以共享request域,而重定向因为是两个请求,所以不能共享request。
l 一个请求,只有一个请求方式!所以转发后还是原来的请求方式,如果一开始发出的是GET,那么整个请求都是GET!重定向不同,因为是多个请求,第一个无论是什么方式,第二个请求都是GET。
l 请转转发只能是本项目中的资源,而重定向可以其他项目。
如果要转发,就不要输出
l 如果输出到缓冲区的数据,没有提交,那么在转发时,缓冲区会被清空,如果已经提交,那么在转发时抛出异常。这一点与重定向相同!
l 留头不留体:在第一个Servlet中设置头没问题,会保留到下一个Servlet。如果在第一个Servlet中输出数据,即设置响应体,那么如果没有提交,就被清空,如果已提交,就出异常。
请求包含:
l RequestDispatcher rd = request.getRequestDispatcher(“/BServlet”);
l rd.include(request,response);
留头又留体!
客户端路径:
1. 超链接:href=”/项目名/…”
2. 表单:action=”/项目名/…”
3. response.sendRedirect(“/项目名/…”);
如果客户端路径,没有已“/项目名”开头,那么相对的是当前页面所在路径。
例如:http://localhost:8080/day10_3/a.html,当前页面所在路径是http://localhost:8080/day10_3/
以“/”开头的客户端路径相对“http://localhost:8080”,<a href=”/hello/AServlet”>
服务器端路径:
转发:必须使用“/”开头,它相对当前项目,即http://localhost:8080/day10_3
包含:同上;
<url-pattern>:同上
ServletContext.getRealPath(“/a.jpg”):它是真对真实路径,相对当前WebRoot
ServletContext.getResourceAsStream():同上
Class.getResourceAsStream():如果使用“/”开头,相对classes,如果不使用“/”,相对当前.class文件所在目录。
ClassLoader. getResourceAsStream():无论使用不使用“/”开头,都相对classes
作用:为了在客户端与服务器之间传递中文!
把中文转换成URL编码:
Ø 首先你需要选择一种字符编码,然后把中文转换成byte[]。
Ø 把每个字节转换成16进制,前面添加上一个“%”。它不能显负号,把得到的byte先加上128,这样-128就是0了。正的127就是255了,它的范围是%00~%FF
我们需要先了解一下什么是会话!可以把会话理解为客户端与服务器之间的一次会晤,在一次会晤中可能会包含多次请求和响应。例如你给10086打个电话,你就是客户端,而10086服务人员就是服务器了。从双方接通电话那一刻起,会话就开始了,到某一方挂断电话表示会话结束。在通话过程中,你会向10086发出多个请求,那么这多个请求都在一个会话中。
在JavaWeb中,客户向某一服务器发出第一个请求开始,会话就开始了,直到客户关闭了浏览器会话结束。
在一个会话的多个请求中共享数据,这就是会话跟踪技术。例如在一个会话中的请求如下:
l 请求银行主页;
l 请求登录(请求参数是用户名和密码);
l 请求转账(请求参数与转账相关的数据);
l 请求信誉卡还款(请求参数与还款相关的数据)。
在这上会话中当前用户信息必须在这个会话中共享的,因为登录的是张三,那么在转账和还款时一定是相对张三的转账和还款!这就说明我们必须在一个会话过程中有共享数据的能力。
我们知道HTTP协议是无状态协议,也就是说每个请求都是独立的!无法记录前一次请求的状态。但HTTP协议中可以使用Cookie来完成会话跟踪!
在JavaWeb中,使用session来完成会话跟踪,session底层依赖Cookie技术。
Cookie翻译成中文是小甜点,小饼干的意思。在HTTP中它表示服务器送给客户端浏览器的小甜点。其实Cookie就是一个键和一个值构成的,随着服务器端的响应发送给客户端浏览器。然后客户端浏览器会把Cookie保存起来,当下一次再访问服务器时把Cookie再发送给服务器。

Cookie是由服务器创建,然后通过响应发送给客户端的一个键值对。客户端会保存Cookie,并会标注出Cookie的来源(哪个服务器的Cookie)。当客户端向服务器发出请求时会把所有这个服务器Cookie包含在请求中发送给服务器,这样服务器就可以识别客户端了!
l Cookie大小上限为4KB;
l 一个服务器最多在客户端浏览器上保存20个Cookie;
l 一个浏览器最多保存300个Cookie;
上面的数据只是HTTP的Cookie规范,但在浏览器大战的今天,一些浏览器为了打败对手,为了展现自己的能力起见,可能对Cookie规范“扩展”了一些,例如每个Cookie的大小为8KB,最多可保存500个Cookie等!但也不会出现把你硬盘占满的可能!
注意,不同浏览器之间是不共享Cookie的。也就是说在你使用IE访问服务器时,服务器会把Cookie发给IE,然后由IE保存起来,当你在使用FireFox访问服务器时,不可能把IE保存的Cookie发送给服务器。
Cookie是通过HTTP请求和响应头在客户端和服务器端传递的:
l Cookie:请求头,客户端发送给服务器端;
Ø 格式:Cookie: a=A; b=B; c=C。即多个Cookie用分号离开;
l Set-Cookie:响应头,服务器端发送给客户端;
Ø 一个Cookie对象一个Set-Cookie:
Set-Cookie: a=A
Set-Cookie: b=B
Set-Cookie: c=C
如果服务器端发送重复的Cookie那么会覆盖原有的Cookie,例如客户端的第一个请求服务器端发送的Cookie是:Set-Cookie: a=A;第二请求服务器端发送的是:Set-Cookie: a=AA,那么客户端只留下一个Cookie,即:a=AA。
我们这个案例是,客户端访问AServlet,AServlet在响应中添加Cookie,浏览器会自动保存Cookie。然后客户端访问BServlet,这时浏览器会自动在请求中带上Cookie,BServlet获取请求中的Cookie打印出来。

AServlet.java
|
package cn.itcast.servlet; import java.io.IOException; import java.util.UUID; import javax.servlet.ServletException; import javax.servlet.http.Cookie; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; /** * 给客户端发送Cookie * @author Administrator * */ public class AServlet extends HttpServlet { public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { response.setContentType("text/html;charset=utf-8"); String id = UUID.randomUUID().toString();//生成一个随机字符串 Cookie cookie = new Cookie("id", id);//创建Cookie对象,指定名字和值 response.addCookie(cookie);//在响应中添加Cookie对象 response.getWriter().print("已经给你发送了ID"); } } |
BServlet.java
|
package cn.itcast.servlet; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.http.Cookie; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; /** * 获取客户端请求中的Cookie * @author Administrator * */ public class BServlet extends HttpServlet { public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { response.setContentType("text/html;charset=utf-8"); Cookie[] cs = request.getCookies();//获取请求中的Cookie if(cs != null) {//如果请求中存在Cookie for(Cookie c : cs) {//遍历所有Cookie if(c.getName().equals("id")) {//获取Cookie名字,如果Cookie名字是id response.getWriter().print("您的ID是:" + c.getValue());//打印Cookie值 } } } } } |
Cookie不只是有name和value,Cookie还是生命。所谓生命就是Cookie在客户端的有效时间,可以通过setMaxAge(int)来设置Cookie的有效时间。
l cookie.setMaxAge(-1):cookie的maxAge属性的默认值就是-1,表示只在浏览器内存中存活。一旦关闭浏览器窗口,那么cookie就会消失。
l cookie.setMaxAge(60*60):表示cookie对象可存活1小时。当生命大于0时,浏览器会把Cookie保存到硬盘上,就算关闭浏览器,就算重启客户端电脑,cookie也会存活1小时;
l cookie.setMaxAge(0):cookie生命等于0是一个特殊的值,它表示cookie被作废!也就是说,如果原来浏览器已经保存了这个Cookie,那么可以通过Cookie的setMaxAge(0)来删除这个Cookie。无论是在浏览器内存中,还是在客户端硬盘上都会删除这个Cookie。
下面是浏览器查看Cookie的方式:
l IE查看Cookie文件的路径:C:\Documents and Settings\Administrator\Cookies;
l FireFox查看Cooke:

l Google查看Cookie:




l 创建Cookie,名为lasttime,值为当前时间,添加到response中;
l 在AServlet中获取请求中名为lasttime的Cookie;
l 如果不存在输出“您是第一次访问本站”,如果存在输出“您上一次访问本站的时间是xxx”;
AServlet.java
|
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { response.setContentType("text/html;charset=utf-8"); Cookie cookie = new Cookie("lasttime", new Date().toString()); cookie.setMaxAge(60 * 60); response.addCookie(cookie); Cookie[] cs = request.getCookies(); String s = "您是首次访问本站!"; if(cs != null) { for(Cookie c : cs) { if(c.getName().equals("lasttime")) { s = "您上次的访问时间是:" + c.getValue(); } } } response.getWriter().print(s); } |
3.1 什么是Cookie的路径
现在有WEB应用A,向客户端发送了10个Cookie,这就说明客户端无论访问应用A的哪个Servlet都会把这10个Cookie包含在请求中!但是也许只有AServlet需要读取请求中的Cookie,而其他Servlet根本就不会获取请求中的Cookie。这说明客户端浏览器有时发送这些Cookie是多余的!
可以通过设置Cookie的path来指定浏览器,在访问什么样的路径时,包含什么样的Cookie。
3.2 Cookie路径与请求路径的关系
下面我们来看看Cookie路径的作用:
下面是客户端浏览器保存的3个Cookie的路径:
a: /cookietest;
b: /cookietest/servlet;
c: /cookietest/jsp;
下面是浏览器请求的URL:
A: http://localhost:8080/cookietest/AServlet;
B: http://localhost:8080/cookietest/servlet/BServlet;
C: http://localhost:8080/cookietest/jsp/CServlet;
l 请求A时,会在请求中包含a;
l 请求B时,会在请求中包含a、b;
l 请求C时,会在请求中包含a、c;
也就是说,请求路径如果包含了Cookie路径,那么会在请求中包含这个Cookie,否则不会请求中不会包含这个Cookie。
l A请求的URL包含了“/cookietest”,所以会在请求中包含路径为“/cookietest”的Cookie;
l B请求的URL包含了“/cookietest”,以及“/cookietest/servlet”,所以请求中包含路径为“/cookietest”和“/cookietest/servlet”两个Cookie;
l B请求的URL包含了“/cookietest”,以及“/cookietest/jsp”,所以请求中包含路径为“/cookietest”和“/cookietest/jsp”两个Cookie;
3.3 设置Cookie的路径
设置Cookie的路径需要使用setPath()方法,例如:
cookie.setPath(“/cookietest/servlet”);
如果没有设置Cookie的路径,那么Cookie路径的默认值当前访问资源所在路径,例如:
l 访问http://localhost:8080/cookietest/AServlet时添加的Cookie默认路径为/cookietest;
l 访问http://localhost:8080/cookietest/servlet/BServlet时添加的Cookie默认路径为/cookietest/servlet;
l 访问http://localhost:8080/cookietest/jsp/BServlet时添加的Cookie默认路径为/cookietest/jsp;
Cookie的domain属性可以让网站中二级域共享Cookie,次要!
百度你是了解的对吧!
http://www.baidu.com
http://zhidao.baidu.com
http://news.baidu.com
http://tieba.baidu.com
现在我希望在这些主机之间共享Cookie(例如在www.baidu.com中响应的cookie,可以在news.baidu.com请求中包含)。很明显,现在不是路径的问题了,而是主机的问题,即域名的问题。处理这一问题其实很简单,只需要下面两步:
l 设置Cookie的path为“/”:c.setPath(“/”);
l 设置Cookie的domain为“.baidu.com”:c.setDomain(“.baidu.com”)。
当domain为“.baidu.com”时,无论前缀是什么,都会共享Cookie的。但是现在我们需要设置两个虚拟主机:www.baidu.com和news.baidu.com。
第一步:设置windows的DNS路径解析
找到C:\WINDOWS\system32\drivers\etc\hosts文件,添加如下内容
|
127.0.0.1 localhost 127.0.0.1 www.baidu.com 127.0.0.1 news.baidu.com |
第二步:设置Tomcat虚拟主机
找到server.xml文件,添加<Host>元素,内容如下:
|
<Host name="www.baidu.com" appBase="F:\webapps\www" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false"/> <Host name="news.baidu.com" appBase="F:\webapps\news" unpackWARs="true" autoDeploy="true" xmlValidation="false" xmlNamespaceAware="false"/> |
第三步:创建A项目,创建AServlet,设置Cookie。
|
Cookie c = new Cookie("id", "baidu"); c.setPath("/"); c.setDomain(".baidu.com"); c.setMaxAge(60*60); response.addCookie(c); response.getWriter().print("OK"); |
把A项目的WebRoot目录复制到F:\webapps\www目录下,并把WebRoot目录的名字修改为ROOT。
第四步:创建B项目,创建BServlet,获取Cookie,并打印出来。
|
Cookie[] cs = request.getCookies(); if(cs != null) { for(Cookie c : cs) { String s = c.getName() + ": " + c.getValue() + "<br/>"; response.getWriter().print(s); } } |
把B项目的WebRoot目录复制到F:\webapps\news目录下,并把WebRoot目录的名字修改为ROOT。
第五步:访问www.baidu.com\AServlet,然后再访问news.baidu.com\BServlet。
Cookie的name和value都不能使用中文,如果希望在Cookie中使用中文,那么需要先对中文进行URL编码,然后把编码后的字符串放到Cookie中。
向客户端响应中添加Cookie
|
String name = URLEncoder.encode("姓名", "UTF-8"); String value = URLEncoder.encode("张三", "UTF-8"); Cookie c = new Cookie(name, value); c.setMaxAge(3600); response.addCookie(c); |
从客户端请求中获取Cookie
|
response.setContentType("text/html;charset=utf-8"); Cookie[] cs = request.getCookies(); if(cs != null) { for(Cookie c : cs) { String name = URLDecoder.decode(c.getName(), "UTF-8"); String value = URLDecoder.decode(c.getValue(), "UTF-8"); String s = name + ": " + value + "<br/>"; response.getWriter().print(s); } } |
index.jsp
|
<body> <h1>商品列表</h1> <a href="/day06_3/GoodServlet?name=ThinkPad">ThinkPad</a><br/> <a href="/day06_3/GoodServlet?name=Lenovo">Lenovo</a><br/> <a href="/day06_3/GoodServlet?name=Apple">Apple</a><br/> <a href="/day06_3/GoodServlet?name=HP">HP</a><br/> <a href="/day06_3/GoodServlet?name=SONY">SONY</a><br/> <a href="/day06_3/GoodServlet?name=ACER">ACER</a><br/> <a href="/day06_3/GoodServlet?name=DELL">DELL</a><br/> <hr/> 您浏览过的商品: <% Cookie[] cs = request.getCookies(); if(cs != null) { for(Cookie c : cs) { if(c.getName().equals("goods")) { out.print(c.getValue()); } } } %> </body> |
GoodServlet
|
public class GoodServlet extends HttpServlet { public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String goodName = request.getParameter("name"); String goods = CookieUtils.getCookValue(request, "goods"); if(goods != null) { String[] arr = goods.split(", "); Set<String> goodSet = new LinkedHashSet(Arrays.asList(arr)); goodSet.add(goodName); goods = goodSet.toString(); goods = goods.substring(1, goods.length() - 1); } else { goods = goodName; } Cookie cookie = new Cookie("goods", goods); cookie.setMaxAge(1 * 60 * 60 * 24); response.addCookie(cookie); response.sendRedirect("/day06_3/index.jsp"); } } |
CookieUtils
|
public class CookieUtils { public static String getCookValue(HttpServletRequest request, String name) { Cookie[] cs = request.getCookies(); if(cs == null) { return null; } for(Cookie c : cs) { if(c.getName().equals(name)) { return c.getValue(); } } return null; } } |
javax.servlet.http.HttpSession接口表示一个会话,我们可以把一个会话内需要共享的数据保存到HttSession对象中!
l HttpSession request.getSesssion():如果当前会话已经有了session对象那么直接返回,如果当前会话还不存在会话,那么创建session并返回;
l HttpSession request.getSession(boolean):当参数为true时,与requeset.getSession()相同。如果参数为false,那么如果当前会话中存在session则返回,不存在返回null;
我们已经学习过HttpServletRequest、ServletContext,它们都是域对象,现在我们又学习了一个HttpSession,它也是域对象。它们三个是Servlet中可以使用的域对象,而JSP中可以多使用一个域对象,明天我们再讲解JSP的第四个域对象。
l HttpServletRequest:一个请求创建一个request对象,所以在同一个请求中可以共享request,例如一个请求从AServlet转发到BServlet,那么AServlet和BServlet可以共享request域中的数据;
l ServletContext:一个应用只创建一个ServletContext对象,所以在ServletContext中的数据可以在整个应用中共享,只要不启动服务器,那么ServletContext中的数据就可以共享;
l HttpSession:一个会话创建一个HttpSession对象,同一会话中的多个请求中可以共享session中的数据;
下载是session的域方法:
l void setAttribute(String name, Object value):用来存储一个对象,也可以称之为存储一个域属性,例如:session.setAttribute(“xxx”, “XXX”),在session中保存了一个域属性,域属性名称为xxx,域属性的值为XXX。请注意,如果多次调用该方法,并且使用相同的name,那么会覆盖上一次的值,这一特性与Map相同;
l Object getAttribute(String name):用来获取session中的数据,当前在获取之前需要先去存储才行,例如:String value = (String) session.getAttribute(“xxx”);,获取名为xxx的域属性;
l void removeAttribute(String name):用来移除HttpSession中的域属性,如果参数name指定的域属性不存在,那么本方法什么都不做;
l Enumeration getAttributeNames():获取所有域属性的名称;
需要的页面:
l login.jsp:登录页面,提供登录表单;
l index1.jsp:主页,显示当前用户名称,如果没有登录,显示您还没登录;
l index2.jsp:主页,显示当前用户名称,如果没有登录,显示您还没登录;
Servlet:
l LoginServlet:在login.jsp页面提交表单时,请求本Servlet。在本Servlet中获取用户名、密码进行校验,如果用户名、密码错误,显示“用户名或密码错误”,如果正确保存用户名session中,然后重定向到index1.jsp;
当用户没有登录时访问index1.jsp或index2.jsp,显示“您还没有登录”。如果用户在login.jsp登录成功后到达index1.jsp页面会显示当前用户名,而且不用再次登录去访问index2.jsp也会显示用户名。因为多次请求在一个会话范围,index1.jsp和index2.jsp都会到session中获取用户名,session对象在一个会话中是相同的,所以都可以获取到用户名!
login.jsp
|
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>login.jsp</title> </head> <body> <h1>login.jsp</h1> <hr/> <form action="/day06_4/LoginServlet" method="post"> 用户名:<input type="text" name="username" /><br/> <input type="submit" value="Submit"/> </form> </body> </html> |
index1.jsp
|
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>index1.jsp</title> </head> <body> <h1>index1.jsp</h1> <% String username = (String)session.getAttribute("username"); if(username == null) { out.print("您还没有登录!"); } else { out.print("用户名:" + username); } %> <hr/> <a href="/day06_4/index2.jsp">index2</a> </body> </html> |
index2.jsp
|
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>index2.jsp</title> </head> <body> <h1>index2.jsp</h1> <% String username = (String)session.getAttribute("username"); if(username == null) { out.print("您还没有登录!"); } else { out.print("用户名:" + username); } %> <hr/> <a href="/day06_4/index1.jsp">index1</a> </body> </html> |
LoginServlet
|
public class LoginServlet extends HttpServlet { public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.setCharacterEncoding("utf-8"); response.setContentType("text/html;charset=utf-8"); String username = request.getParameter("username"); if(username.equalsIgnoreCase("itcast")) { response.getWriter().print("用户名或密码错误!"); } else { HttpSession session = request.getSession(); session.setAttribute("username", username); response.sendRedirect("/day06_4/index1.jsp"); } } } |
session底层是依赖Cookie的!我们来理解一下session的原理吧!
当我首次去银行时,因为还没有账号,所以需要开一个账号,我获得的是银行卡,而银行这边的数据库中留下了我的账号,我的钱是保存在银行的账号中,而我带走的是我的卡号。
当我再次去银行时,只需要带上我的卡,而无需再次开一个账号了。只要带上我的卡,那么我在银行操作的一定是我的账号!
当首次使用session时,服务器端要创建session,session是保存在服务器端,而给客户端的session的id(一个cookie中保存了sessionId)。客户端带走的是sessionId,而数据是保存在session中。
当客户端再次访问服务器时,在请求中会带上sessionId,而服务器会通过sessionId找到对应的session,而无需再创建新的session。

