标签:
本文根据DBAplus社群第67期线上分享整理而成
本次分享主要包括以下内容:
1、MySQL高可用方案
2、为什么选择MHA
3、读写分离方案的寻找以及为什么选择Maxscale
一、MySQL Failover的方案
常见的Failover方案
MMM
MMM缺点:
Monitor节点是单点,可以结合Keepalived实现高可用目前MySQL Failover 的方案
Keepalived会有脑裂的风险
在读写繁忙的业务中可能丢数据
MHA + ssh -o 测试心跳 + masterMHA_secondary_check(两次检测)
MHA
MHA优点:
从宕机崩溃的Master保存二进制日志事件(binlogevent)
识别含有最新更新的Slave
应用差异的中继日志(relaylog)到