session保存在服务器,而sessionId通过Cookie发送给客户端,但这个Cookie的生命不-1,即只在浏览器内存中存在,也就是说如果用户关闭了浏览器,那么这个Cookie就丢失了。
当用户再次打开浏览器访问服务器时,就不会有sessionId发送给服务器,那么服务器会认为你没有session,所以服务器会创建一个session,并在响应中把sessionId中到Cookie中发送给客户端。
你可能会说,那原来的session对象会怎样?当一个session长时间没人使用的话,服务器会把session删除了!这个时长在Tomcat中配置是30分钟,可以在${CATALANA}/conf/web.xml找到这个配置,当然你也可以在自己的web.xml中覆盖这个配置!
web.xml
|
<session-config> <session-timeout>30</session-timeout> </session-config> |
session失效时间也说明一个问题!如果你打开网站的一个页面开始长时间不动,超出了30分钟后,再去点击链接或提交表单时你会发现,你的session已经丢失了!
l String getId():获取sessionId;
l int getMaxInactiveInterval():获取session可以的最大不活动时间(秒),默认为30分钟。当session在30分钟内没有使用,那么Tomcat会在session池中移除这个session;
l void setMaxInactiveInterval(int interval):设置session允许的最大不活动时间(秒),如果设置为1秒,那么只要session在1秒内不被使用,那么session就会被移除;
l long getCreationTime():返回session的创建时间,返回值为当前时间的毫秒值;
l long getLastAccessedTime():返回session的最后活动时间,返回值为当前时间的毫秒值;
l void invalidate():让session失效!调用这个方法会被session失效,当session失效后,客户端再次请求,服务器会给客户端创建一个新的session,并在响应中给客户端新session的sessionId;
l boolean isNew():查看session是否为新。当客户端第一次请求时,服务器为客户端创建session,但这时服务器还没有响应客户端,也就是还没有把sessionId响应给客户端时,这时session的状态为新。
我们知道session依赖Cookie,那么session为什么依赖Cookie呢?因为服务器需要在每次请求中获取sessionId,然后找到客户端的session对象。那么如果客户端浏览器关闭了Cookie呢?那么session是不是就会不存在了呢?
其实还有一种方法让服务器收到的每个请求中都带有sessioinId,那就是URL重写!在每个页面中的每个链接和表单中都添加名为jSessionId的参数,值为当前sessionid。当用户点击链接或提交表单时也服务器可以通过获取jSessionId这个参数来得到客户端的sessionId,找到sessoin对象。
index.jsp
|
<body> <h1>URL重写</h1> <a href=‘/day06_5/index.jsp;jsessionid=<%=session.getId() %>‘ >主页</a> <form action=‘/day06_5/index.jsp;jsessionid=<%=session.getId() %>‘ method="post"> <input type="submit" value="提交"/> </form> </body> |
也可以使用response.encodeURL()对每个请求的URL处理,这个方法会自动追加jsessionid参数,与上面我们手动添加是一样的效果。
|
<a href=‘<%=response.encodeURL("/day06_5/index.jsp") %>‘ >主页</a> <form action=‘<%=response.encodeURL("/day06_5/index.jsp") %>‘ method="post"> <input type="submit" value="提交"/> </form> |
使用response.encodeURL()更加“智能”,它会判断客户端浏览器是否禁用了Cookie,如果禁用了,那么这个方法在URL后面追加jsessionid,否则不会追加。
在我们注册时,如果没有验证码的话,我们可以使用URLConnection来写一段代码发出注册请求。甚至可以使用while(true)来注册!那么服务器就废了!
验证码可以去识别发出请求的是人还是程序!当然,如果聪明的程序可以去分析验证码图片!但分析图片也不是一件容易的事,因为一般验证码图片都会带有干扰线,人都看不清,那么程序一定分析不出来。
现在我们已经有了cn.itcast.utils.VerifyCode类,这个类可以生成验证码图片!下面来看一个小例子。
|
public void fun1() throws IOException { // 创建验证码类 VerifyCode vc = new VerifyCode(); // 获取随机图片 BufferedImage image = vc.getImage(); // 获取刚刚生成的随机图片上的文本 String text = vc.getText(); System.out.println(text); // 保存图片 FileOutputStream out = new FileOutputStream("F:/xxx.jpg"); VerifyCode.output(image, out); } |
我们需要写一个VerifyCodeServlet,在这个Servlet中我们生成动态图片,然后它图片写入到response.getOutputStream()流中!然后让页面的<img>元素指定这个VerifyCodServlet即可。
VerifyCodeServlet
|
public class VerifyCodeServlet extends HttpServlet { public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { VerifyCode vc = new VerifyCode(); BufferedImage image = vc.getImage(); String text = vc.getText(); System.out.println("text:" + text); VerifyCode.output(image, response.getOutputStream()); } } |
index.jsp
|
<script type="text/javascript"> function _change() { var imgEle = document.getElementById("vCode"); imgEle.src = "/day06_6/VerifyCodeServlet?" + new Date().getTime(); } </script> ... <body> <h1>验证码</h1> <img id="vCode" src="/day06_6/VerifyCodeServlet"/> <a href="javascript:_change()">看不清,换一张</a> </body> |
|
<form action="/day06_6/RegistServlet" method="post"> 用户名:<input type="text" name="username"/><br/> 验证码:<input type="text" name="code" size="3"/> <img id="vCode" src="/day06_6/VerifyCodeServlet"/> <a href="javascript:_change()">看不清,换一张</a> <br/> <input type="submit" value="Submit"/> </form> |
修改VerifyCodeServlet
|
public class VerifyCodeServlet extends HttpServlet { public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { VerifyCode vc = new VerifyCode(); BufferedImage image = vc.getImage(); request.getSession().setAttribute("vCode", vc.getText()); VerifyCode.output(image, response.getOutputStream()); } } |
RegistServlet
|
public class RegistServlet extends HttpServlet { public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.setCharacterEncoding("utf-8"); response.setContentType("text/html;charset=utf-8"); String username = request.getParameter("username"); String vCode = request.getParameter("code"); String sessionVerifyCode = (String)request.getSession().getAttribute("vCode"); if(vCode.equalsIgnoreCase(sessionVerifyCode)) { response.getWriter().print(username + ", 恭喜!注册成功!"); } else { response.getWriter().print("验证码错误!"); } } } |
l VerifyCodeServlet:
Ø 生成验证码:VerifyCode vc = new VerifyCode(); BufferedImage image = vc.getImage();
Ø 在session中保存验证码文本:request.getSession.getAttribute(“vCode”, vc.getText());
Ø 把验证码输出到页面:VerifyCode.output(image, response.getOutputStream);
l regist.jsp:
Ø 表单中包含username和code字段;
Ø 在表单中给出<img>指向VerifyCodeServlet,用来在页面中显示验证码图片;
Ø 提供“看不清,换一张”链接,指向_change()函数;
Ø 提交到RegistServlet;
l RegistServlet:
Ø 获取表单中的username和code;
Ø 获取session中的vCode;
Ø 比较code和vCode是否相同;
Ø 相同说明用户输入的验证码正确,否则输入验证码错误。
JSP指令的格式:<%@指令名 attr1=”” attr2=”” %>,一般都会把JSP指令放到JSP文件的最上方,但这不是必须的。
JSP中有三大指令:page、include、taglib,最为常用,也最为复杂的就是page指令了。
page指令是最为常用的指定,也是属性最多的属性!
page指令没有必须属性,都是可选属性。例如<%@page %>,没有给出任何属性也是可以的!
在JSP页面中,任何指令都可以重复出现!
<%@ page language=”java”%>
<%@ page import=”java.util.*”%>
<%@ page pageEncoding=”utf-8”%>
这也是可以的!
pageEncoding指定当前JSP页面的编码!这个编码是给服务器看的,服务器需要知道当前JSP使用的编码,不然服务器无法正确把JSP编译成java文件。所以这个编码只需要与真实的页面编码一致即可!在MyEclipse中,在JSP文件上点击右键,选择属性就可以看到当前JSP页面的编码了。
contentType属性与response.setContentType()方法的作用相同!它会完成两项工作,一是设置响应字符流的编码,二是设置content-type响应头。例如:<%@ contentType=”text/html;charset=utf-8”%>,它会使“真身”中出现response.setContentType(“text/html;charset=utf-8”)。
无论是page指令的pageEncoding还是contentType,它们的默认值都是ISO-8859-1,我们知道ISO-8859-1是无法显示中文的,所以JSP页面中存在中文的话,一定要设置这两个属性。
其实pageEncoding和contentType这两个属性的关系很“暧昧”:
l 当设置了pageEncoding,而没设置contentType时: contentType的默认值为pageEncoding;
l 当设置了contentType,而没设置pageEncoding时: pageEncoding的默认值与contentType;
也就是说,当pageEncoding和contentType只出现一个时,那么另一个的值与出现的值相同。如果两个都不出现,那么两个属性的值都是ISO-8859-1。所以通过我们至少设置它们两个其中一个!
import是page指令中一个很特别的属性!
import属性值对应“真身”中的import语句。
import属性值可以使逗号:<%@page import=”java.net.*,java.util.*,java.sql.*”%>
import属性是唯一可以重复出现的属性:
<%@page import=”java.util.*” import=”java.net.*” import=”java.sql.*”%>
但是,我们一般会使用多个page指令来导入多个包:
<%@ page import=”java.util.*”%>
<%@ page import=”java.net.*”%>
<%@ page import=”java.text.*”%>
我们知道,在一个JSP页面出错后,Tomcat会响应给用户错误信息(500页面)!如果你不希望Tomcat给用户输出错误信息,那么可以使用page指令的errorPage来指定自己的错误页!也就是自定义错误页面,例如:<%@page errorPage=”xxx.jsp”%>。这时,在当前JSP页面出现错误时,会请求转发到xxx.jsp页面。
a.jsp
|
<%@ page import="java.util.*" pageEncoding="UTF-8"%> <%@ page errorPage="b.jsp" %> <% if(true) throw new Exception("哈哈~"); %> |
b.jsp
|
<%@ page pageEncoding="UTF-8"%> <body> <h1>出错啦!</h1> </body> </html> |
在上面代码中,a.jsp抛出异常后,会请求转发到b.jsp。在浏览器的地址栏中还是a.jsp,因为是请求转发!
而且客户端浏览器收到的响应码为200,表示请求成功!如果希望客户端得到500,那么需要指定b.jsp为错误页面。
|
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <%@ page isErrorPage="true" %> <html> <body> <h1>出错啦!</h1> <%=exception.getMessage() %> </body> </html> |
注意,当isErrorPage为true时,说明当前JSP为错误页面,即专门处理错误的页面。那么这个页面中就可以使用一个内置对象exception了。其他页面是不能使用这个内置对象的!
温馨提示:IE会在状态码为500时,并且响应正文的长度小于等于512B时不给予显示!而是显示“网站无法显示该页面”字样。这时你只需要添加一些响应内容即可,例如上例中的b.jsp中我给出一些内容,IE就可以正常显示了!
2.3.1 web.xml中配置错误页面
不只可以通过JSP的page指令来配置错误页面,还可以在web.xml文件中指定错误页面。这种方式其实与page指令无关,但想来想去还是在这个位置来讲解比较合适!
web.xml
|
<error-page> <error-code>404</error-code> <location>/error404.jsp</location> </error-page> <error-page> <error-code>500</error-code> <location>/error500.jsp</location> </error-page> <error-page> <exception-type>java.lang.RuntimeException</exception-type> <location>/error.jsp</location> </error-page> |
<error-page>有两种使用方式:
l <error-code>和<location>子元素;
l <exception-type>和<location>子元素;
其中<error-code>是指定响应码;<location>指定转发的页面;<exception-type>是指定抛出的异常类型。
在上例中:
l 当出现404时,会跳转到error404.jsp页面;
l 当出现RuntimeException异常时,会跳转到error.jsp页面;
l 当出现非RuntimeException的异常时,会跳转到error500.jsp页面。
这种方式会在控制台看到异常信息!而使用page指令时不会在控制台打印异常信息。
buffer表示当前JSP的输出流(out隐藏对象)的缓冲区大小,默认为8kb。
authFlush表示在out对象的缓冲区满时如果处理!当authFlush为true时,表示缓冲区满时把缓冲区数据输出到客户端;当authFlush为false时,表示缓冲区满时,抛出异常。authFlush的默认值为true。
这两个属性一般我们也不会去特意设置,都是保留默认值!
后面我们会讲解EL表达式语言,page指令的isElIgnored属性表示当前JSP页面是否忽略EL表达式,默认值为false,表示不忽略(即支持)。
l language:只能是Java,这个属性可以看出JSP最初设计时的野心!希望JSP可以转换成其他语言!但是,到现在JSP也只能转换成Java代码;
l info:JSP说明性信息;
l isThreadSafe:默认为false,为true时,JSP生成的Servlet会去实现一个过时的标记接口SingleThreadModel,这时JSP就只能处理单线程的访问;
l session:默认为true,表示当前JSP页面可以使用session对象,如果为false表示当前JSP页面不能使用session对象;
l extends:指定当前JSP页面生成的Servlet的父类;
在web.xml页面中配置<jsp-config>也可以完成很多page指定的功能!
|
<jsp-config> <jsp-property-group> <url-pattern>*.jsp</url-pattern> <el-ignored>true</el-ignored> <page-encoding>UTF-8</page-encoding> <scripting-invalid>true</scripting-invalid> </jsp-property-group> </jsp-config> |
include指令表示静态包含!即目的是把多个JSP合并成一个JSP文件!
include指令只有一个属性:file,指定要包含的页面,例如:<%@include file=”b.jsp”%>。
静态包含:当hel.jsp页面包含了lo.jsp页面后,在编译hel.jsp页面时,需要把hel.jsp和lo.jsp页面合并成一个文件,然后再编译成Servlet(Java文件)。

很明显,在ol.jsp中在使用username变量,而这个变量在hel.jsp中定义的,所以只有这两个JSP文件合并后才能使用。通过include指定完成对它们的合并!
这个指令需要在学习了自定义标签后才会使用,现在只能做了了解而已!
在JSP页面中使用第三方的标签库时,需要使用taglib指令来“导包”。例如:
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
其中prefix表示标签的前缀,这个名称可以随便起。uri是由第三方标签库定义的,所以你需要知道第三方定义的uri。
在JSP中无需创建就可以使用的9个对象,它们是:
l out(JspWriter):等同与response.getWriter(),用来向客户端发送文本数据;
l config(ServletConfig):对应“真身”中的ServletConfig;
l page(当前JSP的真身类型):当前JSP页面的“this”,即当前对象;
l pageContext(PageContext):页面上下文对象,它是最后一个没讲的域对象;
l exception(Throwable):只有在错误页面中可以使用这个对象;
l request(HttpServletRequest):即HttpServletRequest类的对象;
l response(HttpServletResponse):即HttpServletResponse类的对象;
l application(ServletContext):即ServletContext类的对象;
l session(HttpSession):即HttpSession类的对象,不是每个JSP页面中都可以使用,如果在某个JSP页面中设置<%@page session=”false”%>,说明这个页面不能使用session。
在这9个对象中有很多是极少会被使用的,例如:config、page、exception基本不会使用。
在这9个对象中有两个对象不是每个JSP页面都可以使用的:exception、session。
在这9个对象中有很多前面已经学过的对象:out、request、response、application、session、config。
我们知道JSP页面的内容出现在“真身”的_jspService()方法中,而在_jspService()方法开头部分已经创建了9大内置对象。
|
public void _jspService(HttpServletRequest request, HttpServletResponse response) throws java.io.IOException, ServletException { PageContext pageContext = null; HttpSession session = null; ServletContext application = null; ServletConfig config = null; JspWriter out = null; Object page = this; JspWriter _jspx_out = null; PageContext _jspx_page_context = null; try { response.setContentType("text/html;charset=UTF-8"); pageContext = _jspxFactory.getPageContext(this, request, response, null, true, 8192, true); _jspx_page_context = pageContext; application = pageContext.getServletContext(); config = pageContext.getServletConfig(); session = pageContext.getSession(); out = pageContext.getOut(); _jspx_out = out; 从这里开始,才是JSP页面的内容 }… |
在JavaWeb中一共四个域对象,其中Servlet中可以使用的是request、session、application三个对象,而在JSP中可以使用pageContext、request、session、application四个域对象。
pageContext 对象是PageContext类型,它的主要功能有:
l 域对象功能;
l 代理其它域对象功能;
l 获取其他内置对象;
pageContext也是域对象,它的范围是当前页面。它的范围也是四个域对象中最小的!
l void setAttribute(String name, Object value);
l Object getAttrbiute(String name, Object value);
l void removeAttribute(String name, Object value);
还可以使用pageContext来代理其它3个域对象的功能,也就是说可以使用pageContext向request、session、application对象中存取数据,例如:
|
pageContext.setAttribute("x", "X"); pageContext.setAttribute("x", "XX", PageContext.REQUEST_SCOPE); pageContext.setAttribute("x", "XXX", PageContext.SESSION_SCOPE); pageContext.setAttribute("x", "XXXX", PageContext.APPLICATION_SCOPE); |
l void setAttribute(String name, Object value, int scope):在指定范围中添加数据;
l Object getAttribute(String name, int scope):获取指定范围的数据;
l void removeAttribute(String name, int scope):移除指定范围的数据;
l Object findAttribute(String name):依次在page、request、session、application范围查找名称为name的数据,如果找到就停止查找。这说明在这个范围内有相同名称的数据,那么page范围的优先级最高!
一个pageContext对象等于所有内置对象,即1个当9个。这是因为可以使用pageContext对象获取其它8个内置对象:
l JspWriter getOut():获取out内置对象;
l ServletConfig getServletConfig():获取config内置对象;
l Object getPage():获取page内置对象;
l ServletRequest getRequest():获取request内置对象;
l ServletResponse getResponse():获取response内置对象;
l HttpSession getSession():获取session内置对象;
l ServletContext getServletContext():获取application内置对象;
l Exception getException():获取exception内置对象;
动作标签的作用是用来简化Java脚本的!
JSP动作标签是JavaWeb内置的动作标签,它们是已经定义好的动作标签,我们可以拿来直接使用。
如果JSP动作标签不够用时,还可以使用自定义标签(今天不讲)。JavaWeb一共提供了20个JSP动作标签,但有很多基本没有用,这里只介绍一些有坐标的动作标签。
JSP动作标签的格式:<jsp:标签名 …>
<jsp:include>标签的作用是用来包含其它JSP页面的!你可能会说,前面已经学习了include指令了,它们是否相同呢?虽然它们都是用来包含其它JSP页面的,但它们的实现的级别是不同的!
include指令是在编译级别完成的包含,即把当前JSP和被包含的JSP合并成一个JSP,然后再编译成一个Servlet。
include动作标签是在运行级别完成的包含,即当前JSP和被包含的JSP都会各自生成Servlet,然后在执行当前JSP的Servlet时完成包含另一个JSP的Servlet。它与RequestDispatcher的include()方法是相同的!
hel.jsp
|
<body> <h1>hel.jsp</h1> <jsp:include page="lo.jsp" /> </body> |
lo.jsp
|
<% out.println("<h1>lo.jsp</h1>"); %> |

其实<jsp:include>在“真身”中不过是一句方法调用,即调用另一个Servlet而已。
forward标签的作用是请求转发!forward标签的作用与RequestDispatcher#forward()方法相同。
hel.jsp
|
|
lo.jsp
|
<% out.println("<h1>lo.jsp</h1>"); %> |
注意,最后客户端只能看到lo.jsp的输出,而看不到hel.jsp的内容。也就是说在hel.jsp中的<h1>hel.jsp</h1>是不会发送到客户端的。<jsp:forward>的作用是“别在显示我,去显示它吧!”。
还可以在<jsp:include>和<jsp:forward>标签中使用<jsp:param>子标签,它是用来传递参数的。下面用<jsp:include>来举例说明<jsp:param>的使用。
|
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>a.jsp</title> </head> <body> <h1>a.jsp</h1> <hr/> <jsp:include page="/b.jsp"> <jsp:param value="zhangSan" name="username"/> </jsp:include> </body> </html> |
|
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>b.jsp</title> </head> <body> <h1>b.jsp</h1> <hr/> <% String username = request.getParameter("username"); out.print("你好:" + username); %> </body> </html> |
JavaBean是一种规范,也就是对类的要求。它要求Java类的成员变量提供getter/setter方法,这样的成员变量被称之为JavaBean属性。
JavaBean还要求类必须提供仅有的无参构造器,例如:public User() {…}
User.java
|
package cn.itcast.domain; public class User { private String username; private String password; public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } } |
JavaBean属性是具有getter/setter方法的成员变量。
l 也可以只提供getter方法,这样的属性叫只读属性;
l 也可以只提供setter方法,这样的属性叫只写属性;
l 如果属性类型为boolean类型,那么读方法的格式可以是get或is。例如名为abc的boolean类型的属性,它的读方法可以是getAbc(),也可以是isAbc();
JavaBean属性名要求:前两个字母要么都大写,要么都小写:
|
public class User { private String iD; private String ID; private String qQ; private String QQ; … } |
JavaBean可能存在属性,但不存在这个成员变量,例如:
|
public class User { public String getUsername() { return "zhangSan"; } } |
上例中User类有一个名为username的只读属性!但User类并没有username这个成员变量!
还可以并变态一点:
|
public class User { private String hello; public String getUsername() { return hello; } public void setUsername(String username) { this.hello = username; } } |
上例中User类中有一个名为username的属性,它是可读可写的属性!而Use类的成员变量名为hello!也就是说JavaBean的属性名取决与方法名称,而不是成员变量的名称。但通常没有人做这么变态的事情。
内省的目标是得到JavaBean属性的读、写方法的反射对象,通过反射对JavaBean属性进行操作的一组API。例如User类有名为username的JavaBean属性,通过两个Method对象(一个是getUsenrmae(),一个是setUsername())来操作User对象。
如果你还不能理解内省是什么,那么我们通过一个问题来了解内省的作用。现在我们有一个Map,内容如下:
|
Map<String,String> map = new HashMap<String,String>(); map.put("username", "admin"); map.put("password", "admin123"); |
|
public class User { private String username; private String password; public User(String username, String password) { this.username = username; this.password = password; } public User() { } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public String toString() { return "User [username=" + username + ", password=" + password + "]"; } } |
现在需要把map的数据封装到一个User对象中!User类有两个JavaBean属性,一个叫username,另一个叫password。
你可能想到的是反射,通过map的key来查找User类的Field!这么做是没有问题的,但我们要知道类的成员变量是私有的,虽然也可以通过反射去访问类的私有的成员变量,但我们也要清楚反射访问私有的东西是有“危险”的,所以还是建议通过getUsername和setUsername来访问JavaBean属性。
我们这里不想去对JavaBean规范做过多的介绍,所以也就不在多介绍BeanInfo的“出身”了。你只需要知道如何得到它,以及BeanInfo有什么。
通过java.beans.Introspector的getBeanInfo()方法来获取java.beans.BeanInfo实例。
|
BeanInfo beanInfo = Introspector.getBeanInfo(User.class); |
通过BeanInfo可以得到这个类的所有JavaBean属性的PropertyDescriptor对象。然后就可以通过PropertyDescriptor对象得到这个属性的getter/setter方法的Method对象了。
|
PropertyDescriptor[] pds = beanInfo.getPropertyDescriptors(); |
每个PropertyDescriptor对象对应一个JavaBean属性:
l String getName():获取JavaBean属性名称;
l Method getReadMethod:获取属性的读方法;
l Method getWriteMethod:获取属性的写方法。
|
public void fun1() throws Exception { Map<String,String> map = new HashMap<String,String>(); map.put("username", "admin"); map.put("password", "admin123"); BeanInfo beanInfo = Introspector.getBeanInfo(User.class); PropertyDescriptor[] pds = beanInfo.getPropertyDescriptors(); User user = new User(); for(PropertyDescriptor pd : pds) { String name = pd.getName(); String value = map.get(name); if(value != null) { Method writeMethod = pd.getWriteMethod(); writeMethod.invoke(user, value); } } System.out.println(user); } |
提到内省,不能不提commons-beanutils这个工具。它底层使用了内省,对内省进行了大量的简化!
使用beanutils需要的jar包:
l commons-beanutils.jar;
l commons-logging.jar;
|
User user = new User(); BeanUtils.setProperty(user, "username", "admin"); BeanUtils.setProperty(user, "password", "admin123"); System.out.println(user); |
|
User user = new User("admin", "admin123"); String username = BeanUtils.getProperty(user, "username"); String password = BeanUtils.getProperty(user, "password"); System.out.println("username=" + username + ", password=" + password); |
|
Map<String,String> map = new HashMap<String,String>(); map.put("username", "admin"); map.put("password", "admin123"); User user = new User(); BeanUtils.populate(user, map); System.out.println(user); |
在JSP中与JavaBean相关的标签有:
l <jsp:useBean>:创建JavaBean对象;
l <jsp:setProperty>:设置JavaBean属性;
l <jsp:getProperty>:获取JavaBean属性;
我们需要先创建一个JavaBean类:
User.java
|
package cn.itcast.domain; public class User { private String username; private String password; public User(String username, String password) { this.username = username; this.password = password; } public User() { } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public String toString() { return "User [username=" + username + ", password=" + password + "]"; } } |
<jsp:useBean>标签的作用是创建JavaBean对象:
l 在当前JSP页面创建JavaBean对象;
l 把创建的JavaBean对象保存到域对象中;
|
<jsp:useBean id="user1" class="cn.itcast.domain.User" /> |
上面代码表示在当前JSP页面中创建User类型的对象,并且把它保存到page域中了。下面我们把<jsp:useBean>标签翻译成Java代码:
|
<% cn.itcast.domain.User user1 = new cn.itcast.domain.User(); pageContext.setAttribute("user1", user1); %> |
这说明我们可以在JSP页面中完成下面的操作:
|
<jsp:useBean id="user1" class="cn.itcast.domain.User" /> <%=user1 %> <% out.println(pageContext.getAttribute("user1")); %> |
<jsp:useBean>标签默认是把JavaBean对象保存到page域,还可以通过scope标签属性来指定保存的范围:
|
<jsp:useBean id="user1" class="cn.itcast.domain.User" scope="page"/> <jsp:useBean id="user2" class="cn.itcast.domain.User" scope="request"/> <jsp:useBean id="user3" class="cn.itcast.domain.User" scope="session"/> <jsp:useBean id="user4" class="cn.itcast.domain.User" scope="applicatioin"/> |
<jsp:useBean>标签其实不一定会创建对象!!!其实它会先在指定范围中查找这个对象,如果对象不存在才会创建,我们需要重新对它进行翻译:
|
<jsp:useBean id="user4" class="cn.itcast.domain.User" scope="applicatioin"/> |
|
<% cn.itcast.domain.User user4 = (cn.itcast.domain.User)application.getAttribute("user4"); if(user4 == null) { user4 = new cn.itcast.domain.User(); application.setAttribute("user4", user4); } %> |
<jsp:setProperty>标签的作用是给JavaBean设置属性值,而<jsp:getProperty>是用来获取属性值。在使用它们之前需要先创建JavaBean:
|
<jsp:useBean id="user1" class="cn.itcast.domain.User" /> <jsp:setProperty property="username" name="user1" value="admin"/> <jsp:setProperty property="password" name="user1" value="admin123"/> 用户名:<jsp:getProperty property="username" name="user1"/><br/> 密 码:<jsp:getProperty property="password" name="user1"/><br/> |
JSP2.0要把html和css分离、要把html和javascript分离、要把Java脚本替换成标签。标签的好处是非Java人员都可以使用。
JSP2.0 – 纯标签页面,即:不包含<% … %>、<%! … %>,以及<%= … %>
EL(Expression Language)是一门表达式语言,它对应<%=…%>。我们知道在JSP中,表达式会被输出,所以EL表达式也会被输出。
格式:${…}
例如:${1 + 2}
如果希望整个JSP忽略EL表达式,需要在page指令中指定isELIgnored=”true”。
如果希望忽略某个EL表达式,可以在EL表达式之前添加“\”,例如:\${1 + 2}。
|
运算符 |
说明 |
范例 |
结果 |
|
+ |
加 |
${17+5} |
22 |
|
- |
减 |
${17-5} |
12 |
|
* |
乘 |
${17*5} |
85 |
|
/或div |
除 |
${17/5}或${17 div 5} |
3 |
|
%或mod |
取余 |
${17%5}或${17 mod 5} |
2 |
|
==或eq |
等于 |
${5==5}或${5 eq 5} |
true |
|
!=或ne |
不等于 |
${5!=5}或${5 ne 5} |
false |
|
<或lt |
小于 |
${3<5}或${3 lt 5} |
true |
|
>或gt |
大于 |
${3>5}或${3 gt 5} |
false |
|
<=或le |
小于等于 |
${3<=5}或${3 le 5} |
true |
|
>=或ge |
大于等于 |
${3>=5}或${3 ge 5} |
false |
|
&&或and |
并且 |
${true&&false}或${true and false} |
false |
|
!或not |
非 |
${!true}或${not true} |
false |
|
||或or |
或者 |
${true||false}或${true or false} |
true |
|
empty |
是否为空 |
${empty “”},可以判断字符串、数据、集合的长度是否为0,为0返回true。empty还可以与not或!一起使用。${not empty “”} |
true |
当EL表达式的值为null时,会在页面上显示空白,即什么都不显示。
先来了解一下EL表达式的格式!现在还不能演示它,因为需要学习了EL11个内置对象后才方便显示它。
l 操作List和数组:${list[0]}、${arr[0]};
l 操作bean的属性:${person.name}、${person[‘name’]},对应person.getName()方法;
l 操作Map的值:${map.key}、${map[‘key’]},对应map.get(key)。
EL一共11个内置对象,无需创建即可以使用。这11个内置对象中有10个是Map类型的,最后一个是pageContext对象。
l pageScope
l requestScope
l sessionScope
l applicationScope
l param;
l paramValues;
l header;
l headerValues;
l initParam;
l cookie;
l pageContext;
域内置对象一共有四个:
l pageScope:${pageScope.name}等同与pageContext.getAttribute(“name”);
l requestScope:${requestScope.name}等同与request.getAttribute(“name”);
l sessionScoep: ${sessionScope.name}等同与session.getAttribute(“name”);
l applicationScope:${applicationScope.name}等同与application.getAttribute(“name”);
如果在域中保存的是JavaBean对象,那么可以使用EL来访问JavaBean属性。因为EL只做读取操作,所以JavaBean一定要提供get方法,而set方法没有要求。
Person.java
|
public class Person { private String name; private int age; private String sex; public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } } |

全域查找:${person}表示依次在pageScope、requesScopet、sessionScope、appliationScope四个域中查找名字为person的属性。
param和paramValues这两个内置对象是用来获取请求参数的。
l param:Map<String,String>类型,param对象可以用来获取参数,与request.getParameter()方法相同。

注意,在使用EL获取参数时,如果参数不存在,返回的是空字符串,而不是null。这一点与使用request.getParameter()方法是不同的。

l paramValues:paramValues是Map<String, String[]>类型,当一个参数名,对应多个参数值时可以使用它。

header和headerValues是与请求头相关的内置对象:
l header: Map<String,String>类型,用来获取请求头。

l headerValues:headerValues是Map<String,String[]>类型。当一个请求头名称,对应多个值时,使用该对象,这里就不在赘述。
l initParam:initParam是Map<String,String>类型。它对应web.xml文件中的<context-param>参数。

l cookie:cookie是Map<String,Cookie>类型,其中key是Cookie的名字,而值是Cookie对象本身。

pageContext:pageContext是PageContext类型!可以使用pageContext对象调用getXXX()方法,例如pageContext.getRequest(),可以${pageContext.request}。也就是读取JavaBean属性!!!
|
EL表达式 |
说明 |
|
${pageContext.request.queryString} |
pageContext.getRequest().getQueryString(); |
|
${pageContext.request.requestURL} |
pageContext.getRequest().getRequestURL(); |
|
${pageContext.request.contextPath} |
pageContext.getRequest().getContextPath(); |
|
${pageContext.request.method} |
pageContext.getRequest().getMethod(); |
|
${pageContext.request.protocol} |
pageContext.getRequest().getProtocol(); |
|
${pageContext.request.remoteUser} |
pageContext.getRequest().getRemoteUser(); |
|
${pageContext.request.remoteAddr} |
pageContext.getRequest().getRemoteAddr(); |
|
${pageContext.session.new} |
pageContext.getSession().isNew(); |
|
${pageContext.session.id} |
pageContext.getSession().getId(); |
|
${pageContext.servletContext.serverInfo} |
pageContext.getServletContext().getServerInfo(); |
EL函数库是由第三方对EL的扩展,我们现在学习的EL函数库是由JSTL添加的。JSTL明天再学!
EL函数库就是定义一些有返回值的静态方法。然后通过EL语言来调用它们!当然,不只是JSTL可以定义EL函数库,我们也可以自定义EL函数库。
EL函数库中包含了很多对字符串的操作方法,以及对集合对象的操作。例如:${fn:length(“abc”)}会输出3,即字符串的长度。
因为是第三方的东西,所以需要导入。导入需要使用taglib指令!
<%@ taglib prefix="fn" uri="http://java.sun.com/jsp/jstl/functions" %>
l String toUpperCase(String input):
l String toLowerCase(String input):
l int indexOf(String input, String substring):
l boolean contains(String input, String substring):
l boolean containsIgnoreCase(String input, String substring):
l boolean startsWith(String input, String substring):
l boolean endsWith(String input, String substring):
l String substring(String input, int beginIndex, int endIndex):
l String substringAfter(String input, String substring):
l substringBefore(String input, String substring):
l String escapeXml(String input):”、’、<、>、&
l String trim(String input):
l String replace(String input, String substringBefore, String substringAfter):
l String[] split(String input, String delimiters):
l int length(Object obj):
l String join(String array[], String separator):
|
<%@taglib prefix="fn" uri="http://java.sun.com/jsp/jstl/functions" %> … String[] strs = {"a", "b","c"}; List list = new ArrayList(); list.add("a"); pageContext.setAttribute("arr", strs); pageContext.setAttribute("list", list); %> ${fn:length(arr) }<br/><!--3--> ${fn:length(list) }<br/><!--1--> ${fn:toLowerCase("Hello") }<br/> <!-- hello --> ${fn:toUpperCase("Hello") }<br/> <!-- HELLO --> ${fn:contains("abc", "a")}<br/><!-- true --> ${fn:containsIgnoreCase("abc", "Ab")}<br/><!-- true --> ${fn:contains(arr, "a")}<br/><!-- true --> ${fn:containsIgnoreCase(list, "A")}<br/><!-- true --> ${fn:endsWith("Hello.java", ".java")}<br/><!-- true --> ${fn:startsWith("Hello.java", "Hell")}<br/><!-- true --> ${fn:indexOf("Hello-World", "-")}<br/><!-- 5 --> ${fn:join(arr, ";")}<br/><!-- a;b;c --> ${fn:replace("Hello-World", "-", "+")}<br/><!-- Hello+World --> ${fn:join(fn:split("a;b;c;", ";"), "-")}<br/><!-- a-b-c --> ${fn:substring("0123456789", 6, 9)}<br/><!-- 678 --> ${fn:substring("0123456789", 5, -1)}<br/><!-- 56789 --> ${fn:substringAfter("Hello-World", "-")}<br/><!-- World --> ${fn:substringBefore("Hello-World", "-")}<br/><!-- Hello --> ${fn:trim(" a b c ")}<br/><!-- a b c --> ${fn:escapeXml("<html></html>")}<br/> <!-- <html></html> --> |
l 写一个类,写一个有返回值的静态方法;
l 编写itcast.tld文件,可以参数fn.tld文件来写,把itcast.tld文件放到/WEB-INF目录下;
l 在页面中添加taglib指令,导入自定义标签库。
ItcastFuncations.java
|
package cn.itcast.el.funcations; public class ItcastFuncations { public static String test() { return "传智播客自定义EL函数库测试"; } } |
itcast.tld(放到classes下)
|
<?xml version="1.0" encoding="UTF-8" ?> <taglib xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-jsptaglibrary_2_0.xsd" version="2.0"> <tlib-version>1.0</tlib-version> <short-name>itcast</short-name> <uri>http://www.itcast.cn/jsp/functions</uri> <function> <name>test</name> <function-class>cn.itcast.el.funcations.ItcastFuncations</function-class> <function-signature>String test()</function-signature> </function> </taglib> |
index.jsp
数据库就是用来存储和管理数据的仓库!
数据库存储数据的优先:
l
可存储大量数据;
l 方便检索;
l 保持数据的一致性、完整性;
l 安全,可共享;
l 通过组合分析,可产生新数据。
l 没有数据库,使用磁盘文件存储数据;
l 层次结构模型数据库;
l 网状结构模型数据库;
l 关系结构模型数据库:使用二维表格来存储数据;
l 关系-对象模型数据库;
MySQL就是关系型数据库!
l Oracle:甲骨文;
l DB2:IBM;
l SQL Server:微软;
l Sybase:赛尔斯;
l MySQL:甲骨文;
我们现在所说的数据库泛指关“系型数据库管理系统(RDBMS - Relational database management system)”,即“数据库服务器”。

当我们安装了数据库服务器后,就可以在数据库服务器中创建数据库,每个数据库中还可以包含多张表。

数据库表就是一个多行多列的表格。在创建表时,需要指定表的列数,以及列名称,列类型等信息。而不用指定表格的行数,行数是没有上限的。下面是tab_student表的结构:

当把表格创建好了之后,就可以向表格中添加数据了。向表格添加数据是以行为单位的!下面是s_student表的记录:
|
s_id |
s_name |
s_age |
s_sex |
|
S_1001 |
zhangSan |
23 |
male |
|
S_1002 |
liSi |
32 |
female |
|
S_1003 |
wangWu |
44 |
male |
大家要学会区分什么是表结构,什么是表记录。
应用程序使用数据库完成对数据的存储!

参考:MySQL安装图解.doc
MySQL的数据存储目录为data,data目录通常在C:\Documents and Settings\All Users\Application Data\MySQL\MySQL Server 5.1\data位置。在data下的每个目录都代表一个数据库。
MySQL的安装目录下:
l bin目录中都是可执行文件;
l my.ini文件是MySQL的配置文件;
l 启动:net start mysql;
l 关闭:net stop mysql;
在启动mysql服务后,打开windows任务管理器,会有一个名为mysqld.exe的进程运行,所以mysqld.exe才是MySQL服务器程序。
在启动MySQL服务器后,我们需要使用管理员用户登录MySQL服务器,然后来对服务器进行操作。登录MySQL需要使用MySQL的客户端程序:mysql.exe
l 登录:mysql -u root -p 123 -h localhost;
Ø -u:后面的root是用户名,这里使用的是超级管理员root;
Ø -p:后面的123是密码,这是在安装MySQL时就已经指定的密码;
Ø -h:后面给出的localhost是服务器主机名,它是可以省略的,例如:mysql -u root -p 123;
l 退出:quit或exit;
在登录成功后,打开windows任务管理器,会有一个名为mysql.exe的进程运行,所以mysql.exe是客户端程序。
SQL(Structured Query Language)是“结构化查询语言”,它是对关系型数据库的操作语言。它可以应用到所有关系型数据库中,例如:MySQL、Oracle、SQL Server等。SQ标准(ANSI/ISO)有:
l SQL-92:1992年发布的SQL语言标准;
l SQL:1999:1999年发布的SQL语言标签;
l SQL:2003:2003年发布的SQL语言标签;
这些标准就与JDK的版本一样,在新的版本中总要有一些语法的变化。不同时期的数据库对不同标准做了实现。
虽然SQL可以用在所有关系型数据库中,但很多数据库还都有标准之后的一些语法,我们可以称之为“方言”。例如MySQL中的LIMIT语句就是MySQL独有的方言,其它数据库都不支持!当然,Oracle或SQL Server都有自己的方言。
l SQL语句可以单行或多行书写,以分号结尾;
l 可以用空格和缩进来来增强语句的可读性;
l 关键字不区别大小写,建议使用大写;
l DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;
l DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据);
l DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
l DQL(Data Query Language):数据查询语言,用来查询记录(数据)。
l 查看所有数据库名称:SHOW DATABASES;
l 切换数据库:USE mydb1,切换到mydb1数据库;
l 创建数据库:CREATE DATABASE [IF NOT EXISTS] mydb1;
创建数据库,例如:CREATE DATABASE mydb1,创建一个名为mydb1的数据库。如果这个数据已经存在,那么会报错。例如CREATE DATABASE IF NOT EXISTS mydb1,在名为mydb1的数据库不存在时创建该库,这样可以避免报错。
l 删除数据库:DROP DATABASE [IF EXISTS] mydb1;
删除数据库,例如:DROP DATABASE mydb1,删除名为mydb1的数据库。如果这个数据库不存在,那么会报错。DROP DATABASE IF EXISTS mydb1,就算mydb1不存在,也不会的报错。
l 修改数据库编码:ALTER DATABASE mydb1 CHARACTER SET utf8
修改数据库mydb1的编码为utf8。注意,在MySQL中所有的UTF-8编码都不能使用中间的“-”,即UTF-8要书写为UTF8。
MySQL与Java一样,也有数据类型。MySQL中数据类型主要应用在列上。
常用类型:
l int:整型
l double:浮点型,例如double(5,2)表示最多5位,其中必须有2位小数,即最大值为999.99;
l decimal:浮点型,在表示钱方面使用该类型,因为不会出现精度缺失问题;
l char:固定长度字符串类型;
l varchar:可变长度字符串类型;
l text:字符串类型;
l blob:字节类型;
l date:日期类型,格式为:yyyy-MM-dd;
l time:时间类型,格式为:hh:mm:ss
l timestamp:时间戳类型;
l 创建表:
CREATE TABLE 表名(
列名 列类型,
列名 列类型,
......
);
例如:
|
CREATE TABLE stu( sidCHAR(6), snameVARCHAR(20), ageINT, genderVARCHAR(10) ); |
再例如:
|
CREATE TABLE emp( eidCHAR(6), enameVARCHAR(50), ageINT, genderVARCHAR(6), birthdayDATE, hiredateDATE, salaryDECIMAL(7,2), resumeVARCHAR(1000) ); |
l 查看当前数据库中所有表名称:SHOW TABLES;
l 查看指定表的创建语句:SHOW CREATE TABLE emp,查看emp表的创建语句;
l 查看表结构:DESC emp,查看emp表结构;
l 删除表:DROP TABLE emp,删除emp表;
l 修改表:
1. 修改之添加列:给stu表添加classname列:
ALTER TABLE stu ADD (classname varchar(100));
2. 修改之修改列类型:修改stu表的gender列类型为CHAR(2):
ALTER TABLE stu MODIFY gender CHAR(2);
3. 修改之修改列名:修改stu表的gender列名为sex:
ALTER TABLE stu change gender sex CHAR(2);
4. 修改之删除列:删除stu表的classname列:
ALTER TABLE stu DROP classname;
5. 修改之修改表名称:修改stu表名称为student:
ALTER TABLE stu RENAME TO student;
语法:
INSERT INTO 表名(列名1,列名2, …) VALUES(值1, 值2)
|
INSERT INTO stu(sid, sname,age,gender) VALUES(‘s_1001‘, ‘zhangSan‘, 23, ‘male‘); |
|
INSERT INTO stu(sid, sname) VALUES(‘s_1001‘, ‘zhangSan‘); |
语法:
INSERT INTO 表名 VALUES(值1,值2,…)
因为没有指定要插入的列,表示按创建表时列的顺序插入所有列的值:
|
INSERT INTO stu VALUES(‘s_1002‘, ‘liSi‘, 32, ‘female‘); |
注意:所有字符串数据必须使用单引用!
语法:
UPDATE 表名 SET 列名1=值1, … 列名n=值n [WHERE 条件]
|
UPDATE stu SET sname=’zhangSanSan’, age=’32’, gender=’female’ WHERE sid=’s_1001’; |
|
UPDATE stu SET sname=’liSi’, age=’20’ WHERE age>50 AND gender=’male’; |
|
UPDATE stu SET sname=’wangWu’, age=’30’ WHERE age>60 OR gender=’female’; |
|
UPDATE stu SET gender=’female’ WHERE gender IS NULL UPDATE stu SET age=age+1 WHERE sname=’zhaoLiu’; |
语法:
DELETE FROM 表名 [WHERE 条件]
|
DELETE FROM stu WHERE sid=’s_1001’003B |
|
DELETE FROM stu WHERE sname=’chenQi’ OR age > 30; |
|
DELETE FROM stu; |
语法:
TRUNCATE TABLE 表名
|
TRUNCATE TABLE stu; |
虽然TRUNCATE和DELETE都可以删除表的所有记录,但有原理不同。DELETE的效率没有TRUNCATE高!
TRUNCATE其实属性DDL语句,因为它是先DROP TABLE,再CREATE TABLE。而且TRUNCATE删除的记录是无法回滚的,但DELETE删除的记录是可以回滚的(回滚是事务的知识!)。
语法:
CREATE USER 用户名@地址 IDENTIFIED BY ‘密码‘;
|
CREATE USER user1@localhost IDENTIFIED BY ‘123’; |
|
CREATE USER user2@’%’ IDENTIFIED BY ‘123’; |
语法:
GRANT 权限1, … , 权限n ON 数据库.* TO 用户名
|
GRANT CREATE,ALTER,DROP,INSERT,UPDATE,DELETE,SELECT ON mydb1.* TO user1@localhost; |
|
GRANT ALL ON mydb1.* TO user2@localhost; |
语法:
REVOKE权限1, … , 权限n ON 数据库.* FORM 用户名
|
REVOKE CREATE,ALTER,DROP ON mydb1.* FROM user1@localhost; |
语法:
SHOW GRANTS FOR 用户名
|
SHOW GRANTS FOR user1@localhost; |
语法:
DROP USER 用户名
|
DROP USER user1@localhost; |
语法:
USE mysql;
UPDATE USER SET PASSWORD=PASSWORD(‘密码’) WHERE User=’用户名’ and Host=’IP’;
FLUSH PRIVILEGES;
|
UPDATE USER SET PASSWORD=PASSWORD(‘1234‘) WHERE User=‘user2‘ and Host=’localhost’; FLUSH PRIVILEGES; |
DQL就是数据查询语言,数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。
语法:
SELECT selection_list /*要查询的列名称*/
FROM table_list /*要查询的表名称*/
WHERE condition /*行条件*/
GROUP BY grouping_columns /*对结果分组*/
HAVING condition /*分组后的行条件*/
ORDER BY sorting_columns /*对结果分组*/
LIMIT offset_start, row_count /*结果限定*/
创建名:
l 学生表:stu
|
字段名称 |
字段类型 |
说明 |
|
sid |
char(6) |
学生学号 |
|
sname |
varchar(50) |
学生姓名 |
|
age |
int |
学生年龄 |
|
gender |
varchar(50) |
学生性别 |
|
CREATE TABLE stu ( sid CHAR(6), sname VARCHAR(50), age INT, gender VARCHAR(50) ); |
|
INSERT INTO stu VALUES(‘S_1001‘, ‘liuYi‘, 35, ‘male‘); INSERT INTO stu VALUES(‘S_1002‘, ‘chenEr‘, 15, ‘female‘); INSERT INTO stu VALUES(‘S_1003‘, ‘zhangSan‘, 95, ‘male‘); INSERT INTO stu VALUES(‘S_1004‘, ‘liSi‘, 65, ‘female‘); INSERT INTO stu VALUES(‘S_1005‘, ‘wangWu‘, 55, ‘male‘); INSERT INTO stu VALUES(‘S_1006‘, ‘zhaoLiu‘, 75, ‘female‘); INSERT INTO stu VALUES(‘S_1007‘, ‘sunQi‘, 25, ‘male‘); INSERT INTO stu VALUES(‘S_1008‘, ‘zhouBa‘, 45, ‘female‘); INSERT INTO stu VALUES(‘S_1009‘, ‘wuJiu‘, 85, ‘male‘); INSERT INTO stu VALUES(‘S_1010‘, ‘zhengShi‘, 5, ‘female‘); INSERT INTO stu VALUES(‘S_1011‘, ‘xxx‘, NULL, NULL); |
l 雇员表:emp
|
字段名称 |
字段类型 |
说明 |
|
empno |
int |
员工编号 |
|
ename |
varchar(50) |
员工姓名 |
|
job |
varchar(50) |
员工工作 |
|
mgr |
int |
领导编号 |
|
hiredate |
date |
入职日期 |
|
sal |
decimal(7,2) |
月薪 |
|
comm |
decimal(7,2) |
奖金 |
|
deptno |
int |
部分编号 |
|
CREATE TABLE emp( empno INT, ename VARCHAR(50), job VARCHAR(50), mgr INT, hiredate DATE, sal DECIMAL(7,2), comm decimal(7,2), deptno INT ) ; |
|
INSERT INTO emp values(7369,‘SMITH‘,‘CLERK‘,7902,‘1980-12-17‘,800,NULL,20); INSERT INTO emp values(7499,‘ALLEN‘,‘SALESMAN‘,7698,‘1981-02-20‘,1600,300,30); INSERT INTO emp values(7521,‘WARD‘,‘SALESMAN‘,7698,‘1981-02-22‘,1250,500,30); INSERT INTO emp values(7566,‘JONES‘,‘MANAGER‘,7839,‘1981-04-02‘,2975,NULL,20); INSERT INTO emp values(7654,‘MARTIN‘,‘SALESMAN‘,7698,‘1981-09-28‘,1250,1400,30); INSERT INTO emp values(7698,‘BLAKE‘,‘MANAGER‘,7839,‘1981-05-01‘,2850,NULL,30); INSERT INTO emp values(7782,‘CLARK‘,‘MANAGER‘,7839,‘1981-06-09‘,2450,NULL,10); INSERT INTO emp values(7788,‘SCOTT‘,‘ANALYST‘,7566,‘1987-04-19‘,3000,NULL,20); INSERT INTO emp values(7839,‘KING‘,‘PRESIDENT‘,NULL,‘1981-11-17‘,5000,NULL,10); INSERT INTO emp values(7844,‘TURNER‘,‘SALESMAN‘,7698,‘1981-09-08‘,1500,0,30); INSERT INTO emp values(7876,‘ADAMS‘,‘CLERK‘,7788,‘1987-05-23‘,1100,NULL,20); INSERT INTO emp values(7900,‘JAMES‘,‘CLERK‘,7698,‘1981-12-03‘,950,NULL,30); INSERT INTO emp values(7902,‘FORD‘,‘ANALYST‘,7566,‘1981-12-03‘,3000,NULL,20); INSERT INTO emp values(7934,‘MILLER‘,‘CLERK‘,7782,‘1982-01-23‘,1300,NULL,10); |
l 部分表:dept
|
字段名称 |
字段类型 |
说明 |
|
deptno |
int |
部分编码 |
|
dname |
varchar(50) |
部分名称 |
|
loc |
varchar(50) |
部分所在地点 |
|
CREATE TABLE dept( deptno INT, dname varchar(14), loc varchar(13) ); |
|
INSERT INTO dept values(10, ‘ACCOUNTING‘, ‘NEW YORK‘); INSERT INTO dept values(20, ‘RESEARCH‘, ‘DALLAS‘); INSERT INTO dept values(30, ‘SALES‘, ‘CHICAGO‘); INSERT INTO dept values(40, ‘OPERATIONS‘, ‘BOSTON‘); |
SELECT * FROM stu;
SELECT sid, sname, age FROM stu;
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
l =、!=、<>、<、<=、>、>=;
l BETWEEN…AND;
l IN(set);
l IS NULL;
l AND;
l OR;
l NOT;
SELECT * FROM stu
WHERE gender=‘female‘ AND ge<50;
SELECT * FROM stu
WHERE sid =‘S_1001‘ OR sname=‘liSi‘;
SELECT * FROM stu
WHERE sid IN (‘S_1001‘,‘S_1002‘,‘S_1003‘);
SELECT * FROM tab_student
WHERE s_number NOT IN (‘S_1001‘,‘S_1002‘,‘S_1003‘);
SELECT * FROM stu
WHERE age IS NULL;
SELECT *
FROM stu
WHERE age>=20 AND age<=40;
或者
SELECT *
FROM stu
WHERE age BETWEEN 20 AND 40;
SELECT *
FROM stu
WHERE gender!=‘male‘;
或者
SELECT *
FROM stu
WHERE gender<>‘male‘;
或者
SELECT *
FROM stu
WHERE NOT gender=‘male‘;
SELECT *
FROM stu
WHERE NOT sname IS NULL;
或者
SELECT *
FROM stu
WHERE sname IS NOT NULL;
当想查询姓名中包含a字母的学生时就需要使用模糊查询了。模糊查询需要使用关键字LIKE。
SELECT *
FROM stu
WHERE sname LIKE ‘_____‘;
模糊查询必须使用LIKE关键字。其中 “_”匹配任意一个字母,5个“_”表示5个任意字母。
SELECT *
FROM stu
WHERE sname LIKE ‘____i‘;
SELECT *
FROM stu
WHERE sname LIKE ‘z%‘;
其中“%”匹配0~n个任何字母。
SELECT *
FROM stu
WHERE sname LIKE ‘_i%‘;
SELECT *
FROM stu
WHERE sname LIKE ‘%a%‘;
去除重复记录(两行或两行以上记录中系列的上的数据都相同),例如emp表中sal字段就存在相同的记录。当只查询emp表的sal字段时,那么会出现重复记录,那么想去除重复记录,需要使用DISTINCT:
SELECT DISTINCT sal FROM emp;
因为sal和comm两列的类型都是数值类型,所以可以做加运算。如果sal或comm中有一个字段不是数值类型,那么会出错。
SELECT *,sal+comm FROM emp;
comm列有很多记录的值为NULL,因为任何东西与NULL相加结果还是NULL,所以结算结果可能会出现NULL。下面使用了把NULL转换成数值0的函数IFNULL:
SELECT *,sal+IFNULL(comm,0) FROM emp;
在上面查询中出现列名为sal+IFNULL(comm,0),这很不美观,现在我们给这一列给出一个别名,为total:
SELECT *, sal+IFNULL(comm,0) AS total FROM emp;
给列起别名时,是可以省略AS关键字的:
SELECT *,sal+IFNULL(comm,0) total FROM emp;
SELECT *
FROM stu
ORDER BY sage ASC;
或者
SELECT *
FROM stu
ORDER BY sage;
SELECT *
FROM stu
ORDER BY age DESC;
SELECT * FROM emp
ORDER BY sal DESC,empno ASC;
聚合函数是用来做纵向运算的函数:
l COUNT():统计指定列不为NULL的记录行数;
l MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
l MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
l SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
l AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
当需要纵向统计时可以使用COUNT()。
l 查询emp表中记录数:
SELECT COUNT(*) AS cnt FROM emp;
l 查询emp表中有佣金的人数:
SELECT COUNT(comm) cnt FROM emp;
注意,因为count()函数中给出的是comm列,那么只统计comm列非NULL的行数。
l 查询emp表中月薪大于2500的人数:
SELECT COUNT(*) FROM emp
WHERE sal > 2500;
l 统计月薪与佣金之和大于2500元的人数:
SELECT COUNT(*) AS cnt FROM emp WHERE sal+IFNULL(comm,0) > 2500;
l 查询有佣金的人数,以及有领导的人数:
SELECT COUNT(comm), COUNT(mgr) FROM emp;
当需要纵向求和时使用sum()函数。
l 查询所有雇员月薪和:
SELECT SUM(sal) FROM emp;
l 查询所有雇员月薪和,以及所有雇员佣金和:
SELECT SUM(sal), SUM(comm) FROM emp;
l 查询所有雇员月薪+佣金和:
SELECT SUM(sal+IFNULL(comm,0)) FROM emp;
l 统计所有员工平均工资:
SELECT SUM(sal), COUNT(sal) FROM emp;
或者
SELECT AVG(sal) FROM emp;
l 查询最高工资和最低工资:
SELECT MAX(sal), MIN(sal) FROM emp;
当需要分组查询时需要使用GROUP BY子句,例如查询每个部门的工资和,这说明要使用部分来分组。
l 查询每个部门的部门编号和每个部门的工资和:
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno;
l 查询每个部门的部门编号以及每个部门的人数:
SELECT deptno,COUNT(*)
FROM emp
GROUP BY deptno;
l 查询每个部门的部门编号以及每个部门工资大于1500的人数:
SELECT deptno,COUNT(*)
FROM emp
WHERE sal>1500
GROUP BY deptno;
l 查询工资总和大于9000的部门编号以及工资和:
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno
HAVING SUM(sal) > 9000;
注意,WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
LIMIT用来限定查询结果的起始行,以及总行数。
SELECT * FROM emp LIMIT 0, 5;
注意,起始行从0开始,即第一行开始!
SELECT * FROM emp LIMIT 3, 10;
如果一页记录为10条,希望查看第3页记录应该怎么查呢?
l 第一页记录起始行为0,一共查询10行;
l 第二页记录起始行为10,一共查询10行;
l 第三页记录起始行为20,一共查询10行;
完整性约束是为了表的数据的正确性!如果数据不正确,那么一开始就不能添加到表中。
当某一列添加了主键约束后,那么这一列的数据就不能重复出现。这样每行记录中其主键列的值就是这一行的唯一标识。例如学生的学号可以用来做唯一标识,而学生的姓名是不能做唯一标识的,因为学习有可能同名。
主键列的值不能为NULL,也不能重复!
指定主键约束使用PRIMARY KEY关键字
l 创建表:定义列时指定主键:
CREATE TABLE stu(
sidCHAR(6) PRIMARY KEY,
snameVARCHAR(20),
ageINT,
genderVARCHAR(10)
);
l 创建表:定义列之后独立指定主键:
CREATE TABLE stu(
sidCHAR(6),
snameVARCHAR(20),
ageINT,
genderVARCHAR(10),
PRIMARY KEY(sid)
);
l 修改表时指定主键:
ALTER TABLE stu
ADD PRIMARY KEY(sid);
l 删除主键(只是删除主键约束,而不会删除主键列):
ALTER TABLE stu DROP PRIMARY KEY;
MySQL提供了主键自动增长的功能!这样用户就不用再为是否有主键是否重复而烦恼了。当主键设置为自动增长后,在没有给出主键值时,主键的值会自动生成,而且是最大主键值+1,也就不会出现重复主键的可能了。
l 创建表时设置主键自增长(主键必须是整型才可以自增长):
CREATE TABLE stu(
sid INT PRIMARY KEY AUTO_INCREMENT,
snameVARCHAR(20),
ageINT,
genderVARCHAR(10)
);
l 修改表时设置主键自增长:
ALTER TABLE stu CHANGE sid sid INT AUTO_INCREMENT;
l 修改表时删除主键自增长:
ALTER TABLE stu CHANGE sid sid INT;
指定非空约束的列不能没有值,也就是说在插入记录时,对添加了非空约束的列一定要给值;在修改记录时,不能把非空列的值设置为NULL。
l 指定非空约束:
CREATE TABLE stu(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(10) NOT NULL,
ageINT,
genderVARCHAR(10)
);
当为sname字段指定为非空后,在向stu表中插入记录时,必须给sname字段指定值,否则会报错:
INSERT INTO stu(sid) VALUES(1);
插入的记录中sname没有指定值,所以会报错!
还可以为字段指定唯一约束!当为字段指定唯一约束后,那么字段的值必须是唯一的。这一点与主键相似!例如给stu表的sname字段指定唯一约束:
CREATE TABLE tab_ab(
sid INT PRIMARY KEY AUTO_INCREMENT,
sname VARCHAR(10) UNIQUE
);
INSERT INTO sname(sid, sname) VALUES(1001, ‘zs‘);
INSERT INTO sname(sid, sname) VALUES(1002, ‘zs‘);
当两次插入相同的名字时,MySQL会报错!
主外键是构成表与表关联的唯一途径!
外键是另一张表的主键!例如员工表与部门表之间就存在关联关系,其中员工表中的部门编号字段就是外键,是相对部门表的外键。
我们再来看BBS系统中:用户表(t_user)、分类表(t_section)、帖子表(t_topic)三者之间的关系。

例如在t_section表中sid为1的记录说明有一个分类叫java,版主是t_user表中uid为1的用户,即zs!
例如在t_topic表中tid为2的记录是名字为“Java是咖啡”的帖子,它是java版块的帖子,它的作者是ww。
外键就是用来约束这一列的值必须是另一张表的主键值!!!
l 创建t_user表,指定uid为主键列:
CREATE TABLE t_user(
uidINT PRIMARY KEY AUTO_INCREMENT,
unameVARCHAR(20) UNIQUE NOT NULL
);
l 创建t_section表,指定sid为主键列,u_id为相对t_user表的uid列的外键:
CREATE TABLE t_section(
sidINT PRIMARY KEY AUTO_INCREMENT,
snameVARCHAR(30),
u_idINT,
CONSTRAINT fk_t_user FOREIGN KEY(u_id) REFERENCES t_user(uid)
);
l 修改t_section表,指定u_id为相对t_user表的uid列的外键:
ALTER TABLE t_section
ADD CONSTRAINT fk_t_user
FOREIGN KEY(u_id)
REFERENCES t_user(uid);
l 修改t_section表,删除u_id的外键约束:
ALTER TABLE t_section
DROP FOREIGN KEY fk_t_user;
l 一对一:例如t_person表和t_card表,即人和身份证。这种情况需要找出主从关系,即谁是主表,谁是从表。人可以没有身份证,但身份证必须要有人才行,所以人是主表,而身份证是从表。设计从表可以有两种方案:
Ø 在t_card表中添加外键列(相对t_user表),并且给外键添加唯一约束;
Ø 给t_card表的主键添加外键约束(相对t_user表),即t_card表的主键也是外键。
l 一对多(多对一):最为常见的就是一对多!一对多和多对一,这是从哪个角度去看得出来的。t_user和t_section的关系,从t_user来看就是一对多,而从t_section的角度来看就是多对一!这种情况都是在多方创建外键!
l 多对多:例如t_stu和t_teacher表,即一个学生可以有多个老师,而一个老师也可以有多个学生。这种情况通常需要创建中间表来处理多对多关系。例如再创建一张表t_stu_tea表,给出两个外键,一个相对t_stu表的外键,另一个相对t_teacher表的外键。
SHOW VARIABLES LIKE ‘char%‘;

因为当初安装时指定了字符集为UTF8,所以所有的编码都是UTF8。
l character_set_client:你发送的数据必须与client指定的编码一致!!!服务器会使用该编码来解读客户端发送过来的数据;
l character_set_connection:通过该编码与client一致!该编码不会导致乱码!当执行的是查询语句时,客户端发送过来的数据会先转换成connection指定的编码。但只要客户端发送过来的数据与client指定的编码一致,那么转换就不会出现问题;
l character_set_database:数据库默认编码,在创建数据库时,如果没有指定编码,那么默认使用database编码;
l character_set_server:MySQL服务器默认编码;
l character_set_results:响应的编码,即查询结果返回给客户端的编码。这说明客户端必须使用result指定的编码来解码;
修改character_set_client、character_set_results、character_set_connection为GBK,就不会出现乱码了。但其实只需要修改character_set_client和character_set_results。
控制台的编码只能是GBK,而不能修改为UTF8,这就出现一个问题。客户端发送的数据是GBK,而character_set_client为UTF8,这就说明客户端数据到了服务器端后一定会出现乱码。既然不能修改控制台的编码,那么只能修改character_set_client为GBK了。
服务器发送给客户端的数据编码为character_set_result,它如果是UTF8,那么控制台使用GBK解码也一定会出现乱码。因为无法修改控制台编码,所以只能把character_set_result修改为GBK。
l 修改character_set_client变量:set character_set_client=gbk;
l 修改character_set_results变量:set character_set_results=gbk;
设置编码只对当前连接有效,这说明每次登录MySQL提示符后都要去修改这两个编码,但可以通过修改配置文件来处理这一问题:配置文件路径:D:\Program Files\MySQL\MySQL Server 5.1\ my.ini

使用MySQL工具是不会出现乱码的,因为它们会每次连接时都修改character_set_client、character_set_results、character_set_connection的编码。这样对my.ini上的配置覆盖了,也就不会出现乱码了。
在控制台使用mysqldump命令可以用来生成指定数据库的脚本文本,但要注意,脚本文本中只包含数据库的内容,而不会存在创建数据库的语句!所以在恢复数据时,还需要自已手动创建一个数据库之后再去恢复数据。
|
mysqldump –u用户名 –p密码 数据库名>生成的脚本文件路径 |
![]()
现在可以在C盘下找到mydb1.sql文件了!
注意,mysqldump命令是在Windows控制台下执行,无需登录mysql!!!
执行SQL脚本需要登录mysql,然后进入指定数据库,才可以执行SQL脚本!!!
执行SQL脚本不只是用来恢复数据库,也可以在平时编写SQL脚本,然后使用执行SQL 脚本来操作数据库!大家都知道,在黑屏下编写SQL语句时,就算发现了错误,可能也不能修改了。所以我建议大家使用脚本文件来编写SQL代码,然后执行之!
|
SOURCE C:\mydb1.sql |
![]()
注意,在执行脚本时需要先行核查当前数据库中的表是否与脚本文件中的语句有冲突!例如在脚本文件中存在create table a的语句,而当前数据库中已经存在了a表,那么就会出错!
还可以通过下面的方式来执行脚本文件:
mysql -uroot -p123 mydb1<c:\mydb1.sql
|
mysql –u用户名 –p密码 数据库<要执行脚本文件路径 |
![]()
这种方式无需登录mysql!
多表查询有如下几种:
l 合并结果集;
l 连接查询
Ø 内连接
Ø 外连接
² 左外连接
² 右外连接
² 全外连接(MySQL不支持)
Ø 自然连接
l 子查询
1. 作用:合并结果集就是把两个select语句的查询结果合并到一起!
2. 合并结果集有两种方式:
l UNION:去除重复记录,例如:SELECT * FROM t1 UNION SELECT * FROM t2;
l UNION ALL:不去除重复记录,例如:SELECT * FROM t1 UNION ALL SELECT * FROM t2。


3. 要求:被合并的两个结果:列数、列类型必须相同。
连接查询就是求出多个表的乘积,例如t1连接t2,那么查询出的结果就是t1*t2。

连接查询会产生笛卡尔积,假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}。可以扩展到多个集合的情况。
那么多表查询产生这样的结果并不是我们想要的,那么怎么去除重复的,不想要的记录呢,当然是通过条件过滤。通常要查询的多个表之间都存在关联关系,那么就通过关联关系去除笛卡尔积。
你能想像到emp和dept表连接查询的结果么?emp一共14行记录,dept表一共4行记录,那么连接后查询出的结果是56行记录。
也就你只是想在查询emp表的同时,把每个员工的所在部门信息显示出来,那么就需要使用主外键来去除无用信息了。

使用主外键关系做为条件来去除无用信息
|
SELECT * FROM emp,dept WHERE emp.deptno=dept.deptno; |

上面查询结果会把两张表的所有列都查询出来,也许你不需要那么多列,这时就可以指定要查询的列了。
|
SELECT emp.ename,emp.sal,emp.comm,dept.dname FROM emp,dept WHERE emp.deptno=dept.deptno; |

还可以为表指定别名,然后在引用列时使用别名即可。
|
SELECT e.ename,e.sal,e.comm,d.dname FROM emp AS e,dept AS d WHERE e.deptno=d.deptno; |
上面的连接语句就是内连接,但它不是SQL标准中的查询方式,可以理解为方言!SQL标准的内连接为:
|
SELECT * FROM emp e INNER JOIN dept d ON e.deptno=d.deptno; |
内连接的特点:查询结果必须满足条件。例如我们向emp表中插入一条记录:
![]()
其中deptno为50,而在dept表中只有10、20、30、40部门,那么上面的查询结果中就不会出现“张三”这条记录,因为它不能满足e.deptno=d.deptno这个条件。
2.2 外连接(左连接、右连接)
外连接的特点:查询出的结果存在不满足条件的可能。
左连接:
|
SELECT * FROM emp e LEFT OUTER JOIN dept d ON e.deptno=d.deptno; |
左连接是先查询出左表(即以左表为主),然后查询右表,右表中满足条件的显示出来,不满足条件的显示NULL。
这么说你可能不太明白,我们还是用上面的例子来说明。其中emp表中“张三”这条记录中,部门编号为50,而dept表中不存在部门编号为50的记录,所以“张三”这条记录,不能满足e.deptno=d.deptno这条件。但在左连接中,因为emp表是左表,所以左表中的记录都会查询出来,即“张三”这条记录也会查出,但相应的右表部分显示NULL。

右连接就是先把右表中所有记录都查询出来,然后左表满足条件的显示,不满足显示NULL。例如在dept表中的40部门并不存在员工,但在右连接中,如果dept表为右表,那么还是会查出40部门,但相应的员工信息为NULL。
|
SELECT * FROM emp e RIGHT OUTER JOIN dept d ON e.deptno=d.deptno; |

连接查询心得:
连接不限与两张表,连接查询也可以是三张、四张,甚至N张表的连接查询。通常连接查询不可能需要整个笛卡尔积,而只是需要其中一部分,那么这时就需要使用条件来去除不需要的记录。这个条件大多数情况下都是使用主外键关系去除。
两张表的连接查询一定有一个主外键关系,三张表的连接查询就一定有两个主外键关系,所以在大家不是很熟悉连接查询时,首先要学会去除无用笛卡尔积,那么就是用主外键关系作为条件来处理。如果两张表的查询,那么至少有一个主外键条件,三张表连接至少有两个主外键条件。
大家也都知道,连接查询会产生无用笛卡尔积,我们通常使用主外键关系等式来去除它。而自然连接无需你去给出主外键等式,它会自动找到这一等式:
l 两张连接的表中名称和类型完成一致的列作为条件,例如emp和dept表都存在deptno列,并且类型一致,所以会被自然连接找到!
当然自然连接还有其他的查找条件的方式,但其他方式都可能存在问题!
|
SELECT * FROM emp NATURAL JOIN dept; SELECT * FROM emp NATURAL LEFT JOIN dept; SELECT * FROM emp NATURAL RIGHT JOIN dept; |
子查询就是嵌套查询,即SELECT中包含SELECT,如果一条语句中存在两个,或两个以上SELECT,那么就是子查询语句了。
l 子查询出现的位置:
Ø where后,作为条件的一部分;
Ø from后,作为被查询的一条表;
l 当子查询出现在where后作为条件时,还可以使用如下关键字:
Ø any
Ø all
l 子查询结果集的形式:
Ø 单行单列(用于条件)
Ø 单行多列(用于条件)
Ø 多行单列(用于条件)
Ø 多行多列(用于表)
练习:
1. 工资高于甘宁的员工。
分析:
查询条件:工资>甘宁工资,其中甘宁工资需要一条子查询。
第一步:查询甘宁的工资
|
SELECT sal FROM emp WHERE ename=‘甘宁‘ |
第二步:查询高于甘宁工资的员工
|
SELECT * FROM emp WHERE sal > (${第一步}) |
结果:
|
SELECT * FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename=‘甘宁‘) |
l 子查询作为条件
l 子查询形式为单行单列
2. 工资高于30部门所有人的员工信息
分析:
查询条件:工资高于30部门所有人工资,其中30部门所有人工资是子查询。高于所有需要使用all关键字。
第一步:查询30部门所有人工资
|
SELECT sal FROM emp WHERE deptno=30; |
第二步:查询高于30部门所有人工资的员工信息
|
SELECT * FROM emp WHERE sal > ALL (${第一步}) |
结果:
|
SELECT * FROM emp WHERE sal > ALL (SELECT sal FROM emp WHERE deptno=30) |
l 子查询作为条件
l 子查询形式为多行单列(当子查询结果集形式为多行单列时可以使用ALL或ANY关键字)
3. 查询工作和工资与殷天正完全相同的员工信息
分析:
查询条件:工作和工资与殷天正完全相同,这是子查询
第一步:查询出殷天正的工作和工资
|
SELECT job,sal FROM emp WHERE ename=‘殷天正‘ |
第二步:查询出与殷天正工作和工资相同的人
|
SELECT * FROM emp WHERE (job,sal) IN (${第一步}) |
结果:
|
SELECT * FROM emp WHERE (job,sal) IN (SELECT job,sal FROM emp WHERE ename=‘殷天正‘) |
l 子查询作为条件
l 子查询形式为单行多列
4. 查询员工编号为1006的员工名称、员工工资、部门名称、部门地址
分析:
查询列:员工名称、员工工资、部门名称、部门地址
查询表:emp和dept,分析得出,不需要外连接(外连接的特性:某一行(或某些行)记录上会出现一半有值,一半为NULL值)
条件:员工编号为1006
第一步:去除多表,只查一张表,这里去除部门表,只查员工表
|
SELECT ename, sal FROM emp e WHERE empno=1006 |
第二步:让第一步与dept做内连接查询,添加主外键条件去除无用笛卡尔积
|
SELECT e.ename, e.sal, d.dname, d.loc FROM emp e, dept d WHERE e.deptno=d.deptno AND empno=1006 |
第二步中的dept表表示所有行所有列的一张完整的表,这里可以把dept替换成所有行,但只有dname和loc列的表,这需要子查询。
第三步:查询dept表中dname和loc两列,因为deptno会被作为条件,用来去除无用笛卡尔积,所以需要查询它。
|
SELECT dname,loc,deptno FROM dept; |
第四步:替换第二步中的dept
|
SELECT e.ename, e.sal, d.dname, d.loc FROM emp e, (SELECT dname,loc,deptno FROM dept) d WHERE e.deptno=d.deptno AND e.empno=1006 |
l 子查询作为表
l 子查询形式为多行多列
JDBC(Java DataBase Connectivity)就是Java数据库连接,说白了就是用Java语言来操作数据库。原来我们操作数据库是在控制台使用SQL语句来操作数据库,JDBC是用Java语言向数据库发送SQL语句。
早期SUN公司的天才们想编写一套可以连接天下所有数据库的API,但是当他们刚刚开始时就发现这是不可完成的任务,因为各个厂商的数据库服务器差异太大了。后来SUN开始与数据库厂商们讨论,最终得出的结论是,由SUN提供一套访问数据库的规范(就是一组接口),并提供连接数据库的协议标准,然后各个数据库厂商会遵循SUN的规范提供一套访问自己公司的数据库服务器的API出现。SUN提供的规范命名为JDBC,而各个厂商提供的,遵循了JDBC规范的,可以访问自己数据库的API被称之为驱动!

JDBC是接口,而JDBC驱动才是接口的实现,没有驱动无法完成数据库连接!每个数据库厂商都有自己的驱动,用来连接自己公司的数据库。
当然还有第三方公司专门为某一数据库提供驱动,这样的驱动往往不是开源免费的!
JDBC中的核心类有:DriverManager、Connection、Statement,和ResultSet!
DriverManger(驱动管理器)的作用有两个:
l 注册驱动:这可以让JDBC知道要使用的是哪个驱动;
l 获取Connection:如果可以获取到Connection,那么说明已经与数据库连接上了。
Connection对象表示连接,与数据库的通讯都是通过这个对象展开的:
l Connection最为重要的一个方法就是用来获取Statement对象;
Statement是用来向数据库发送SQL语句的,这样数据库就会执行发送过来的SQL语句:
l void executeUpdate(String sql):执行更新操作(insert、update、delete等);
l ResultSet executeQuery(String sql):执行查询操作,数据库在执行查询后会把查询结果,查询结果就是ResultSet;
ResultSet对象表示查询结果集,只有在执行查询操作后才会有结果集的产生。结果集是一个二维的表格,有行有列。操作结果集要学习移动ResultSet内部的“行光标”,以及获取当前行上的每一列上的数据:
l boolean next():使“行光标”(游标)移动到下一行,并返回移动后的行是否存在;
l XXX getXXX(int col):获取当前行指定列上的值,参数就是列数,列数从1开始,而不是0。
下面开始编写第一个JDBC程序
获取连接需要两步,一是使用DriverManager来注册驱动,二是使用DriverManager来获取Connection对象。
1. 注册驱动
看清楚了,注册驱动就只有一句话:Class.forName(“com.mysql.jdbc.Driver”),下面的内容都是对这句代码的解释。今后我们的代码中,与注册驱动相关的代码只有这一句。
DriverManager类的registerDriver()方法的参数是java.sql.Driver,但java.sql.Driver是一个接口,实现类由mysql驱动来提供,mysql驱动中的java.sql.Driver接口的实现类为com.mysql.jdbc.Driver!那么注册驱动的代码如下:
DriverManager.registerDriver(new com.mysql.jdbc.Driver());
上面代码虽然可以注册驱动,但是出现硬编码(代码依赖mysql驱动jar包),如果将来想连接Oracle数据库,那么必须要修改代码的。并且其实这种注册驱动的方式是注册了两次驱动!
JDBC中规定,驱动类在被加载时,需要自己“主动”把自己注册到DriverManger中,下面我们来看看com.mysql.jdbc.Driver类的源代码:
com.mysql.jdbc.Driver.java
|
public class Driver extends NonRegisteringDriver implements java.sql.Driver { static { try { java.sql.DriverManager.registerDriver(new Driver()); } catch (SQLException E) { throw new RuntimeException("Can‘t register driver!"); } } …… } |
com.mysql.jdbc.Driver类中的static块会创建本类对象,并注册到DriverManager中。这说明只要去加载com.mysql.jdbc.Driver类,那么就会执行这个static块,从而也就会把com.mysql.jdbc.Driver注册到DriverManager中,所以可以把注册驱动类的代码修改为加载驱动类。
Class.forName(“com.mysql.jdbc.Driver”);
2. 获取连接
获取连接的也只有一句代码:DriverManager.getConnection(url,username,password),其中username和password是登录数据库的用户名和密码,如果我没说错的话,你的mysql数据库的用户名和密码分别是:root、123。
url查对复杂一点,它是用来找到要连接数据库“网址”,就好比你要浏览器中查找百度时,也需要提供一个url。下面是mysql的url:
jdbc:mysql://localhost:3306/mydb1
JDBC规定url的格式由三部分组成,每个部分中间使用逗号分隔。
l 第一部分是jdbc,这是固定的;
l 第二部分是数据库名称,那么连接mysql数据库,第二部分当然是mysql了;
l 第三部分是由数据库厂商规定的,我们需要了解每个数据库厂商的要求,mysql的第三部分分别由数据库服务器的IP地址(localhost)、端口号(3306),以及DATABASE名称(mydb1)组成。
下面是获取连接的语句:
Connection con = DriverManager.getConnection(“jdbc:mysql://localhost:3306/mydb1”,”root”,”123”);
还可以在url中提供参数:
jdbc:mysql://localhost:3306/mydb1?useUnicode=true&characterEncoding=UTF8
useUnicode参数指定这个连接数据库的过程中,使用的字节集是Unicode字节集;
characherEncoding参数指定穿上连接数据库的过程中,使用的字节集编码为UTF-8编码。请注意,mysql中指定UTF-8编码是给出的是UTF8,而不是UTF-8。要小心了!
在得到Connectoin之后,说明已经与数据库连接上了,下面是通过Connection获取Statement对象的代码:
Statement stmt = con.createStatement();
Statement是用来向数据库发送要执行的SQL语句的!
String sql = “insert into user value(’zhangSan’, ’123’)”;
int m = stmt.executeUpdate(sql);
其中int类型的返回值表示执行这条SQL语句所影响的行数,我们知道,对insert来说,最后只能影响一行,而update和delete可能会影响0~n行。
如果SQL语句执行失败,那么executeUpdate()会抛出一个SQLException。
String sql = “select * from user”;
ResultSet rs = stmt.executeQuery(sql);
请注册,执行查询使用的不是executeUpdate()方法,而是executeQuery()方法。executeQuery()方法返回的是ResultSet,ResultSet封装了查询结果,我们称之为结果集。
ResultSet就是一张二维的表格,它内部有一个“行光标”,光标默认的位置在“第一行上方”,我们可以调用rs对象的next()方法把“行光标”向下移动一行,当第一次调用next()方法时,“行光标”就到了第一行记录的位置,这时就可以使用ResultSet提供的getXXX(int col)方法来获取指定列的数据了:
rs.next();//光标移动到第一行
rs.getInt(1);//获取第一行第一列的数据
当你使用rs.getInt(1)方法时,你必须可以肯定第1列的数据类型就是int类型,如果你不能肯定,那么最好使用rs.getObject(1)。在ResultSet类中提供了一系列的getXXX()方法,比较常用的方法有:
Object getObject(int col)
String getString(int col)
int getInt(int col)
double getDouble(int col)
与IO流一样,使用后的东西都需要关闭!关闭的顺序是先得到的后关闭,后得到的先关闭。
rs.close();
stmt.close();
con.close();
|
public static Connection getConnection() throws Exception { Class.forName("com.mysql.jdbc.Driver"); String url = "jdbc:mysql://localhost:3306/mydb1"; return DriverManager.getConnection(url, "root", "123"); } |
|
@Test public void insert() throws Exception { Connection con = getConnection(); Statement stmt = con.createStatement(); String sql = "insert into user values(‘zhangSan‘, ‘123‘)"; stmt.executeUpdate(sql); System.out.println("插入成功!"); } |
|
@Test public void update() throws Exception { Connection con = getConnection(); Statement stmt = con.createStatement(); String sql = "update user set password=‘456‘ where username=‘zhangSan‘"; stmt.executeUpdate(sql); System.out.println("修改成功!"); } |
|
@Test public void delete() throws Exception { Connection con = getConnection(); Statement stmt = con.createStatement(); String sql = "delete from user where username=‘zhangSan‘"; stmt.executeUpdate(sql); System.out.println("删除成功!"); } |
|
@Test public void query() throws Exception { Connection con = getConnection(); Statement stmt = con.createStatement(); String sql = "select * from user"; ResultSet rs = stmt.executeQuery(sql); while(rs.next()) { String username = rs.getString(1); String password = rs.getString(2); System.out.println(username + ", " + password); } } |
所谓规范化代码就是无论是否出现异常,都要关闭ResultSet、Statement,以及Connection,如果你还记得IO流的规范化代码,那么下面的代码你就明白什么意思了。
|
@Test public void query() { Connection con = null; Statement stmt = null; ResultSet rs = null; try { con = getConnection(); stmt = con.createStatement(); String sql = "select * from user"; rs = stmt.executeQuery(sql); while(rs.next()) { String username = rs.getString(1); String password = rs.getString(2); System.out.println(username + ", " + password); } } catch(Exception e) { throw new RuntimeException(e); } finally { try { if(rs != null) rs.close(); if(stmt != null) stmt.close(); if(con != null) con.close(); } catch(SQLException e) {} } } |
在JDBC中常用的类有:
l DriverManager;
l Connection;
l Statement;
l ResultSet。
其实我们今后只需要会用DriverManager的getConnection()方法即可:
1. Class.forName(“com.mysql.jdbc.Driver”);//注册驱动
2. String url = “jdbc:mysql://localhost:3306/mydb1”;
3. String username = “root”;
4. String password = “123”;
5. Connection con = DriverManager.getConnection(url, username, password);
注意,上面代码可能出现的两种异常:
1. ClassNotFoundException:这个异常是在第1句上出现的,出现这个异常有两个可能:
l 你没有给出mysql的jar包;
l 你把类名称打错了,查看类名是不是com.mysql.jdbc.Driver。
2. SQLException:这个异常出现在第5句,出现这个异常就是三个参数的问题,往往username和password一般不是出错,所以需要认真查看url是否打错。
对于DriverManager.registerDriver()方法了解即可,因为我们今后注册驱动只会Class.forName(),而不会使用这个方法。
Connection最为重要的方法就是获取Statement:
l Statement stmt = con.createStatement();
后面在学习ResultSet方法时,还要学习一下下面的方法:
l Statement stmt = con.createStatement(int,int);
Statement最为重要的方法是:
l int executeUpdate(String sql):执行更新操作,即执行insert、update、delete语句,其实这个方法也可以执行create table、alter table,以及drop table等语句,但我们很少会使用JDBC来执行这些语句;
l ResultSet executeQuery(String sql):执行查询操作,执行查询操作会返回ResultSet,即结果集。
boolean execute()
Statement还有一个boolean execute()方法,这个方法可以用来执行增、删、改、查所有SQL语句。该方法返回的是boolean类型,表示SQL语句是否执行成功。
如果使用execute()方法执行的是更新语句,那么还要调用int getUpdateCount()来获取insert、update、delete语句所影响的行数。
如果使用execute()方法执行的是查询语句,那么还要调用ResultSet getResultSet()来获取select语句的查询结果。
ResultSet表示结果集,它是一个二维的表格!ResultSet内部维护一个行光标(游标),ResultSet提供了一系列的方法来移动游标:
l void beforeFirst():把光标放到第一行的前面,这也是光标默认的位置;
l void afterLast():把光标放到最后一行的后面;
l boolean first():把光标放到第一行的位置上,返回值表示调控光标是否成功;
l boolean last():把光标放到最后一行的位置上;
l boolean isBeforeFirst():当前光标位置是否在第一行前面;
l boolean isAfterLast():当前光标位置是否在最后一行的后面;
l boolean isFirst():当前光标位置是否在第一行上;
l boolean isLast():当前光标位置是否在最后一行上;
l boolean previous():把光标向上挪一行;
l boolean next():把光标向下挪一行;
l boolean relative(int row):相对位移,当row为正数时,表示向下移动row行,为负数时表示向上移动row行;
l boolean absolute(int row):绝对位移,把光标移动到指定的行上;
l int getRow():返回当前光标所有行。
上面方法分为两类,一类用来判断游标位置的,另一类是用来移动游标的。如果结果集是不可滚动的,那么只能使用next()方法来移动游标,而beforeFirst()、afterLast()、first()、last()、previous()、relative()方法都不能使用!!!
结果集是否支持滚动,要从Connection类的createStatement()方法说起。也就是说创建的Statement决定了使用Statement创建的ResultSet是否支持滚动。
Statement createStatement(int resultSetType, int resultSetConcurrency)
resultSetType的可选值:
l ResultSet.TYPE_FORWARD_ONLY:不滚动结果集;
l ResultSet.TYPE_SCROLL_INSENSITIVE:滚动结果集,但结果集数据不会再跟随数据库而变化;
l ResultSet.TYPE_SCROLL_SENSITIVE:滚动结果集,但结果集数据不会再跟随数据库而变化;
可以看出,如果想使用滚动的结果集,我们应该选择TYPE_SCROLL_INSENSITIVE!其实很少有数据库驱动会支持TYPE_SCROLL_SENSITIVE的特性!通常我们也不需要查询到的结果集再受到数据库变化的影响。
resultSetConcurrency的可选值:
l CONCUR_READ_ONLY:结果集是只读的,不能通过修改结果集而反向影响数据库;
l CONCUR_UPDATABLE:结果集是可更新的,对结果集的更新可以反向影响数据库。
通常可更新结果集这一“高级特性”我们也是不需要的!
获取滚动结果集的代码如下:
Connection con = …
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, CONCUR_READ_ONLY);
String sql = …//查询语句
ResultSet rs = stmt.executeQuery(sql);//这个结果集是可滚动的
可以通过next()方法使ResultSet的游标向下移动,当游标移动到你需要的行时,就需要来获取该行的数据了,ResultSet提供了一系列的获取列数据的方法:
l String getString(int columnIndex):获取指定列的String类型数据;
l int getInt(int columnIndex):获取指定列的int类型数据;
l double getDouble(int columnIndex):获取指定列的double类型数据;
l boolean getBoolean(int columnIndex):获取指定列的boolean类型数据;
l Object getObject(int columnIndex):获取指定列的Object类型的数据。
上面方法中,参数columnIndex表示列的索引,列索引从1开始,而不是0,这第一点与数组不同。如果你清楚当前列的数据类型,那么可以使用getInt()之类的方法来获取,如果你不清楚列的类型,那么你应该使用getObject()方法来获取。
ResultSet还提供了一套通过列名称来获取列数据的方法:
l String getString(String columnName):获取名称为columnName的列的String数据;
l int getInt(String columnName):获取名称为columnName的列的int数据;
l double getDouble(String columnName):获取名称为columnName的列的double数据;
l boolean getBoolean(String columnName):获取名称为columnName的列的boolean数据;
l Object getObject(String columnName):获取名称为columnName的列的Object数据;
在需要用户输入的地方,用户输入的是SQL语句的片段,最终用户输入的SQL片段与我们DAO中写的SQL语句合成一个完整的SQL语句!例如用户在登录时输入的用户名和密码都是为SQL语句的片段!
首先我们需要创建一张用户表,用来存储用户的信息。
|
CREATE TABLE user( uidCHAR(32) PRIMARY KEY, usernameVARCHAR(30) UNIQUE KEY NOT NULL, PASSWORD VARCHAR(30) );
INSERT INTO user VALUES(‘U_1001‘, ‘zs‘, ‘zs‘); SELECT * FROM user; |
现在用户表中只有一行记录,就是zs。
下面我们写一个login()方法!
|
public void login(String username, String password) { Connection con = null; Statement stmt = null; ResultSet rs = null; try { con = JdbcUtils.getConnection(); stmt = con.createStatement(); String sql = "SELECT * FROM user WHERE " + "username=‘" + username + "‘ and password=‘" + password + "‘"; rs = stmt.executeQuery(sql); if(rs.next()) { System.out.println("欢迎" + rs.getString("username")); } else { System.out.println("用户名或密码错误!"); } } catch (Exception e) { throw new RuntimeException(e); } finally { JdbcUtils.close(con, stmt, rs); } } |
下面是调用这个方法的代码:
|
login("a‘ or ‘a‘=‘a", "a‘ or ‘a‘=‘a"); |
这行当前会使我们登录成功!因为是输入的用户名和密码是SQL语句片段,最终与我们的login()方法中的SQL语句组合在一起!我们来看看组合在一起的SQL语句:
|
SELECT * FROM tab_user WHERE username=‘a‘ or ‘a‘=‘a‘ and password=‘a‘ or ‘a‘=‘a‘ |
l 过滤用户输入的数据中是否包含非法字符;
l 分步交验!先使用用户名来查询用户,如果查找到了,再比较密码;
l 使用PreparedStatement。
PreparedStatement叫预编译声明!
PreparedStatement是Statement的子接口,你可以使用PreparedStatement来替换Statement。
PreparedStatement的好处:
l 防止SQL攻击;
l 提高代码的可读性,以可维护性;
l 提高效率。
|
String sql = “select * from tab_student where s_number=?”; PreparedStatement pstmt = con.prepareStatement(sql); pstmt.setString(1, “S_1001”); ResultSet rs = pstmt.executeQuery(); rs.close(); pstmt.clearParameters(); pstmt.setString(1, “S_1002”); rs = pstmt.executeQuery(); |
在使用Connection创建PreparedStatement对象时需要给出一个SQL模板,所谓SQL模板就是有“?”的SQL语句,其中“?”就是参数。
在得到PreparedStatement对象后,调用它的setXXX()方法为“?”赋值,这样就可以得到把模板变成一条完整的SQL语句,然后再调用PreparedStatement对象的executeQuery()方法获取ResultSet对象。
注意PreparedStatement对象独有的executeQuery()方法是没有参数的,而Statement的executeQuery()是需要参数(SQL语句)的。因为在创建PreparedStatement对象时已经让它与一条SQL模板绑定在一起了,所以在调用它的executeQuery()和executeUpdate()方法时就不再需要参数了。
PreparedStatement最大的好处就是在于重复使用同一模板,给予其不同的参数来重复的使用它。这才是真正提高效率的原因。
所以,建议大家在今后的开发中,无论什么情况,都去需要PreparedStatement,而不是使用Statement。
你也看到了,连接数据库的四大参数是:驱动类、url、用户名,以及密码。这些参数都与特定数据库关联,如果将来想更改数据库,那么就要去修改这四大参数,那么为了不去修改代码,我们写一个JdbcUtils类,让它从配置文件中读取配置参数,然后创建连接对象。
JdbcUtils.java
|
public class JdbcUtils { private static final String dbconfig = "dbconfig.properties"; private static Properties prop = new Properties(); static { try { InputStream in = Thread.currentThread().getContextClassLoader().getResourceAsStream(dbconfig); prop.load(in); Class.forName(prop.getProperty("driverClassName")); } catch(IOException e) { throw new RuntimeException(e); } } public static Connection getConnection() { try { return DriverManager.getConnection(prop.getProperty("url"), prop.getProperty("username"), prop.getProperty("password")); } catch (Exception e) { throw new RuntimeException(e); } } } |
dbconfig.properties
|
driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/mydb1?useUnicode=true&characterEncoding=UTF8 username=root password=123 |
DAO(Data Access Object)模式就是写一个类,把访问数据库的代码封装起来。DAO在数据库与业务逻辑(Service)之间。
l 实体域,即操作的对象,例如我们操作的表是user表,那么就需要先写一个User类;
l DAO模式需要先提供一个DAO接口;
l 然后再提供一个DAO接口的实现类;
l 再编写一个DAO工厂,Service通过工厂来获取DAO实现。
User.java
|
public class User { private String uid; private String username; private String password; … } |
UserDao.java
|
public interface UserDao { public void add(User user); public void mod(User user); public void del(String uid); public User load(String uid); public List<User> findAll(); } |
UserDaoImpl.java
|
public class UserDaoImpl implements UserDao { public void add(User user) { Connection con = null; PreparedStatement pstmt = null; try { con = JdbcUtils.getConnection(); String sql = "insert into user value(?,?,?)"; pstmt = con.prepareStatement(sql); pstmt.setString(1, user.getUid()); pstmt.setString(2, user.getUsername()); pstmt.setString(3, user.getPassword()); pstmt.executeUpdate(); } catch(Exception e) { throw new RuntimeException(e); } finally { try { if(pstmt != null) pstmt.close(); if(con != null) con.close(); } catch(SQLException e) {} } } public void mod(User user) { Connection con = null; PreparedStatement pstmt = null; try { con = JdbcUtils.getConnection(); String sql = "update user set username=?, password=? where uid=?"; pstmt = con.prepareStatement(sql); pstmt.setString(1, user.getUsername()); pstmt.setString(2, user.getPassword()); pstmt.setString(3, user.getUid()); pstmt.executeUpdate(); } catch(Exception e) { throw new RuntimeException(e); } finally { try { if(pstmt != null) pstmt.close(); if(con != null) con.close(); } catch(SQLException e) {} } } public void del(String uid) { Connection con = null; PreparedStatement pstmt = null; try { con = JdbcUtils.getConnection(); String sql = "delete from user where uid=?"; pstmt = con.prepareStatement(sql); pstmt.setString(1, uid); pstmt.executeUpdate(); } catch(Exception e) { throw new RuntimeException(e); } finally { try { if(pstmt != null) pstmt.close(); if(con != null) con.close(); } catch(SQLException e) {} } } public User load(String uid) { Connection con = null; PreparedStatement pstmt = null; ResultSet rs = null; try { con = JdbcUtils.getConnection(); String sql = "select * from user where uid=?"; pstmt = con.prepareStatement(sql); pstmt.setString(1, uid); rs = pstmt.executeQuery(); if(rs.next()) { return new User(rs.getString(1), rs.getString(2), rs.getString(3)); } return null; } catch(Exception e) { throw new RuntimeException(e); } finally { try { if(pstmt != null) pstmt.close(); if(con != null) con.close(); } catch(SQLException e) {} } } public List<User> findAll() { Connection con = null; PreparedStatement pstmt = null; ResultSet rs = null; try { con = JdbcUtils.getConnection(); String sql = "select * from user"; pstmt = con.prepareStatement(sql); rs = pstmt.executeQuery(); List<User> userList = new ArrayList<User>(); while(rs.next()) { userList.add(new User(rs.getString(1), rs.getString(2), rs.getString(3))); } return userList; } catch(Exception e) { throw new RuntimeException(e); } finally { try { if(pstmt != null) pstmt.close(); if(con != null) con.close(); } catch(SQLException e) {} } } } |
UserDaoFactory.java
|
public class UserDaoFactory { private static UserDao userDao; static { try { InputStream in = Thread.currentThread().getContextClassLoader() .getResourceAsStream("dao.properties"); Properties prop = new Properties(); prop.load(in); String className = prop.getProperty("cn.itcast.jdbc.UserDao"); Class clazz = Class.forName(className); userDao = (UserDao) clazz.newInstance(); } catch (Exception e) { throw new RuntimeException(e); } } public static UserDao getUserDao() { return userDao; } } |
dao.properties
|
cn.itcast.jdbc.UserDao=cn.itcast.jdbc.UserDaoImpl |
java.sql包下给出三个与数据库相关的日期时间类型,分别是:
l Date:表示日期,只有年月日,没有时分秒。会丢失时间;
l Time:表示时间,只有时分秒,没有年月日。会丢失日期;
l Timestamp:表示时间戳,有年月日时分秒,以及毫秒。
这三个类都是java.util.Date的子类。
把数据库的三种时间类型赋给java.util.Date,基本不用转换,因为这是把子类对象给父类的引用,不需要转换。
java.sql.Date date = …
java.util.Date d = date;
java.sql.Time time = …
java.util.Date d = time;
java.sql.Timestamp timestamp = …
java.util.Date d = timestamp;
当需要把java.util.Date转换成数据库的三种时间类型时,这就不能直接赋值了,这需要使用数据库三种时间类型的构造器。java.sql包下的Date、Time、TimeStamp三个类的构造器都需要一个long类型的参数,表示毫秒值。创建这三个类型的对象,只需要有毫秒值即可。我们知道java.util.Date有getTime()方法可以获取毫秒值,那么这个转换也就不是什么问题了。
java.utl.Date d = new java.util.Date();
java.sql.Date date = new java.sql.Date(d.getTime());//会丢失时分秒
Time time = new Time(d.getTime());//会丢失年月日
Timestamp timestamp = new Timestamp(d.getTime());
我们来创建一个dt表:
|
CREATE TABLE dt( d DATE, t TIME, ts TIMESTAMP ) |
下面是向dt表中插入数据的代码:
|
@Test public void fun1() throws SQLException { Connection con = JdbcUtils.getConnection(); String sql = "insert into dt value(?,?,?)"; PreparedStatement pstmt = con.prepareStatement(sql); java.util.Date d = new java.util.Date(); pstmt.setDate(1, new java.sql.Date(d.getTime())); pstmt.setTime(2, new Time(d.getTime())); pstmt.setTimestamp(3, new Timestamp(d.getTime())); pstmt.executeUpdate(); } |
下面是从dt表中查询数据的代码:
|
@Test public void fun2() throws SQLException { Connection con = JdbcUtils.getConnection(); String sql = "select * from dt"; PreparedStatement pstmt = con.prepareStatement(sql); ResultSet rs = pstmt.executeQuery(); rs.next(); java.util.Date d1 = rs.getDate(1); java.util.Date d2 = rs.getTime(2); java.util.Date d3 = rs.getTimestamp(3); System.out.println(d1); System.out.println(d2); System.out.println(d3); } |
所谓大数据,就是大的字节数据,或大的字符数据。标准SQL中提供了如下类型来保存大数据类型:
|
类型 |
长度 |
|
tinyblob |
28--1B(256B) |
|
blob |
216-1B(64K) |
|
mediumblob |
224-1B(16M) |
|
longblob |
232-1B(4G) |
|
tinyclob |
28--1B(256B) |
|
clob |
216-1B(64K) |
|
mediumclob |
224-1B(16M) |
|
longclob |
232-1B(4G) |
但是,在mysql中没有提供tinyclob、clob、mediumclob、longclob四种类型,而是使用如下四种类型来处理文本大数据:
|
类型 |
长度 |
|
tinytext |
28--1B(256B) |
|
text |
216-1B(64K) |
|
mediumtext |
224-1B(16M) |
|
longtext |
232-1B(4G) |
首先我们需要创建一张表,表中要有一个mediumblob(16M)类型的字段。
|
CREATE TABLE tab_bin( id INT PRIMARY KEY AUTO_INCREMENT, filenameVARCHAR(100), dataMEDIUMBLOB ); |
向数据库插入二进制数据需要使用PreparedStatement为原setBinaryStream(int, InputSteam)方法来完成。
|
con = JdbcUtils.getConnection(); String sql = "insert into tab_bin(filename,data) values(?, ?)"; pstmt = con.prepareStatement(sql); pstmt.setString(1, "a.jpg"); InputStream in = new FileInputStream("f:\\a.jpg"); pstmt.setBinaryStream(2, in); pstmt.executeUpdate(); |
读取二进制数据,需要在查询后使用ResultSet类的getBinaryStream()方法来获取输入流对象。也就是说,PreparedStatement有setXXX(),那么ResultSet就有getXXX()。
|
con = JdbcUtils.getConnection(); String sql = "select filename,data from tab_bin where id=?"; pstmt = con.prepareStatement(sql); pstmt.setInt(1, 1); rs = pstmt.executeQuery(); rs.next(); String filename = rs.getString("filename"); OutputStream out = new FileOutputStream("F:\\" + filename); InputStream in = rs.getBinaryStream("data"); IOUtils.copy(in, out); out.close(); |
还有一种方法,就是把要存储的数据包装成Blob类型,然后调用PreparedStatement的setBlob()方法来设置数据
|
con = JdbcUtils.getConnection(); String sql = "insert into tab_bin(filename,data) values(?, ?)"; pstmt = con.prepareStatement(sql); pstmt.setString(1, "a.jpg"); File file = new File("f:\\a.jpg"); byte[] datas = FileUtils.getBytes(file);//获取文件中的数据 Blob blob = new SerialBlob(datas);//创建Blob对象 pstmt.setBlob(2, blob);//设置Blob类型的参数 pstmt.executeUpdate(); |
|
con = JdbcUtils.getConnection(); String sql = "select filename,data from tab_bin where id=?"; pstmt = con.prepareStatement(sql); pstmt.setInt(1, 1); rs = pstmt.executeQuery(); rs.next(); String filename = rs.getString("filename"); File file = new File("F:\\" + filename) ; Blob blob = rs.getBlob("data"); byte[] datas = blob.getBytes(0, (int)file.length()); FileUtils.writeByteArrayToFile(file, datas); |
批处理就是一批一批的处理,而不是一个一个的处理!
当你有10条SQL语句要执行时,一次向服务器发送一条SQL语句,这么做效率上很差!处理的方案是使用批处理,即一次向服务器发送多条SQL语句,然后由服务器一次性处理。
批处理只针对更新(增、删、改)语句,批处理没有查询什么事儿!
可以多次调用Statement类的addBatch(String sql)方法,把需要执行的所有SQL语句添加到一个“批”中,然后调用Statement类的executeBatch()方法来执行当前“批”中的语句。
l void addBatch(String sql):添加一条语句到“批”中;
l int[] executeBatch():执行“批”中所有语句。返回值表示每条语句所影响的行数据;
l void clearBatch():清空“批”中的所有语句。
|
for(int i = 0; i < 10; i++) { String number = "S_10" + i; String name = "stu" + i; int age = 20 + i; String gender = i % 2 == 0 ? "male" : "female"; String sql = "insert into stu values(‘" + number + "‘, ‘" + name + "‘, " + age + ", ‘" + gender + "‘)"; stmt.addBatch(sql); } stmt.executeBatch(); |
当执行了“批”之后,“批”中的SQL语句就会被清空!也就是说,连续两次调用executeBatch()相当于调用一次!因为第二次调用时,“批”中已经没有SQL语句了。
还可以在执行“批”之前,调用Statement的clearBatch()方法来清空“批”!
PreparedStatement的批处理有所不同,因为每个PreparedStatement对象都绑定一条SQL模板。所以向PreparedStatement中添加的不是SQL语句,而是给“?”赋值。
|
con = JdbcUtils.getConnection(); String sql = "insert into stu values(?,?,?,?)"; pstmt = con.prepareStatement(sql); for(int i = 0; i < 10; i++) { pstmt.setString(1, "S_10" + i); pstmt.setString(2, "stu" + i); pstmt.setInt(3, 20 + i); pstmt.setString(4, i % 2 == 0 ? "male" : "female"); pstmt.addBatch(); } pstmt.executeBatch(); |
为了方便演示事务,我们需要创建一个account表:
|
CREATE TABLE account( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(30), balance NUMERIC(10.2) );
INSERT INTO account(NAME,balance) VALUES(‘zs‘, 100000); INSERT INTO account(NAME,balance) VALUES(‘ls‘, 100000); INSERT INTO account(NAME,balance) VALUES(‘ww‘, 100000);
SELECT * FROM account; |
银行转账!张三转10000块到李四的账户,这其实需要两条SQL语句:
l 给张三的账户减去10000元;
l 给李四的账户加上10000元。
如果在第一条SQL语句执行成功后,在执行第二条SQL语句之前,程序被中断了(可能是抛出了某个异常,也可能是其他什么原因),那么李四的账户没有加上10000元,而张三却减去了10000元。这肯定是不行的!
你现在可能已经知道什么是事务了吧!事务中的多个操作,要么完全成功,要么完全失败!不可能存在成功一半的情况!也就是说给张三的账户减去10000元如果成功了,那么给李四的账户加上10000元的操作也必须是成功的;否则给张三减去10000元,以及给李四加上10000元都是失败的!
面试!
事务的四大特性是:
l 原子性(Atomicity):事务中所有操作是不可再分割的原子单位。事务中所有操作要么全部执行成功,要么全部执行失败。
l 一致性(Consistency):事务执行后,数据库状态与其它业务规则保持一致。如转账业务,无论事务执行成功与否,参与转账的两个账号余额之和应该是不变的。
l 隔离性(Isolation):隔离性是指在并发操作中,不同事务之间应该隔离开来,使每个并发中的事务不会相互干扰。
l 持久性(Durability):一旦事务提交成功,事务中所有的数据操作都必须被持久化到数据库中,即使提交事务后,数据库马上崩溃,在数据库重启时,也必须能保证通过某种机制恢复数据。
在默认情况下,MySQL每执行一条SQL语句,都是一个单独的事务。如果需要在一个事务中包含多条SQL语句,那么需要开启事务和结束事务。
l 开启事务:start transaction;
l 结束事务:commit或rollback。
在执行SQL语句之前,先执行strat transaction,这就开启了一个事务(事务的起点),然后可以去执行多条SQL语句,最后要结束事务,commit表示提交,即事务中的多条SQL语句所做出的影响会持久化到数据库中。或者rollback,表示回滚,即回滚到事务的起点,之前做的所有操作都被撤消了!
下面演示zs给li转账10000元的示例:
|
START TRANSACTION; UPDATE account SET balance=balance-10000 WHERE id=1; UPDATE account SET balance=balance+10000 WHERE id=2; ROLLBACK; |
|
START TRANSACTION; UPDATE account SET balance=balance-10000 WHERE id=1; UPDATE account SET balance=balance+10000 WHERE id=2; COMMIT; |
|
START TRANSACTION; UPDATE account SET balance=balance-10000 WHERE id=1; UPDATE account SET balance=balance+10000 WHERE id=2; quit; |
Connection的三个方法与事务相关:
l setAutoCommit(boolean):设置是否为自动提交事务,如果true(默认值就是true)表示自动提交,也就是每条执行的SQL语句都是一个单独的事务,如果设置false,那么就相当于开启了事务了;
l commit():提交结束事务;
l rollback():回滚结束事务。
|
public void transfer(boolean b) { Connection con = null; PreparedStatement pstmt = null; try { con = JdbcUtils.getConnection(); //手动提交 con.setAutoCommit(false); String sql = "update account set balance=balance+? where id=?"; pstmt = con.prepareStatement(sql); //操作 pstmt.setDouble(1, -10000); pstmt.setInt(2, 1); pstmt.executeUpdate(); // 在两个操作中抛出异常 if(b) { throw new Exception(); } pstmt.setDouble(1, 10000); pstmt.setInt(2, 2); pstmt.executeUpdate(); //提交事务 con.commit(); } catch(Exception e) { //回滚事务 if(con != null) { try { con.rollback(); } catch(SQLException ex) {} } throw new RuntimeException(e); } finally { //关闭 JdbcUtils.close(con, pstmt); } } |
保存点是JDBC3.0的东西!当要求数据库服务器支持保存点方式的回滚。
校验数据库服务器是否支持保存点!
|
boolean b = con.getMetaData().supportsSavepoints(); |
保存点的作用是允许事务回滚到指定的保存点位置。在事务中设置好保存点,然后回滚时可以选择回滚到指定的保存点,而不是回滚整个事务!注意,回滚到指定保存点并没有结束事务!!!只有回滚了整个事务才算是结束事务了!
Connection类的设置保存点,以及回滚到指定保存点方法:
l 设置保存点:Savepoint setSavepoint();
l 回滚到指定保存点:void rollback(Savepoint)。
|
/* * 李四对张三说,如果你给我转1W,我就给你转100W。 * ========================================== * * 张三给李四转1W(张三减去1W,李四加上1W) * 设置保存点! * 李四给张三转100W(李四减去100W,张三加上100W) * 查看李四余额为负数,那么回滚到保存点。 * 提交事务 */ @Test public void fun() { Connection con = null; PreparedStatement pstmt = null; try { con = JdbcUtils.getConnection(); //手动提交 con.setAutoCommit(false); String sql = "update account set balance=balance+? where name=?"; pstmt = con.prepareStatement(sql); //操作1(张三减去1W) pstmt.setDouble(1, -10000); pstmt.setString(2, "zs"); pstmt.executeUpdate(); //操作2(李四加上1W) pstmt.setDouble(1, 10000); pstmt.setString(2, "ls"); pstmt.executeUpdate(); // 设置保存点 Savepoint sp = con.setSavepoint(); //操作3(李四减去100W) pstmt.setDouble(1, -1000000); pstmt.setString(2, "ls"); pstmt.executeUpdate(); //操作4(张三加上100W) pstmt.setDouble(1, 1000000); pstmt.setString(2, "zs"); pstmt.executeUpdate(); //操作5(查看李四余额) sql = "select balance from account where name=?"; pstmt = con.prepareStatement(sql); pstmt.setString(1, "ls"); ResultSet rs = pstmt.executeQuery(); rs.next(); double balance = rs.getDouble(1); //如果李四余额为负数,那么回滚到指定保存点 if(balance < 0) { con.rollback(sp); System.out.println("张三,你上当了!"); } //提交事务 con.commit(); } catch(Exception e) { //回滚事务 if(con != null) { try { con.rollback(); } catch(SQLException ex) {} } throw new RuntimeException(e); } finally { //关闭 JdbcUtils.close(con, pstmt); } } |
l 脏读:读取到另一个事务未提交数据;
l 不可重复读:两次读取不一致;
l 幻读(虚读):读到另一事务已提交数据。
因为并发事务导致的问题大致有5类,其中两类是更新问题,三类是读问题。
l 脏读(dirty read):读到未提交更新数据,即读取到了脏数据;
l 不可重复读(unrepeatable read):对同一记录的两次读取不一致,因为另一事务对该记录做了修改;
l 幻读(phantom read):对同一张表的两次查询不一致,因为另一事务插入了一条记录;
脏读
事务1:张三给李四转账100元
事务2:李四查看自己的账户
l t1:事务1:开始事务
l t2:事务1:张三给李四转账100元
l t3:事务2:开始事务
l t4:事务2:李四查看自己的账户,看到账户多出100元(脏读)
l t5:事务2:提交事务
l t6:事务1:回滚事务,回到转账之前的状态
不可重复读
事务1:酒店查看两次1048号房间状态
事务2:预订1048号房间
l t1:事务1:开始事务
l t2:事务1:查看1048号房间状态为空闲
l t3:事务2:开始事务
l t4:事务2:预定1048号房间
l t5:事务2:提交事务
l t6:事务1:再次查看1048号房间状态为使用
l t7:事务1:提交事务
对同一记录的两次查询结果不一致!
幻读
事务1:对酒店房间预订记录两次统计
事务2:添加一条预订房间记录
l t1:事务1:开始事务
l t2:事务1:统计预订记录100条
l t3:事务2:开始事务
l t4:事务2:添加一条预订房间记录
l t5:事务2:提交事务
l t6:事务1:再次统计预订记录为101记录
l t7:事务1:提交
对同一表的两次查询不一致!
不可重复读和幻读的区别:
l 不可重复读是读取到了另一事务的更新;
l 幻读是读取到了另一事务的插入(MySQL中无法测试到幻读);
4个等级的事务隔离级别,在相同数据环境下,使用相同的输入,执行相同的工作,根据不同的隔离级别,可以导致不同的结果。不同事务隔离级别能够解决的数据并发问题的能力是不同的。
1 SERIALIZABLE(串行化)
l 不会出现任何并发问题,因为它是对同一数据的访问是串行的,非并发访问的;
l 性能最差;
2 REPEATABLE READ(可重复读)
l 防止脏读和不可重复读;(不能处理幻读)
l 性能比SERIALIZABLE好
3 READ COMMITTED(读已提交数据)
l 防止脏读;(不能处理不可重复读、幻读)
l 性能比REPEATABLE READ好
4 READ UNCOMMITTED(读未提交数据)
l 可能出现任何事务并发问题
l 性能最好
MySQL的默认隔离级别为REPEATABLE READ,这是一个很不错的选择吧!
MySQL的默认隔离级别为Repeatable read,可以通过下面语句查看:
|
select @@tx_isolation |
也可以通过下面语句来设置当前连接的隔离级别:
|
set transaction isolationlevel [4先1] |
con. setTransactionIsolation(int level)
参数可选值如下:
l Connection.TRANSACTION_READ_UNCOMMITTED;
l Connection.TRANSACTION_READ_COMMITTED;
l Connection.TRANSACTION_REPEATABLE_READ;
l Connection.TRANSACTION_SERIALIZABLE。
事务总结:
l 事务的特性:ACID;
l 事务开始边界与结束边界:开始边界(con.setAutoCommit(false)),结束边界(con.commit()或con.rollback());
l 事务的隔离级别: READ_UNCOMMITTED、READ_COMMITTED、REPEATABLE_READ、SERIALIZABLE。多个事务并发执行时才需要考虑并发事务。
用池来管理Connection,这可以重复使用Connection。有了池,所以我们就不用自己来创建Connection,而是通过池来获取Connection对象。当使用完Connection后,调用Connection的close()方法也不会真的关闭Connection,而是把Connection“归还”给池。池就可以再利用这个Connection对象了。

Java为数据库连接池提供了公共的接口:javax.sql.DataSource,各个厂商可以让自己的连接池实现这个接口。这样应用程序可以方便的切换不同厂商的连接池!
分析:ItcastPool需要有一个List,用来保存连接对象。在ItcastPool的构造器中创建5个连接对象放到List中!当用人调用了ItcastPool的getConnection()时,那么就从List拿出一个返回。当List中没有连接可用时,抛出异常。
我们需要对Connection的close()方法进行增强,所以我们需要自定义ItcastConnection类,对Connection进行装饰!即对close()方法进行增强。因为需要在调用close()方法时把连接“归还”给池,所以ItcastConnection类需要拥有池对象的引用,并且池类还要提供“归还”的方法。

ItcastPool.java
|
public class ItcastPool implements DataSource { private static Properties props = new Properties(); private List<Connection> list = new ArrayList<Connection>(); static { InputStream in = ItcastPool.class.getClassLoader() .getResourceAsStream("dbconfig.properties"); try { props.load(in); Class.forName(props.getProperty("driverClassName")); } catch (Exception e) { throw new RuntimeException(e); } } public ItcastPool() throws SQLException { for (int i = 0; i < 5; i++) { Connection con = DriverManager.getConnection( props.getProperty("url"), props.getProperty("username"), props.getProperty("password")); ItcastConnection conWapper = new ItcastConnection(con, this); list.add(conWapper); } } public void add(Connection con) { list.add(con); } public Connection getConnection() throws SQLException { if(list.size() > 0) { return list.remove(0); } throw new SQLException("没连接了"); } ...... } |
ItcastConnection.java
|
public class ItcastConnection extends ConnectionWrapper { private ItcastPool pool; public ItcastConnection(Connection con, ItcastPool pool) { super(con); this.pool = pool; } @Override public void close() throws SQLException { pool.add(this); } } |
DBCP是Apache提供的一款开源免费的数据库连接池!
Hibernate3.0之后不再对DBCP提供支持!因为Hibernate声明DBCP有致命的缺欠!DBCP因为Hibernate的这一毁谤很是生气,并且说自己没有缺欠。
|
public void fun1() throws SQLException { BasicDataSource ds = new BasicDataSource(); ds.setUsername("root"); ds.setPassword("123"); ds.setUrl("jdbc:mysql://localhost:3306/mydb1"); ds.setDriverClassName("com.mysql.jdbc.Driver"); ds.setMaxActive(20); ds.setMaxIdle(10); ds.setInitialSize(10); ds.setMinIdle(2); ds.setMaxWait(1000); Connection con = ds.getConnection(); System.out.println(con.getClass().getName()); con.close(); } |
下面是对DBCP的配置介绍:
|
#基本配置 driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/mydb1 username=root password=123 #初始化池大小,即一开始池中就会有10个连接对象 默认值为0 initialSize=0 #最大连接数,如果设置maxActive=50时,池中最多可以有50个连接,当然这50个连接中包含被使用的和没被使用的(空闲) #你是一个包工头,你一共有50个工人,但这50个工人有的当前正在工作,有的正在空闲 #默认值为8,如果设置为非正数,表示没有限制!即无限大 maxActive=8 #最大空闲连接 #当设置maxIdle=30时,你是包工头,你允许最多有20个工人空闲,如果现在有30个空闲工人,那么要开除10个 #默认值为8,如果设置为负数,表示没有限制!即无限大 maxIdle=8 #最小空闲连接 #如果设置minIdel=5时,如果你的工人只有3个空闲,那么你需要再去招2个回来,保证有5个空闲工人 #默认值为0 minIdle=0 #最大等待时间 #当设置maxWait=5000时,现在你的工作都出去工作了,又来了一个工作,需要一个工人。 #这时就要等待有工人回来,如果等待5000毫秒还没回来,那就抛出异常 #没有工人的原因:最多工人数为50,已经有50个工人了,不能再招了,但50人都出去工作了。 #默认值为-1,表示无限期等待,不会抛出异常。 maxWait=-1 #连接属性 #就是原来放在url后面的参数,可以使用connectionProperties来指定 #如果已经在url后面指定了,那么就不用在这里指定了。 #useServerPrepStmts=true,MySQL开启预编译功能 #cachePrepStmts=true,MySQL开启缓存PreparedStatement功能, #prepStmtCacheSize=50,缓存PreparedStatement的上限 #prepStmtCacheSqlLimit=300,当SQL模板长度大于300时,就不再缓存它 connectionProperties=useUnicode=true;characterEncoding=UTF8;useServerPrepStmts=true;cachePrepStmts=true;prepStmtCacheSize=50;prepStmtCacheSqlLimit=300 #连接的默认提交方式 #默认值为true defaultAutoCommit=true #连接是否为只读连接 #Connection有一对方法:setReadOnly(boolean)和isReadOnly() #如果是只读连接,那么你只能用这个连接来做查询 #指定连接为只读是为了优化!这个优化与并发事务相关! #如果两个并发事务,对同一行记录做增、删、改操作,是不是一定要隔离它们啊? #如果两个并发事务,对同一行记录只做查询操作,那么是不是就不用隔离它们了? #如果没有指定这个属性值,那么是否为只读连接,这就由驱动自己来决定了。即Connection的实现类自己来决定! defaultReadOnly=false #指定事务的事务隔离级别 #可选值:NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE #如果没有指定,那么由驱动中的Connection实现类自己来决定 defaultTransactionIsolation=REPEATABLE_READ |
C3P0也是开源免费的连接池!C3P0被很多人看好!
C3P0中池类是:ComboPooledDataSource。
|
public void fun1() throws PropertyVetoException, SQLException { ComboPooledDataSource ds = new ComboPooledDataSource(); ds.setJdbcUrl("jdbc:mysql://localhost:3306/mydb1"); ds.setUser("root"); ds.setPassword("123"); ds.setDriverClass("com.mysql.jdbc.Driver"); ds.setAcquireIncrement(5); ds.setInitialPoolSize(20); ds.setMinPoolSize(2); ds.setMaxPoolSize(50); Connection con = ds.getConnection(); System.out.println(con); con.close(); } |
c3p0也可以指定配置文件,而且配置文件可以是properties,也可骒xml的。当然xml的高级一些了。但是c3p0的配置文件名必须为c3p0-config.xml,并且必须放在类路径下。
|
<?xml version="1.0" encoding="UTF-8"?> <c3p0-config> <default-config> <property name="jdbcUrl">jdbc:mysql://localhost:3306/mydb1</property> <property name="driverClass">com.mysql.jdbc.Driver</property> <property name="user">root</property> <property name="password">123</property> <property name="acquireIncrement">3</property> <property name="initialPoolSize">10</property> <property name="minPoolSize">2</property> <property name="maxPoolSize">10</property> </default-config> <named-config name="oracle-config"> <property name="jdbcUrl">jdbc:mysql://localhost:3306/mydb1</property> <property name="driverClass">com.mysql.jdbc.Driver</property> <property name="user">root</property> <property name="password">123</property> <property name="acquireIncrement">3</property> <property name="initialPoolSize">10</property> <property name="minPoolSize">2</property> <property name="maxPoolSize">10</property> </named-config> </c3p0-config> |
c3p0的配置文件中可以配置多个连接信息,可以给每个配置起个名字,这样可以方便的通过配置名称来切换配置信息。上面文件中默认配置为mysql的配置,名为oracle-config的配置也是mysql的配置,呵呵。
|
public void fun2() throws PropertyVetoException, SQLException { ComboPooledDataSource ds = new ComboPooledDataSource(); Connection con = ds.getConnection(); System.out.println(con); con.close(); } |
|
public void fun2() throws PropertyVetoException, SQLException { ComboPooledDataSource ds = new ComboPooledDataSource("orcale-config"); Connection con = ds.getConnection(); System.out.println(con); con.close(); } |
JNDI(Java Naming and Directory Interface),Java命名和目录接口。JNDI的作用就是:在服务器上配置资源,然后通过统一的方式来获取配置的资源。
我们这里要配置的资源当然是连接池了,这样项目中就可以通过统一的方式来获取连接池对象了。
下图是Tomcat文档提供的:

配置JNDI资源需要到<Context>元素中配置<Resource>子元素:
l name:指定资源的名称,这个名称可以随便给,在获取资源时需要这个名称;
l factory:用来创建资源的工厂,这个值基本上是固定的,不用修改;
l type:资源的类型,我们要给出的类型当然是我们连接池的类型了;
l bar:表示资源的属性,如果资源存在名为bar的属性,那么就配置bar的值。对于DBCP连接池而言,你需要配置的不是bar,因为它没有bar这个属性,而是应该去配置url、username等属性。
|
<Context> <Resource name="mydbcp" type="org.apache.tomcat.dbcp.dbcp.BasicDataSource" factory="org.apache.naming.factory.BeanFactory" username="root" password="123" driverClassName="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1/mydb1" maxIdle="3" maxWait="5000" maxActive="5" initialSize="3"/> </Context> |
|
<Context> <Resource name="myc3p0" type="com.mchange.v2.c3p0.ComboPooledDataSource" factory="org.apache.naming.factory.BeanFactory" user="root" password="123" classDriver="com.mysql.jdbc.Driver" jdbcUrl="jdbc:mysql://127.0.0.1/mydb1" maxPoolSize="20" minPoolSize ="5" initialPoolSize="10" acquireIncrement="2"/> </Context> |
配置资源的目的当然是为了获取资源了。只要你启动了Tomcat,那么就可以在项目中任何类中通过JNDI获取资源的方式来获取资源了。
下图是Tomcat文档提供的,与上面Tomcat文档提供的配置资源是对应的。

获取资源:
l Context:javax.naming.Context;
l InitialContext:javax.naming.InitialContext;
l lookup(String):获取资源的方法,其中”java:comp/env”是资源的入口(这是固定的名称),获取过来的还是一个Context,这说明需要在获取到的Context上进一步进行获取。”bean/MyBeanFactory”对应<Resource>中配置的name值,这回获取的就是资源对象了。
|
Context cxt = new InitialContext(); DataSource ds = (DataSource)cxt.lookup("java:/comp/env/mydbcp"); Connection con = ds.getConnection(); System.out.println(con); con.close(); |
|
Context cxt = new InitialContext(); Context envCxt = (Context)cxt.lookup("java:/comp/env"); DataSource ds = (DataSource)env.lookup("mydbcp"); Connection con = ds.getConnection(); System.out.println(con); con.close(); |
上面两种方式是相同的效果。
因为已经学习了连接池,那么JdbcUtils的获取连接对象的方法也要修改一下了。
JdbcUtils.java
|
public class JdbcUtils { private static DataSource dataSource = new ComboPooledDataSource(); public static DataSource getDataSource() { return dataSource; } public static Connection getConnection() { try { return dataSource.getConnection(); } catch (Exception e) { throw new RuntimeException(e); } } } |
ThreadLocal类只有三个方法:
l void set(T value):保存值;
l T get():获取值;
l void remove():移除值。
ThreadLocal内部其实是个Map来保存数据。虽然在使用ThreadLocal时只给出了值,没有给出键,其实它内部使用了当前线程做为键。
|
class MyThreadLocal<T> { private Map<Thread,T> map = new HashMap<Thread,T>(); public void set(T value) { map.put(Thread.currentThread(), value); } public void remove() { map.remove(Thread.currentThread()); } public T get() { return map.get(Thread.currentThread()); } } |

在开始客户管理系统之前,我们先写一个工具类:BaseServlet。
我们知道,写一个项目可能会出现N多个Servlet,而且一般一个Servlet只有一个方法(doGet或doPost),如果项目大一些,那么Servlet的数量就会很惊人。
为了避免Servlet的“膨胀”,我们写一个BaseServlet。它的作用是让一个Servlet可以处理多种不同的请求。不同的请求调用Servlet的不同方法。我们写好了BaseServlet后,让其他Servlet继承BaseServlet,例如CustomerServlet继承BaseServlet,然后在CustomerServlet中提供add()、update()、delete()等方法,每个方法对应不同的请求。

我们知道,Servlet中处理请求的方法是service()方法,这说明我们需要让service()方法去调用其他方法。例如调用add()、mod()、del()、all()等方法!具体调用哪个方法需要在请求中给出方法名称!然后service()方法通过方法名称来调用指定的方法。
无论是点击超链接,还是提交表单,请求中必须要有method参数,这个参数的值就是要请求的方法名称,这样BaseServlet的service()才能通过方法名称来调用目标方法。例如某个链接如下:
<a href=”/xxx/CustomerServlet?method=add”>添加客户</a>

|
public class BaseServlet extends HttpServlet { /* * 它会根据请求中的m,来决定调用本类的哪个方法 */ protected void service(HttpServletRequest req, HttpServletResponse res) throws ServletException, IOException { req.setCharacterEncoding("UTF-8"); res.setContentType("text/html;charset=utf-8"); // 例如:http://localhost:8080/demo1/xxx?m=add String methodName = req.getParameter("method");// 它是一个方法名称 // 当没用指定要调用的方法时,那么默认请求的是execute()方法。 if(methodName == null || methodName.isEmpty()) { methodName = "execute"; } Class c = this.getClass(); try { // 通过方法名称获取方法的反射对象 Method m = c.getMethod(methodName, HttpServletRequest.class, HttpServletResponse.class); // 反射方法目标方法,也就是说,如果methodName为add,那么就调用add方法。 String result = (String) m.invoke(this, req, res); // 通过返回值完成请求转发 if(result != null && !result.isEmpty()) { req.getRequestDispatcher(result).forward(req, res); } } catch (Exception e) { throw new ServletException(e); } } } |
DBUtils是Apache Commons组件中的一员,开源免费!
DBUtils是对JDBC的简单封装,但是它还是被很多公司使用!
DBUtils的Jar包:dbutils.jar
l DbUtils:都是静态方法,一系列的close()方法;
l QueryRunner:
Ø update():执行insert、update、delete;
Ø query():执行select语句;
Ø batch():执行批处理。
QueryRunner的update()方法可以用来执行insert、update、delete语句。
1. 创建QueryRunner
构造器:QueryRunner();
2. update()方法
int update(Connection con, String sql, Object… params)
|
@Test public void fun1() throws SQLException { QueryRunner qr = new QueryRunner(); String sql = "insert into user values(?,?,?)"; qr.update(JdbcUtils.getConnection(), sql, "u1", "zhangSan", "123"); } |
还有另一种方式来使用QueryRunner
1. 创建QueryRunner
构造器:QueryRunner(DataSource)
2. update()方法
int update(String sql, Object… params)
这种方式在创建QueryRunner时传递了连接池对象,那么在调用update()方法时就不用再传递Connection了。
|
@Test public void fun2() throws SQLException { QueryRunner qr = new QueryRunner(JdbcUtils.getDataSource()); String sql = "insert into user values(?,?,?)"; qr.update(sql, "u1", "zhangSan", "123"); } |
我们知道在执行select语句之后得到的是ResultSet,然后我们还需要对ResultSet进行转换,得到最终我们想要的数据。你可以希望把ResultSet的数据放到一个List中,也可能想把数据放到一个Map中,或是一个Bean中。
DBUtils提供了一个接口ResultSetHandler,它就是用来ResultSet转换成目标类型的工具。你可以自己去实现这个接口,把ResultSet转换成你想要的类型。
DBUtils提供了很多个ResultSetHandler接口的实现,这些实现已经基本够用了,我们通常不用自己去实现ResultSet接口了。
l MapHandler:单行处理器!把结果集转换成Map<String,Object>,其中列名为键!
l MapListHandler:多行处理器!把结果集转换成List<Map<String,Object>>;
l BeanHandler:单行处理器!把结果集转换成Bean,该处理器需要Class参数,即Bean的类型;
l BeanListHandler:多行处理器!把结果集转换成List<Bean>;
l ColumnListHandler:多行单列处理器!把结果集转换成List<Object>,使用ColumnListHandler时需要指定某一列的名称或编号,例如:new ColumListHandler(“name”)表示把name列的数据放到List中。
l ScalarHandler:单行单列处理器!把结果集转换成Object。一般用于聚集查询,例如select count(*) from tab_student。
Map处理器

Bean处理器
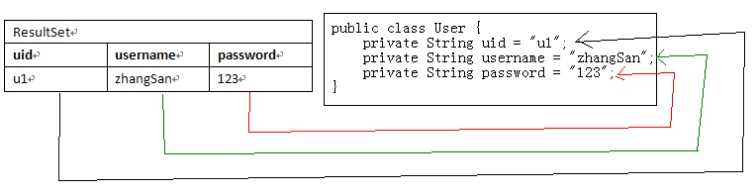
Column处理器
Scalar处理器
QueryRunner的查询方法是:
public <T> T query(String sql, ResultSetHandler<T> rh, Object… params)
public <T> T query(Connection con, String sql, ResultSetHandler<T> rh, Object… params)
query()方法会通过sql语句和params查询出ResultSet,然后通过rh把ResultSet转换成对应的类型再返回。
|
@Test public void fun1() throws SQLException { DataSource ds = JdbcUtils.getDataSource(); QueryRunner qr = new QueryRunner(ds); String sql = "select * from tab_student where number=?"; Map<String,Object> map = qr.query(sql, new MapHandler(), "S_2000"); System.out.println(map); } @Test public void fun2() throws SQLException { DataSource ds = JdbcUtils.getDataSource(); QueryRunner qr = new QueryRunner(ds); String sql = "select * from tab_student"; List<Map<String,Object>> list = qr.query(sql, new MapListHandler()); for(Map<String,Object> map : list) { System.out.println(map); } } @Test public void fun3() throws SQLException { DataSource ds = JdbcUtils.getDataSource(); QueryRunner qr = new QueryRunner(ds); String sql = "select * from tab_student where number=?"; Student stu = qr.query(sql, new BeanHandler<Student>(Student.class), "S_2000"); System.out.println(stu); } @Test public void fun4() throws SQLException { DataSource ds = JdbcUtils.getDataSource(); QueryRunner qr = new QueryRunner(ds); String sql = "select * from tab_student"; List<Student> list = qr.query(sql, new BeanListHandler<Student>(Student.class)); for(Student stu : list) { System.out.println(stu); } } @Test public void fun5() throws SQLException { DataSource ds = JdbcUtils.getDataSource(); QueryRunner qr = new QueryRunner(ds); String sql = "select * from tab_student"; List<Object> list = qr.query(sql, new ColumnListHandler("name")); for(Object s : list) { System.out.println(s); } } @Test public void fun6() throws SQLException { DataSource ds = JdbcUtils.getDataSource(); QueryRunner qr = new QueryRunner(ds); String sql = "select count(*) from tab_student"; Number number = (Number)qr.query(sql, new ScalarHandler()); int cnt = number.intValue(); System.out.println(cnt); } |
QueryRunner还提供了批处理方法:batch()。
我们更新一行记录时需要指定一个Object[]为参数,如果是批处理,那么就要指定Object[][]为参数了。即多个Object[]就是Object[][]了,其中每个Object[]对应一行记录:
|
@Test public void fun10() throws SQLException { DataSource ds = JdbcUtils.getDataSource(); QueryRunner qr = new QueryRunner(ds); String sql = "insert into tab_student values(?,?,?,?)"; Object[][] params = new Object[10][];//表示 要插入10行记录 for(int i = 0; i < params.length; i++) { params[i] = new Object[]{"S_300" + i, "name" + i, 30 + i, i%2==0?"男":"女"}; } qr.batch(sql, params); } |
过滤器JavaWeb三大组件之一,它与Servlet很相似!不它过滤器是用来拦截请求的,而不是处理请求的。
当用户请求某个Servlet时,会先执行部署在这个请求上的Filter,如果Filter“放行”,那么会继承执行用户请求的Servlet;如果Filter不“放行”,那么就不会执行用户请求的Servlet。
其实可以这样理解,当用户请求某个Servlet时,Tomcat会去执行注册在这个请求上的Filter,然后是否“放行”由Filter来决定。可以理解为,Filter来决定是否调用Servlet!当执行完成Servlet的代码后,还会执行Filter后面的代码。
其实过滤器与Servlet很相似,我们回忆一下如果写的第一个Servlet应用!写一个类,实现Servlet接口!没错,写过滤器就是写一个类,实现Filter接口。
|
public class HelloFilter implements Filter { public void init(FilterConfig filterConfig) throws ServletException {} public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { System.out.println("Hello Filter"); } public void destroy() {} } |
第二步也与Servlet一样,在web.xml文件中部署Filter:
|
<filter> <filter-name>helloFilter</filter-name> <filter-class>cn.itcast.filter.HelloFilter</filter-class> </filter> <filter-mapping> <filter-name>helloFilter</filter-name> <url-pattern>/index.jsp</url-pattern> </filter-mapping> |
应该没有问题吧,都可以看懂吧!
OK了,现在可以尝试去访问index.jsp页面了,看看是什么效果!
当用户访问index.jsp页面时,会执行HelloFilter的doFilter()方法!在我们的示例中,index.jsp页面是不会被执行的,如果想执行index.jsp页面,那么我们需要放行!
|
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { System.out.println("filter start..."); chain.doFilter(request, response); System.out.println("filter end..."); } |
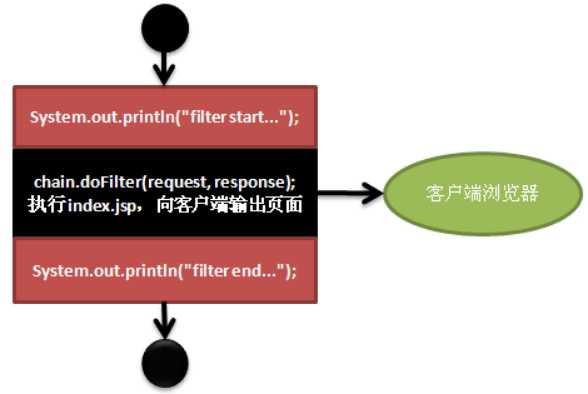
有很多同学总是错误的认为,一个请求在给客户端输出之后就算是结束了,这是不对的!其实很多事情都需要在给客户端响应之后才能完成!
我们已经学习过Servlet的生命周期,那么Filter的生命周期也就没有什么难度了!
l init(FilterConfig):在服务器启动时会创建Filter实例,并且每个类型的Filter只创建一个实例,从此不再创建!在创建完Filter实例后,会马上调用init()方法完成初始化工作,这个方法只会被执行一次;
l doFilter(ServletRequest req,ServletResponse res,FilterChain chain):这个方法会在用户每次访问“目标资源(<url->pattern>index.jsp</url-pattern>)”时执行,如果需要“放行”,那么需要调用FilterChain的doFilter(ServletRequest,ServletResponse)方法,如果不调用FilterChain的doFilter()方法,那么目标资源将无法执行;
l destroy():服务器会在创建Filter对象之后,把Filter放到缓存中一直使用,通常不会销毁它。一般会在服务器关闭时销毁Filter对象,在销毁Filter对象之前,服务器会调用Filter对象的destory()方法。
你已经看到了吧,Filter接口中的init()方法的参数类型为FilterConfig类型。它的功能与ServletConfig相似,与web.xml文件中的配置信息对应。下面是FilterConfig的功能介绍:
l ServletContext getServletContext():获取ServletContext的方法;
l String getFilterName():获取Filter的配置名称;与<filter-name>元素对应;
l String getInitParameter(String name):获取Filter的初始化配置,与<init-param>元素对应;
l Enumeration getInitParameterNames():获取所有初始化参数的名称。

doFilter()方法的参数中有一个类型为FilterChain的参数,它只有一个方法:doFilter(ServletRequest,ServletResponse)。
前面我们说doFilter()方法的放行,让请求流访问目标资源!但这么说不严密,其实调用该方法的意思是,“我(当前Filter)”放行了,但不代表其他人(其他过滤器)也放行。
也就是说,一个目标资源上,可能部署了多个过滤器,就好比在你去北京的路上有多个打劫的匪人(过滤器),而其中第一伙匪人放行了,但不代表第二伙匪人也放行了,所以调用FilterChain类的doFilter()方法表示的是执行下一个过滤器的doFilter()方法,或者是执行目标资源!
如果当前过滤器是最后一个过滤器,那么调用chain.doFilter()方法表示执行目标资源,而不是最后一个过滤器,那么chain.doFilter()表示执行下一个过滤器的doFilter()方法。
一个目标资源可以指定多个过滤器,过滤器的执行顺序是在web.xml文件中的部署顺序:
|
<filter> <filter-name>myFilter1</filter-name> <filter-class>cn.itcast.filter.MyFilter1</filter-class> </filter> <filter-mapping> <filter-name>myFilter1</filter-name> <url-pattern>/index.jsp</url-pattern> </filter-mapping> <filter> <filter-name>myFilter2</filter-name> <filter-class>cn.itcast.filter.MyFilter2</filter-class> </filter> <filter-mapping> <filter-name>myFilter2</filter-name> <url-pattern>/index.jsp</url-pattern> </filter-mapping> |
|
public class MyFilter1 extends HttpFilter { public void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws IOException, ServletException { System.out.println("filter1 start..."); chain.doFilter(request, response);//放行,执行MyFilter2的doFilter()方法 System.out.println("filter1 end..."); } } |
|
public class MyFilter2 extends HttpFilter { public void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws IOException, ServletException { System.out.println("filter2 start..."); chain.doFilter(request, response);//放行,执行目标资源 System.out.println("filter2 end..."); } } |
|
<body> This is my JSP page. <br> <h1>index.jsp</h1> <%System.out.println("index.jsp"); %> </body> |
当有用户访问index.jsp页面时,输出结果如下:
|
filter1 start... filter2 start... index.jsp filter2 end... filter1 end... |
我们来做个测试,写一个过滤器,指定过滤的资源为b.jsp,然后我们在浏览器中直接访问b.jsp,你会发现过滤器执行了!
但是,当我们在a.jsp中request.getRequestDispathcer(“/b.jsp”).forward(request,response)时,就不会再执行过滤器了!也就是说,默认情况下,只能直接访问目标资源才会执行过滤器,而forward执行目标资源,不会执行过滤器!
|
public class MyFilter extends HttpFilter { public void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws IOException, ServletException { System.out.println("myfilter..."); chain.doFilter(request, response); } } |
|
<filter> <filter-name>myfilter</filter-name> <filter-class>cn.itcast.filter.MyFilter</filter-class> </filter> <filter-mapping> <filter-name>myfilter</filter-name> <url-pattern>/b.jsp</url-pattern> </filter-mapping> |
|
<body> <h1>b.jsp</h1> </body> |
|
<h1>a.jsp</h1> <% request.getRequestDispatcher("/b.jsp").forward(request, response); %> </body> |
http://localhost:8080/filtertest/b.jsp -->直接访问b.jsp时,会执行过滤器内容;
http://localhost:8080/filtertest/a.jsp --> 访问a.jsp,但a.jsp会forward到b.jsp,这时就不会执行过滤器!
其实过滤器有四种拦截方式!分别是:REQUEST、FORWARD、INCLUDE、ERROR。
l REQUEST:直接访问目标资源时执行过滤器。包括:在地址栏中直接访问、表单提交、超链接、重定向,只要在地址栏中可以看到目标资源的路径,就是REQUEST;
l FORWARD:转发访问执行过滤器。包括RequestDispatcher#forward()方法、<jsp:forward>标签都是转发访问;
l INCLUDE:包含访问执行过滤器。包括RequestDispatcher#include()方法、<jsp:include>标签都是包含访问;
l ERROR:当目标资源在web.xml中配置为<error-page>中时,并且真的出现了异常,转发到目标资源时,会执行过滤器。
可以在<filter-mapping>中添加0~n个<dispatcher>子元素,来说明当前访问的拦截方式。
|
<filter-mapping> <filter-name>myfilter</filter-name> <url-pattern>/b.jsp</url-pattern> <dispatcher>REQUEST</dispatcher> <dispatcher>FORWARD</dispatcher> </filter-mapping> |
|
<filter-mapping> <filter-name>myfilter</filter-name> <url-pattern>/b.jsp</url-pattern> </filter-mapping> |
|
<filter-mapping> <filter-name>myfilter</filter-name> <url-pattern>/b.jsp</url-pattern> <dispatcher>FORWARD</dispatcher> </filter-mapping> |
其实最为常用的就是REQUEST和FORWARD两种拦截方式,而INCLUDE和ERROR都比较少用!其中INCLUDE比较好理解,我们这里不再给出代码,学员可以通过FORWARD方式修改,来自己测试。而ERROR方式不易理解,下面给出ERROR拦截方式的例子:
|
<filter-mapping> <filter-name>myfilter</filter-name> <url-pattern>/b.jsp</url-pattern> <dispatcher>ERROR</dispatcher> </filter-mapping> <error-page> <error-code>500</error-code> <location>/b.jsp</location> </error-page> |
|
<body> <h1>a.jsp</h1> <% if(true) throw new RuntimeException("嘻嘻~"); %> </body> |
过滤器的应用场景:
l 执行目标资源之前做预处理工作,例如设置编码,这种试通常都会放行,只是在目标资源执行之前做一些准备工作;
l 通过条件判断是否放行,例如校验当前用户是否已经登录,或者用户IP是否已经被禁用;
l 在目标资源执行后,做一些后续的特殊处理工作,例如把目标资源输出的数据进行处理;
在web.xml文件中部署Filter时,可以通过“*”来执行目标资源:
|
<filter-mapping> <filter-name>myfilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> |
这一特性与Servlet完全相同!通过这一特性,我们可以在用户访问敏感资源时,执行过滤器,例如:<url-pattern>/admin/*<url-pattern>,可以把所有管理员才能访问的资源放到/admin路径下,这时可以通过过滤器来校验用户身份。
还可以为<filter-mapping>指定目标资源为某个Servlet,例如:
|
<servlet> <servlet-name>myservlet</servlet-name> <servlet-class>cn.itcast.servlet.MyServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>myservlet</servlet-name> <url-pattern>/abc</url-pattern> </servlet-mapping> <filter> <filter-name>myfilter</filter-name> <filter-class>cn.itcast.filter.MyFilter</filter-class> </filter> <filter-mapping> <filter-name>myfilter</filter-name> <servlet-name>myservlet</servlet-name> </filter-mapping> |
当用户访问http://localhost:8080/filtertest/abc时,会执行名字为myservlet的Servlet,这时会执行过滤器。
Filter的三个方法:
l void init(FilterConfig):在Tomcat启动时被调用;
l void destroy():在Tomcat关闭时被调用;
l void doFilter(ServletRequest,ServletResponse,FilterChain):每次有请求时都调用该方法;
FilterConfig类:与ServletConfig相似,用来获取Filter的初始化参数
l ServletContext getServletContext():获取ServletContext的方法;
l String getFilterName():获取Filter的配置名称;
l String getInitParameter(String name):获取Filter的初始化配置,与<init-param>元素对应;
l Enumeration getInitParameterNames():获取所有初始化参数的名称。
FilterChain类:
l void doFilter(ServletRequest,ServletResponse):放行!表示执行下一个过滤器,或者执行目标资源。可以在调用FilterChain的doFilter()方法的前后添加语句,在FilterChain的doFilter()方法之前的语句会在目标资源执行之前执行,在FilterChain的doFilter()方法之后的语句会在目标资源执行之后执行。
四各拦截方式:REQUEST、FORWARD、INCLUDE、ERROR,默认是REQUEST方式。
l REQUEST:拦截直接请求方式;
l FORWARD:拦截请求转发方式;
l INCLUDE:拦截请求包含方式;
l ERROR:拦截错误转发方式。
网站统计每个IP地址访问本网站的次数。
因为一个网站可能有多个页面,无论哪个页面被访问,都要统计访问次数,所以使用过滤器最为方便。
因为需要分IP统计,所以可以在过滤器中创建一个Map,使用IP为key,访问次数为value。当有用户访问时,获取请求的IP,如果IP在Map中存在,说明以前访问过,那么在访问次数上加1,即可;IP在Map中不存在,那么设置次数为1。
把这个Map存放到ServletContext中!
index.jsp
|
<body> <h1>分IP统计访问次数</h1> <table align="center" width="50%" border="1"> <tr> <th>IP地址</th> <th>次数</th> </tr> <c:forEach items="${applicationScope.ipCountMap }" var="entry"> <tr> <td>${entry.key }</td> <td>${entry.value }</td> </tr> </c:forEach> </table> </body> |
IPFilter
|
public class IPFilter implements Filter { private ServletContext context; public void init(FilterConfig fConfig) throws ServletException { context = fConfig.getServletContext(); Map<String, Integer> ipCountMap = Collections .synchronizedMap(new LinkedHashMap<String, Integer>()); context.setAttribute("ipCountMap", ipCountMap); } @SuppressWarnings("unchecked") public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { HttpServletRequest req = (HttpServletRequest) request; String ip = req.getRemoteAddr(); Map<String, Integer> ipCountMap = (Map<String, Integer>) context .getAttribute("ipCountMap"); Integer count = ipCountMap.get(ip); if (count == null) { count = 1; } else { count += 1; } ipCountMap.put(ip, count); context.setAttribute("ipCountMap", ipCountMap); chain.doFilter(request, response); } public void destroy() {} } |
|
<filter> <display-name>IPFilter</display-name> <filter-name>IPFilter</filter-name> <filter-class>cn.itcast.filter.ip.IPFilter</filter-class> </filter> <filter-mapping> <filter-name>IPFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> |
我们给出三个页面:index.jsp、user.jsp、admin.jsp。
l index.jsp:谁都可以访问,没有限制;
l user.jsp:只有登录用户才能访问;
l admin.jsp:只有管理员才能访问。
设计User类:username、password、grade,其中grade表示用户等级,1表示普通用户,2表示管理员用户。
当用户登录成功后,把user保存到session中。
创建LoginFilter,它有两种过滤方式:
l 如果访问的是user.jsp,查看session中是否存在user;
l 如果访问的是admin.jsp,查看session中是否存在user,并且user的grade等于2。
User.java
|
public class User { private String username; private String password; private int grade; … } |
为了方便,这里就不使用数据库了,所以我们需要在UserService中创建一个Map,用来保存所有用户。Map中的key中用户名,value为User对象。
UserService.java
|
public class UserService { private static Map<String,User> users = new HashMap<String,User>(); static { users.put("zhangSan", new User("zhangSan", "123", 1)); users.put("liSi", new User("liSi", "123", 2)); } public User login(String username, String password) { User user = users.get(username); if(user == null) return null; return user.getPassword().equals(password) ? user : null; } } |
login.jsp
|
<body> <h1>登录</h1> <p style="font-weight: 900; color: red">${msg }</p> <form action="<c:url value=‘/LoginServlet‘/>" method="post"> 用户名:<input type="text" name="username"/><br/> 密 码:<input type="password" name="password"/><br/> <input type="submit" value="登录"/> </form> </body> |
index.jsp
|
<body> <h1>主页</h1> <h3>${user.username }</h3> <hr/> <a href="<c:url value=‘/login.jsp‘/>">登录</a><br/> <a href="<c:url value=‘/user/user.jsp‘/>">用户页面</a><br/> <a href="<c:url value=‘/admin/admin.jsp‘/>">管理员页面</a> </body> |
/user/user.jsp
|
<body> <h1>用户页面</h1> <h3>${user.username }</h3> <hr/> </body> |
/admin/admin.jsp
|
<body> <h1>管理员页面</h1> <h3>${user.username }</h3> <hr/> </body> |
LoginServlet
|
public class LoginServlet extends HttpServlet { public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.setCharacterEncoding("utf-8"); response.setContentType("text/html;charset=utf-8"); String username = request.getParameter("username"); String password = request.getParameter("password"); UserService userService = new UserService(); User user = userService.login(username, password); if(user == null) { request.setAttribute("msg", "用户名或密码错误"); request.getRequestDispatcher("/login.jsp").forward(request, response); } else { request.getSession().setAttribute("user", user); request.getRequestDispatcher("/index.jsp").forward(request, response); } } } |
LoginUserFilter.java
|
<filter> <display-name>LoginUserFilter</display-name> <filter-name>LoginUserFilter</filter-name> <filter-class>cn.itcast.filter.LoginUserFilter</filter-class> </filter> <filter-mapping> <filter-name>LoginUserFilter</filter-name> <url-pattern>/user/*</url-pattern> </filter-mapping> |
|
public class LoginUserFilter implements Filter { public void destroy() {} public void init(FilterConfig fConfig) throws ServletException {} public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { response.setContentType("text/html;charset=utf-8"); HttpServletRequest req = (HttpServletRequest) request; User user = (User) req.getSession().getAttribute("user"); if(user == null) { response.getWriter().print("您还没有登录"); return; } chain.doFilter(request, response); } } |
LoginAdminFilter.java
|
<filter> <display-name>LoginAdminFilter</display-name> <filter-name>LoginAdminFilter</filter-name> <filter-class>cn.itcast.filter.LoginAdminFilter</filter-class> </filter> <filter-mapping> <filter-name>LoginAdminFilter</filter-name> <url-pattern>/admin/*</url-pattern> </filter-mapping> |
|
public class LoginAdminFilter implements Filter { public void destroy() {} public void init(FilterConfig fConfig) throws ServletException {} public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { response.setContentType("text/html;charset=utf-8"); HttpServletRequest req = (HttpServletRequest) request; User user = (User) req.getSession().getAttribute("user"); if(user == null) { response.getWriter().print("您还没有登录!"); return; } if(user.getGrade() < 2) { response.getWriter().print("您的等级不够!"); return; } chain.doFilter(request, response); } } |
浏览器只是要缓存页面,这对我们在开发时测试很不方便,所以我们可以过滤所有资源,然后添加去除所有缓存!
|
public class NoCacheFilter extends HttpFilter { public void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws IOException, ServletException { response.setHeader("cache-control", "no-cache"); response.setHeader("pragma", "no-cache"); response.setHeader("expires", "0"); chain.doFilter(request, response); } } |
但是要注意,有的浏览器可能不会理会你的设置,还是会缓存的!这时就要在页面中使用时间戳来处理了。
乱码问题:
l 获取请求参数中的乱码问题;
Ø POST请求:request.setCharacterEncoding(“utf-8”);
Ø GET请求:new String(request.getParameter(“xxx”).getBytes(“iso-8859-1”), “utf-8”);
l 响应的乱码问题:response.setContextType(“text/html;charset=utf-8”)。
基本上在每个Servlet中都要处理乱码问题,所以应该把这个工作放到过滤器中来完成。
其实全站乱码问题的难点就是处理GET请求参数的问题。
如果只是处理POST请求的编码问题,以及响应编码问题,那么这个过滤器就太!太!太简单的。
|
public class EncodingFilter extends HttpFilter { public void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws IOException, ServletException { String charset = this.getInitParameter("charset"); if(charset == null || charset.isEmpty()) { charset = "UTF-8"; } request.setCharacterEncoding(charset); response.setContentType("text/html;charset=" + charset); chain.doFilter(request, response); } } |
如果是POST请求,当执行目标Servlet时,Servlet中调用request.getParameter()方法时,就会根据request.setCharacterEncoding()设置的编码来转码!这说明在过滤器中调用request.setCharacterEncoding()方法会影响在目标Servlet中的request.getParameter()方法的行为!
但是如果是GET请求,我们又如何能影响request.getParameter()方法的行为呢?这是不好做到的!我们不可能先调用request.getParameter()方法获取参数,然后手动转码后,再施加在到request中!因为request只有getParameter(),而没有setParameter()方法。
处理GET请求参数编码问题,需要在Filter中放行时,把request对象给“调包”了,也就是让目标Servlet使用我们“调包”之后的request对象。这说明我们需要保证“调包”之后的request对象中所有方法都要与“调包”之前一样可以使用,并且getParameter()方法还要有能力返回转码之后的参数。
这可能让你想起了“继承”,但是这里不能用继承,而是“装饰者模式(Decorator Pattern)”!
下面是三种对a对象进行增强的手段:
l 继承:AA类继承a对象的类型:A类,然后重写fun1()方法,其中重写的fun1()方法就是被增强的方法。但是,继承必须要知道a对象的真实类型,然后才能去继承。如果我们不知道a对象的确切类型,而只知道a对象是IA接口的实现类对象,那么就无法使用继承来增强a对象了;
l 装饰者模式:AA类去实现a对象相同的接口:IA接口,还需要给AA类传递a对象,然后在AA类中所有的方法实现都是通过代理a对象的相同方法完成的,只有fun1()方法在代理a对象相同方法的前后添加了一些内容,这就是对fun1()方法进行了增强;
l 动态代理:动态代理与装饰者模式比较相似,而且是通过反射来完成的。动态代理会在最后一天的基础加强中讲解,这里就不再废话了。
对request对象进行增强的条件,刚好符合装饰者模式的特点!因为我们不知道request对象的具体类型,但我们知道request是HttpServletRequest接口的实现类。这说明我们写一个类EncodingRequest,去实现HttpServletRequest接口,然后再把原来的request传递给EncodingRequest类!在EncodingRequest中对HttpServletRequest接口中的所有方法的实现都是通过代理原来的request对象来完成的,只有对getParameter()方法添加了增强代码!
JavaEE已经给我们提供了一个HttpServletRequestWrapper类,它就是HttpServletRequest的包装类,但它做任何的增强!你可能会说,写一个装饰类,但不做增强,其目的是什么呢?使用这个装饰类的对象,和使用原有的request有什么分别呢?
HttpServletRequestWrapper类虽然是HttpServletRequest的装饰类,但它不是用来直接使用的,而是用来让我们去继承的!当我们想写一个装饰类时,还要对所有不需要增强的方法做一次实现是很心烦的事情,但如果你去继承HttpServletRequestWrapper类,那么就只需要重写需要增强的方法即可了。
EncodingRequest
|
public class EncodingRequest extends HttpServletRequestWrapper { private String charset; public EncodingRequest(HttpServletRequest request, String charset) { super(request); this.charset = charset; } public String getParameter(String name) { HttpServletRequest request = (HttpServletRequest) getRequest(); String method = request.getMethod(); if(method.equalsIgnoreCase("post")) { try { request.setCharacterEncoding(charset); } catch (UnsupportedEncodingException e) {} } else if(method.equalsIgnoreCase("get")) { String value = request.getParameter(name); try { value = new String(name.getBytes("ISO-8859-1"), charset); } catch (UnsupportedEncodingException e) { } return value; } return request.getParameter(name); } } |
EncodingFilter
|
public class EncodingFilter extends HttpFilter { public void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws IOException, ServletException { String charset = this.getInitParameter("charset"); if(charset == null || charset.isEmpty()) { charset = "UTF-8"; } response.setCharacterEncoding(charset); response.setContentType("text/html;charset=" + charset); EncodingRequest res = new EncodingRequest(request, charset); chain.doFilter(res, response); } } |
web.xml
|
<filter> <filter-name>EncodingFilter</filter-name> <filter-class>cn.itcast.filter.EncodingFilter</filter-class> <init-param> <param-name>charset</param-name> <param-value>UTF-8</param-value> </init-param> </filter> <filter-mapping> <filter-name>EncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> |
例如网络硬盘!就是用来上传下载文件的。
在智联招聘上填写一个完整的简历还需要上传照片呢。
上传文件的要求比较多,需要记一下:
1. 必须使用表单,而不能是超链接;
2. 表单的method必须是POST,而不能是GET;
3. 表单的enctype必须是multipart/form-data;
4. 在表单中添加file表单字段,即<input type=”file”…/>
|
<form action="${pageContext.request.contextPath }/FileUploadServlet" method="post" enctype="multipart/form-data"> 用户名:<input type="text" name="username"/><br/> 文件1:<input type="file" name="file1"/><br/> 文件2:<input type="file" name="file2"/><br/> <input type="submit" value="提交"/> </form> |
通过httpWatch查看“文件上传表单”和“普通文本表单”的区别。
l 文件上传表单的enctype=”multipart/form-data”,表示多部件表单数据;
l 普通文本表单可以不设置enctype属性:
Ø 当method=”post”时,enctype的默认值为application/x-www-form-urlencoded,表示使用url编码正文;
Ø 当method=”get”时,enctype的默认值为null,没有正文,所以就不需要enctype了。
对普通文本表单的测试:
|
<form action="${pageContext.request.contextPath }/FileUploadServlet" method="post"> 用户名:<input type="text" name="username"/><br/> 文件1:<input type="file" name="file1"/><br/> 文件2:<input type="file" name="file2"/><br/> <input type="submit" value="提交"/> </form> |

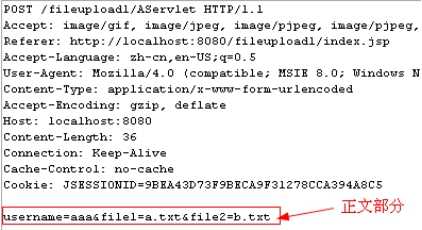
通过httpWatch测试,查看表单的请求数据正文,我们发现请求中只有文件名称,而没有文件内容。也就是说,当表单的enctype不是multipart/form-data时,请求中不包含文件内容,而只有文件的名称,这说明普通文本表单中input:file与input:text没什么区别了。
对文件上传表单的测试:
|
<form action="${pageContext.request.contextPath }/FileUploadServlet" method="post" enctype="multipart/form-data"> 用户名:<input type="text" name="username"/><br/> 文件1:<input type="file" name="file1"/><br/> 文件2:<input type="file" name="file2"/><br/> <input type="submit" value="提交"/> </form> |


通过httpWatch测试,查看表单的请求数据正文部分,发现正文部分是由多个部件组成,每个部件对应一个表单字段,每个部件都有自己的头信息。头信息下面是空行,空行下面是字段的正文部分。多个部件之间使用随机生成的分隔线隔开。
文本字段的头信息中只包含一条头信息,即Content-Disposition,这个头信息的值有两个部分,第一部分是固定的,即form-data,第二部分为字段的名称。在空行后面就是正文部分了,正文部分就是在文本框中填写的内容。
文件字段的头信息中包含两条头信息,Content-Disposition和Content-Type。Content-Disposition中多出一个filename,它指定的是上传的文件名称。而Content-Type指定的是上传文件的类型。文件字段的正文部分就是文件的内容。
请注意,因为我们上传的文件都是普通文本文件,即txt文件,所以在httpWatch中是可以正常显示的,如果上传的是exe、mp3等文件,那么在httpWatch看到的就是乱码了。
当提交的表单是文件上传表单时,那么对Servlet也是有要求的。
首先我们要肯定一点,文件上传表单的数据也是被封装到request对象中的。
request.getParameter(String)方法获取指定的表单字段字符内容,但文件上传表单已经不在是字符内容,而是字节内容,所以失效。
这时可以使用request的getInputStream()方法获取ServletInputStream对象,它是InputStream的子类,这个ServletInputStream对象对应整个表单的正文部分(从第一个分隔线开始,到最后),这说明我们需要的解析流中的数据。当然解析它是很麻烦的一件事情,而Apache已经帮我们提供了解析它的工具:commons-fileupload。
可以尝试把request.getInputStream()这个流中的内容打印出来,再对比httpWatch中的请求数据。
|
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { InputStream in = request.getInputStream(); String s = IOUtils.toString(in); System.out.println(s); } |
|
-----------------------------7ddd3370ab2 Content-Disposition: form-data; name="username" hello -----------------------------7ddd3370ab2 Content-Disposition: form-data; name="file1"; filename="a.txt" Content-Type: text/plain aaa -----------------------------7ddd3370ab2 Content-Disposition: form-data; name="file2"; filename="b.txt" Content-Type: text/plain bbb -----------------------------7ddd3370ab2-- |
为什么使用fileupload:
上传文件的要求比较多,需要记一下:
l 必须是POST表单;
l 表单的enctype必须是multipart/form-data;
l 在表单中添加file表单字段,即<input type=”file”…/>
Servlet的要求:
l 不能再使用request.getParameter()来获取表单数据;
l 可以使用request.getInputStream()得到所有的表单数据,而不是一个表单项的数据;
l 这说明不使用fileupload,我们需要自己来对request.getInputStream()的内容进行解析!!!
fileupload是由apache的commons组件提供的上传组件。它最主要的工作就是帮我们解析request.getInputStream()。
fileupload组件需要的JAR包有:
l commons-fileupload.jar,核心包;
l commons-io.jar,依赖包。
fileupload的核心类有:DiskFileItemFactory、ServletFileUpload、FileItem。
使用fileupload组件的步骤如下:
1. 创建工厂类DiskFileItemFactory对象:DiskFileItemFactory factory = new DiskFileItemFactory()
2. 使用工厂创建解析器对象:ServletFileUpload fileUpload = new ServletFileUpload(factory)
3. 使用解析器来解析request对象:List<FileItem> list = fileUpload.parseRequest(request)
隆重介绍FileItem类,它才是我们最终要的结果。一个FileItem对象对应一个表单项(表单字段)。一个表单中存在文件字段和普通字段,可以使用FileItem类的isFormField()方法来判断表单字段是否为普通字段,如果不是普通字段,那么就是文件字段了。
l String getName():获取文件字段的文件名称;
l String getString():获取字段的内容,如果是文件字段,那么获取的是文件内容,当然上传的文件必须是文本文件;
l String getFieldName():获取字段名称,例如:<input type=”text” name=”username”/>,返回的是username;
l String getContentType():获取上传的文件的类型,例如:text/plain。
l int getSize():获取上传文件的大小;
l boolean isFormField():判断当前表单字段是否为普通文本字段,如果返回false,说明是文件字段;
l InputStream getInputStream():获取上传文件对应的输入流;
l void write(File):把上传的文件保存到指定文件中。
写一个简单的上传示例:
l 表单包含一个用户名字段,以及一个文件字段;
l Servlet保存上传的文件到uploads目录,显示用户名,文件名,文件大小,文件类型。
第一步:
完成index.jsp,只需要一个表单。注意表单必须是post的,而且enctype必须是mulitpart/form-data的。
|
<form action="${pageContext.request.contextPath }/FileUploadServlet" method="post" enctype="multipart/form-data"> 用户名:<input type="text" name="username"/><br/> 文件1:<input type="file" name="file1"/><br/> <input type="submit" value="提交"/> </form> |
第二步:
完成FileUploadServlet
|
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { // 因为要使用response打印,所以设置其编码 response.setContentType("text/html;charset=utf-8"); // 创建工厂 DiskFileItemFactory dfif = new DiskFileItemFactory(); // 使用工厂创建解析器对象 ServletFileUpload fileUpload = new ServletFileUpload(dfif); try { // 使用解析器对象解析request,得到FileItem列表 List<FileItem> list = fileUpload.parseRequest(request); // 遍历所有表单项 for(FileItem fileItem : list) { // 如果当前表单项为普通表单项 if(fileItem.isFormField()) { // 获取当前表单项的字段名称 String fieldName = fileItem.getFieldName(); // 如果当前表单项的字段名为username if(fieldName.equals("username")) { // 打印当前表单项的内容,即用户在username表单项中输入的内容 response.getWriter().print("用户名:" + fileItem.getString() + "<br/>"); } } else {//如果当前表单项不是普通表单项,说明就是文件字段 String name = fileItem.getName();//获取上传文件的名称 // 如果上传的文件名称为空,即没有指定上传文件 if(name == null || name.isEmpty()) { continue; } // 获取真实路径,对应${项目目录}/uploads,当然,这个目录必须存在 String savepath = this.getServletContext().getRealPath("/uploads"); // 通过uploads目录和文件名称来创建File对象 File file = new File(savepath, name); // 把上传文件保存到指定位置 fileItem.write(file); // 打印上传文件的名称 response.getWriter().print("上传文件名:" + name + "<br/>"); // 打印上传文件的大小 response.getWriter().print("上传文件大小:" + fileItem.getSize() + "<br/>"); // 打印上传文件的类型 response.getWriter().print("上传文件类型:" + fileItem.getContentType() + "<br/>"); } } } catch (Exception e) { throw new ServletException(e); } } |
如果没有把用户上传的文件存放到WEB-INF目录下,那么用户就可以通过浏览器直接访问上传的文件,这是非常危险的。
假如说用户上传了一个a.jsp文件,然后用户在通过浏览器去访问这个a.jsp文件,那么就会执行a.jsp中的内容,如果在a.jsp中有如下语句:Runtime.getRuntime().exec(“shutdown –s –t 1”);,那么你就会…
通常我们会在WEB-INF目录下创建一个uploads目录来存放上传的文件,而在Servlet中找到这个目录需要使用ServletContext的getRealPath(String)方法,例如在我的upload1项目中有如下语句:
ServletContext servletContext = this.getServletContext();
String savepath = servletContext.getRealPath(“/WEB-INF/uploads”);
其中savepath为:F:\tomcat6_1\webapps\upload1\WEB-INF\uploads。
上传文件名称可能是完整路径:
IE6获取的上传文件名称是完整路径,而其他浏览器获取的上传文件名称只是文件名称而已。浏览器差异的问题我们还是需要处理一下的。
|
String name = file1FileItem.getName(); response.getWriter().print(name); |
使用不同浏览器测试,其中IE6就会返回上传文件的完整路径,不知道IE6在搞什么,这给我们带来了很大的麻烦,就是需要处理这一问题。
处理这一问题也很简单,无论是否为完整路径,我们都去截取最后一个“\\”后面的内容就可以了。
|
String name = file1FileItem.getName(); int lastIndex = name.lastIndexOf("\\");//获取最后一个“\”的位置 if(lastIndex != -1) {//注意,如果不是完整路径,那么就不会有“\”的存在。 name = name.substring(lastIndex + 1);//获取文件名称 } response.getWriter().print(name); |
上传文件名称中包含中文:
当上传的谁的名称中包含中文时,需要设置编码,commons-fileupload组件为我们提供了两种设置编码的方式:
l request.setCharacterEncoding(String):这种方式是我们最为熟悉的方式了;
l fileUpload.setHeaderEncdoing(String):这种方式的优先级高与前一种。
上传文件的文件内容包含中文:
通常我们不需关心上传文件的内容,因为我们会把上传文件保存到硬盘上!也就是说,文件原来是什么样子,到服务器这边还是什么样子!
但是如果你有这样的需求,非要在控制台显示上传的文件内容,那么你可以使用fileItem.getString(“utf-8”)来处理编码。
文本文件内容和普通表单项内容使用FileItem类的getString(“utf-8”)来处理编码。
通常我们会把用户上传的文件保存到uploads目录下,但如果用户上传了同名文件呢?这会出现覆盖的现象。处理这一问题的手段是使用UUID生成唯一名称,然后再使用“_”连接文件上传的原始名称。
例如用户上传的文件是“我的一寸照片.jpg”,在通过处理后,文件名称为:“891b3881395f4175b969256a3f7b6e10_我的一寸照片.jpg”,这种手段不会使文件丢失扩展名,并且因为UUID的唯一性,上传的文件同名,但在服务器端是不会出现同名问题的。
|
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.setCharacterEncoding("utf-8"); DiskFileItemFactory dfif = new DiskFileItemFactory(); ServletFileUpload fileUpload = new ServletFileUpload(dfif); try { List<FileItem> list = fileUpload.parseRequest(request); //获取第二个表单项,因为第一个表单项是username,第二个才是file表单项 FileItem fileItem = list.get(1); String name = fileItem.getName();//获取文件名称 // 如果客户端使用的是IE6,那么需要从完整路径中获取文件名称 int lastIndex = name.lastIndexOf("\\"); if(lastIndex != -1) { name = name.substring(lastIndex + 1); } // 获取上传文件的保存目录 String savepath = this.getServletContext().getRealPath("/WEB-INF/uploads"); String uuid = CommonUtils.uuid();//生成uuid String filename = uuid + "_" + name;//新的文件名称为uuid + 下划线 + 原始名称 //创建file对象,下面会把上传文件保存到这个file指定的路径 //savepath,即上传文件的保存目录 //filename,文件名称 File file = new File(savepath, filename); // 保存文件 fileItem.write(file); } catch (Exception e) { throw new ServletException(e); } } |
一个目录下不应该存放过多的文件,一般一个目录存放1000个文件就是上限了,如果在多,那么打开目录时就会很“卡”。你可以尝试打印C:\WINDOWS\system32目录,你会感觉到的。
也就是说,我们需要把上传的文件放到不同的目录中。但是也不能为每个上传的文件一个目录,这种方式会导致目录过多。所以我们应该采用某种算法来“打散”!
打散的方法有很多,例如使用日期来打散,每天生成一个目录。也可以使用文件名的首字母来生成目录,相同首字母的文件放到同一目录下。
日期打散算法:如果某一天上传的文件过多,那么也会出现一个目录文件过多的情况;
首字母打散算法:如果文件名是中文的,因为中文过多,所以会导致目录过多的现象。
我们这里使用hash算法来打散:
1. 获取文件名称的hashCode:int hCode = name.hashCode();;
2. 获取hCode的低4位,然后转换成16进制字符;
3. 获取hCode的5~8位,然后转换成16进制字符;
4. 使用这两个16进制的字符生成目录链。例如低4位字符为“5”
这种算法的好处是,在uploads目录下最多生成16个目录,而每个目录下最多再生成16个目录,即256个目录,所有上传的文件都放到这256个目录下。如果每个目录上限为1000个文件,那么一共可以保存256000个文件。
例如上传文件名称为:新建 文本文档.txt,那么把“新建 文本文档.txt”的哈希码获取到,再获取哈希码的低4位,和5~8位。假如低4位为:9,5~8位为1,那么文件的保存路径为uploads/9/1/。
|
int hCode = name.hashCode();//获取文件名的hashCode //获取hCode的低4位,并转换成16进制字符串 String dir1 = Integer.toHexString(hCode & 0xF); //获取hCode的低5~8位,并转换成16进制字符串 String dir2 = Integer.toHexString(hCode >>> 4 & 0xF); //与文件保存目录连接成完整路径 savepath = savepath + "/" + dir1 + "/" + dir2; //因为这个路径可能不存在,所以创建成File对象,再创建目录链,确保目录在保存文件之前已经存在 new File(savepath).mkdirs(); |
限制上传文件的大小很简单,ServletFileUpload类的setFileSizeMax(long)就可以了。参数就是上传文件的上限字节数,例如servletFileUpload.setFileSizeMax(1024*10)表示上限为10KB。
一旦上传的文件超出了上限,那么就会抛出FileUploadBase.FileSizeLimitExceededException异常。我们可以在Servlet中获取这个异常,然后向页面输出“上传的文件超出限制”。
|
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.setCharacterEncoding("utf-8"); DiskFileItemFactory dfif = new DiskFileItemFactory(); ServletFileUpload fileUpload = new ServletFileUpload(dfif); // 设置上传的单个文件的上限为10KB fileUpload.setFileSizeMax(1024 * 10); try { List<FileItem> list = fileUpload.parseRequest(request); //获取第二个表单项,因为第一个表单项是username,第二个才是file表单项 FileItem fileItem = list.get(1); String name = fileItem.getName();//获取文件名称 // 如果客户端使用的是IE6,那么需要从完整路径中获取文件名称 int lastIndex = name.lastIndexOf("\\"); if(lastIndex != -1) { name = name.substring(lastIndex + 1); } // 获取上传文件的保存目录 String savepath = this.getServletContext().getRealPath("/WEB-INF/uploads"); String uuid = CommonUtils.uuid();//生成uuid String filename = uuid + "_" + name;//新的文件名称为uuid + 下划线 + 原始名称 int hCode = name.hashCode();//获取文件名的hashCode //获取hCode的低4位,并转换成16进制字符串 String dir1 = Integer.toHexString(hCode & 0xF); //获取hCode的低5~8位,并转换成16进制字符串 String dir2 = Integer.toHexString(hCode >>> 4 & 0xF); //与文件保存目录连接成完整路径 savepath = savepath + "/" + dir1 + "/" + dir2; //因为这个路径可能不存在,所以创建成File对象,再创建目录链,确保目录在保存文件之前已经存在 new File(savepath).mkdirs(); //创建file对象,下面会把上传文件保存到这个file指定的路径 //savepath,即上传文件的保存目录 //filename,文件名称 File file = new File(savepath, filename); // 保存文件 fileItem.write(file); } catch (Exception e) { // 判断抛出的异常的类型是否为FileUploadBase.FileSizeLimitExceededException // 如果是,说明上传文件时超出了限制。 if(e instanceof FileUploadBase.FileSizeLimitExceededException) { // 在request中保存错误信息 request.setAttribute("msg", "上传失败!上传的文件超出了10KB!"); // 转发到index.jsp页面中!在index.jsp页面中需要使用${msg}来显示错误信息 request.getRequestDispatcher("/index.jsp").forward(request, response); return; } throw new ServletException(e); } } |
上传文件的表单中可能允许上传多个文件,例如:
有时我们需要限制一个请求的大小。也就是说这个请求的最大字节数(所有表单项之和)!实现这一功能也很简单,只需要调用ServletFileUpload类的setSizeMax(long)方法即可。
例如fileUpload.setSizeMax(1024 * 10);,显示整个请求的上限为10KB。当请求大小超出10KB时,ServletFileUpload类的parseRequest()方法会抛出FileUploadBase.SizeLimitExceededException异常。
大家想一想,如果我上传一个蓝光电影,先把电影保存到内存中,然后再通过内存copy到服务器硬盘上,那么你的内存能吃的消么?
所以fileupload组件不可能把文件都保存在内存中,fileupload会判断文件大小是否超出10KB,如果是那么就把文件保存到硬盘上,如果没有超出,那么就保存在内存中。
10KB是fileupload默认的值,我们可以来设置它。
当文件保存到硬盘时,fileupload是把文件保存到系统临时目录,当然你也可以去设置临时目录。
|
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.setCharacterEncoding("utf-8"); DiskFileItemFactory dfif = new DiskFileItemFactory(1024*20, new File("F:\\temp")); ServletFileUpload fileUpload = new ServletFileUpload(dfif); try { List<FileItem> list = fileUpload.parseRequest(request); FileItem fileItem = list.get(1); String name = fileItem.getName(); String savepath = this.getServletContext().getRealPath("/WEB-INF/uploads"); // 保存文件 fileItem.write(path(savepath, name)); } catch (Exception e) { throw new ServletException(e); } } private File path(String savepath, String filename) { // 从完整路径中获取文件名称 int lastIndex = filename.lastIndexOf("\\"); if(lastIndex != -1) { filename = filename.substring(lastIndex + 1); } // 通过文件名称生成一级、二级目录 int hCode = filename.hashCode(); String dir1 = Integer.toHexString(hCode & 0xF); String dir2 = Integer.toHexString(hCode >>> 4 & 0xF); savepath = savepath + "/" + dir1 + "/" + dir2; // 创建目录 new File(savepath).mkdirs(); // 给文件名称添加uuid前缀 String uuid = CommonUtils.uuid(); filename = uuid + "_" + filename; // 创建文件完成路径 return new File(savepath, filename); } |
被下载的资源必须放到WEB-INF目录下(只要用户不能通过浏览器直接访问就OK),然后通过Servlet完成下载。
在jsp页面中给出超链接,链接到DownloadServlet,并提供要下载的文件名称。然后DownloadServlet获取文件的真实路径,然后把文件写入到response.getOutputStream()流中。
download.jsp
|
<body> This is my JSP page. <br> <a href="<c:url value=‘/DownloadServlet?path=a.avi‘/>">a.avi</a><br/> <a href="<c:url value=‘/DownloadServlet?path=a.jpg‘/>">a.jpg</a><br/> <a href="<c:url value=‘/DownloadServlet?path=a.txt‘/>">a.txt</a><br/> </body> |
DownloadServlet.java
|
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String filename = request.getParameter("path"); String filepath = this.getServletContext().getRealPath("/WEB-INF/uploads/" + filename); File file = new File(filepath); if(!file.exists()) { response.getWriter().print("您要下载的文件不存在!"); return; } IOUtils.copy(new FileInputStream(file), response.getOutputStream()); } |
上面代码有如下问题:
l 可以下载a.avi,但在下载框中的文件名称是DownloadServlet;
l 不能下载a.jpg和a.txt,而是在页面中显示它们。
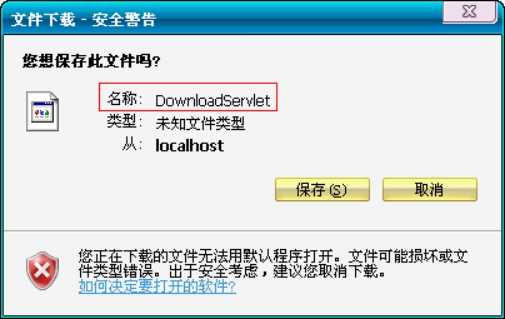
下面来处理上一例中的问题,让下载框中可以显示正确的文件名称,以及可以下载a.jpg和a.txt文件。
通过添加content-disposition头来处理上面问题。当设置了content-disposition头后,浏览器就会弹出下载框。
而且还可以通过content-disposition头来指定下载文件的名称!
|
String filename = request.getParameter("path"); String filepath = this.getServletContext().getRealPath("/WEB-INF/uploads/" + filename); File file = new File(filepath); if(!file.exists()) { response.getWriter().print("您要下载的文件不存在!"); return; } response.addHeader("content-disposition", "attachment;filename=" + filename); IOUtils.copy(new FileInputStream(file), response.getOutputStream()); |
虽然上面的代码已经可以处理txt和jpg等文件的下载问题,并且也处理了在下载框中显示文件名称的问题,但是如果下载的文件名称是中文的,那么还是不行的。
下面是处理在下载框中显示中文的问题!
其实这一问题很简单,只需要通过URL来编码中文即可!
download.jsp
|
<a href="<c:url value=‘/DownloadServlet?path=这个杀手不太冷.avi‘/>">这个杀手不太冷.avi</a><br/> <a href="<c:url value=‘/DownloadServlet?path=白冰.jpg‘/>">白冰.jpg</a><br/> <a href="<c:url value=‘/DownloadServlet?path=说明文档.txt‘/>">说明文档.txt</a><br/> |
DownloadServlet.java
|
String filename = request.getParameter("path"); // GET请求中,参数中包含中文需要自己动手来转换。 // 当然如果你使用了“全局编码过滤器”,那么这里就不用处理了 filename = new String(filename.getBytes("ISO-8859-1"), "UTF-8"); String filepath = this.getServletContext().getRealPath("/WEB-INF/uploads/" + filename); File file = new File(filepath); if(!file.exists()) { response.getWriter().print("您要下载的文件不存在!"); return; } // 所有浏览器都会使用本地编码,即中文操作系统使用GBK // 浏览器收到这个文件名后,会使用iso-8859-1来解码 filename = new String(filename.getBytes("GBK"), "ISO-8859-1"); response.addHeader("content-disposition", "attachment;filename=" + filename); IOUtils.copy(new FileInputStream(file), response.getOutputStream()); |
今日内容
l 邮件协议
l telnet访问邮件服务器
l JavaMail
发邮件大家都会吧!发邮件是从客户端把邮件发送到邮件服务器,收邮件是把邮件服务器的邮件下载到客户端。
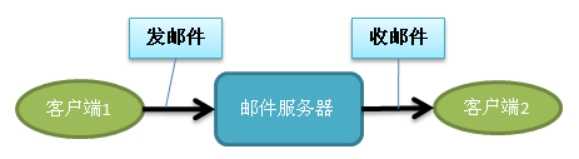
我们在163、126、QQ、sohu、sina等网站注册的Email账户,其实就是在邮件服务器中注册的。这些网站都有自己的邮件服务器。
与HTTP协议相同,收发邮件也是需要有传输协议的。
l SMTP:(Simple Mail Transfer Protocol,简单邮件传输协议)发邮件协议;
l POP3:(Post Office Protocol Version 3,邮局协议第3版)收邮件协议;
l IMAP:(Internet Message Access Protocol,因特网消息访问协议)收发邮件协议,我们的课程不涉及该协议。
其实你可以把邮件服务器理解为邮局!如果你需要给朋友寄一封信,那么你需要把信放到邮筒中,这样你的信会“自动”到达邮局,邮局会把信邮到另一个省市的邮局中。然后这封信会被送到收信人的邮箱中。最终收信人需要自己经常查看邮箱是否有新的信件。
其实每个邮件服务器都由SMTP服务器和POP3服务器构成,其中SMTP服务器负责发邮件的请求,而POP3负责收邮件的请求。
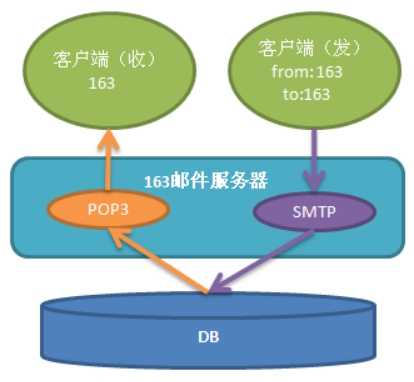
当然,有时我们也会使用163的账号,向126的账号发送邮件。这时邮件是发送到126的邮件服务器,而对于163的邮件服务器是不会存储这封邮件的。
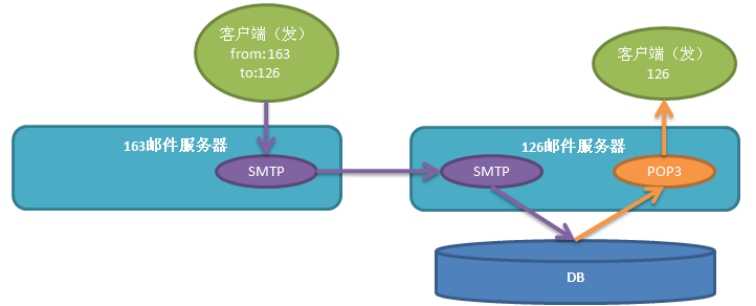
smtp服务器的端口号为25,服务器名称为smtp.xxx.xxx。
pop3服务器的端口号为110,服务器名称为pop3.xxx.xxx。
例如:
l 163:smtp.163.com和pop3.163.com;
l 126:smtp.126.com和pop3.126.com;
l qq:smtp.qq.com和pop3.qq.com;
l sohu:smtp.sohu.com和pop3.sohu.com;
l sina:smtp.sina.com和pop3.sina.com。
BASE64是一种加密算法,这种加密方式是可逆的!它的作用是使加密后的文本无法用肉眼识别。Java提供了sun.misc.BASE64Encoder这个类,用来对做Base64的加密和解密,但我们知道,使用sun包下的东西会有警告!甚至在eclipse中根本使用不了这个类(需要设置),所以我们还是听sun公司的话,不要去使用它内部使用的类,我们去使用apache commons组件中的codec包下的Base64这个类来完成BASE64加密和解密。
|
package cn.itcast; import org.apache.commons.codec.binary.Base64; public class Base64Utils { public static String encode(String s) { return encode(s, "utf-8"); } public static String decode(String s) { return decode(s, "utf-8"); } public static String encode(String s, String charset) { try { byte[] bytes = s.getBytes(charset); bytes = Base64.encodeBase64(bytes); return new String(bytes, charset); } catch (Exception e) { throw new RuntimeException(e); } } public static String decode(String s, String charset) { try { byte[] bytes = s.getBytes(charset); bytes = Base64.decodeBase64(bytes); return new String(bytes, charset); } catch (Exception e) { throw new RuntimeException(e); } } } |
连接163的smtp服务器:![]() ;
;
连接成功后需要如下步骤才能发送邮件:
1 与服务器打招呼:ehlo你的名字

2 发出登录请求:auth login
![]()
3 输入加密后的邮箱名:(itcast_cxf@163.com)aXRjYXN0X2N4ZkAxNjMuY29t
4 输入加密后的邮箱密码:(itcast)aXRjYXN0
5 输入谁来发送邮件,即from:mail from:<itcast_cxf@163.com>
![]()
6 输入把邮件发给谁,即to:rcpt to:<itcast_cxf@126.com>
![]()
7 发送填写数据请求:data
![]()
8 开始输入数据,数据包含:from、to、subject,以及邮件内容,如果输入结束后,以一个“.”为一行,表示输入结束:
from:<zhangBoZhi@163.com>
to:<itcast_cxf@sina.com>
subject: 我爱上你了
我已经深深的爱上你了,我是张柏芝。
.
注意,在标题和邮件正文之间要有一个空行!当要退出时,一定要以一个“.”为单行,表示输入结束。
9 最后一步:quit

pop3无需使用Base64加密!!!
收邮件连接的服务器是pop3.xxx.com,pop3协议的默认端口号是110。请注意!这与发邮件完全不同。如果你在163有邮箱账户,那么你想使用telnet收邮件,需要连接的服务器是pop3.163.com。
l 连接pop3服务器:telnet pop3.163.com 110
l user命令:user 用户名,例如:user itcast_cxf@163.com;
l pass命令:pass 密码,例如:pass itcast;
l stat命令:stat命令用来查看邮箱中邮件的个数,所有邮件所占的空间;
l list命令:list命令用来查看所有邮件,或指定邮件的状态,例如:list 1是查看第一封邮件的大小,list是查看邮件列表,即列出所有邮件的编号,及大小;
l retr命令:查看指定邮件的内容,例如:retr 1#是查看第一封邮件的内容;
l dele命令:标记某邮件为删除,但不是马上删除,而是在退出时才会真正删除;
l quit命令:退出!如果在退出之前已经使用dele命令标记了某些邮件,那么会在退出是删除它们。
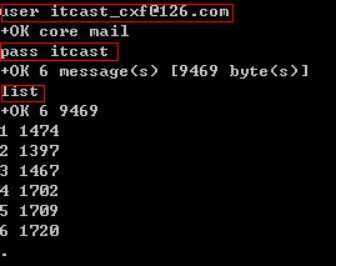
![]()
Java Mail是由SUN公司提供的专门针对邮件的API,主要Jar包:mail.jar、activation.jar。
在使用MyEclipse创建web项目时,需要小心!如果只是在web项目中使用java mail是没有什么问题的,发布到Tomcat上运行一点问题都没有!
但是如果是在web项目中写测试那就出问题了。
在MyEclipse中,会自动给web项目导入javax.mail包中的类,但是不全(其实是只有接口,而没有接口的实现类),所以只靠MyEclipse中的类是不能运行java mail项目的,但是如果这时你再去自行导入mail.jar时,就会出现冲突。
处理方案:到下面路径中找到javaee.jar文件,把javax.mail删除!!!
D:\Program Files\MyEclipse\Common\plugins\com.genuitec.eclipse.j2eedt.core_10.0.0.me201110301321\data\libraryset\EE_5
java mail中主要类:javax.mail.Session、javax.mail.internet.MimeMessage、javax.mail.Transport。
Session:表示会话,即客户端与邮件服务器之间的会话!想获得会话需要给出账户和密码,当然还要给出服务器名称。在邮件服务中的Session对象,就相当于连接数据库时的Connection对象。
MimeMessage:表示邮件类,它是Message的子类。它包含邮件的主题(标题)、内容,收件人地址、发件人地址,还可以设置抄送和暗送,甚至还可以设置附件。
Transport:用来发送邮件。它是发送器!
在使用telnet发邮件时,还需要自己来处理Base64编码的问题,但使用JavaMail就不必理会这些问题了,都由JavaMail来处理。
第一步:获得Session
Session session = Session.getInstance(Properties prop, Authenticator auth);
其中prop需要指定两个键值,一个是指定服务器主机名,另一个是指定是否需要认证!我们当然需要认证!
Properties prop = new Properties();
prop.setProperty(“mail.host”, “smtp.163.com”);//设置服务器主机名
prop.setProperty(“mail.smtp.auth”, “true”);//设置需要认证
其中Authenticator是一个接口表示认证器,即校验客户端的身份。我们需要自己来实现这个接口,实现这个接口需要使用账户和密码。
Authenticator auth = new Authenticator() {
public PasswordAuthentication getPasswordAuthentication () {
new PasswordAuthentication(“itcast_cxf”, “itcast”);//用户名和密码
}
};
通过上面的准备,现在可以获取得Session对象了:
Session session = Session.getInstance(prop, auth);
第二步:创建MimeMessage对象
创建MimeMessage需要使用Session对象来创建:
MimeMessage msg = new MimeMessage(session);
然后需要设置发信人地址、收信人地址、主题,以及邮件正文。
msg.setFrom(new InternetAddress(“itcast_cxf@163.com”));//设置发信人
msg.addRecipients(RecipientType.TO, “itcast_cxf@qq.com,itcast_cxf@sina.com”);//设置多个收信人
msg.addRecipients(RecipientType.CC, “itcast_cxf@sohu.com,itcast_cxf@126.com”);//设置多个抄送
msg.addRecipients(RecipientType.BCC, ”itcast_cxf@hotmail.com”);//设置暗送
msg.setSubject(“这是一封测试邮件”);//设置主题(标题)
msg.setContent(“当然是hello world!”, “text/plain;charset=utf-8”);//设置正文
第三步:发送邮件
Transport.send(msg);//发送邮件
一封邮件可以包含正文、附件N个,所以正文与N个附件都是邮件的一个部份。
上面的hello world案例中,只是发送了带有正文的邮件!所以在调用setContent()方法时直接设置了正文,如果想发送带有附件邮件,那么需要设置邮件的内容为MimeMultiPart。
MimeMulitpart parts = new MimeMulitpart();//多部件对象,可以理解为是部件的集合
msg.setContent(parts);//设置邮件的内容为多部件内容。
然后我们需要把正文、N个附件创建为“主体部件”对象(MimeBodyPart),添加到MimeMuiltPart中即可。
MimeBodyPart part1 = new MimeBodyPart();//创建一个部件
part1.setCotnent(“这是正文部分”, “text/html;charset=utf-8”);//给部件设置内容
parts.addBodyPart(part1);//把部件添加到部件集中。
下面我们创建一个附件:
MimeBodyPart part2 = new MimeBodyPart();//创建一个部件
part2.attachFile(“F:\\a.jpg”);//设置附件
part2.setFileName(“hello.jpg”);//设置附件名称
parts.addBodyPart(part2);//把附件添加到部件集中
注意,如果在设置文件名称时,文件名称中包含了中文的话,那么需要使用MimeUitlity类来给中文编码:
part2.setFileName(MimeUitlity.encodeText(“美女.jpg”));
标签:
原文地址:http://www.cnblogs.com/wang-meng/p/5702051.html
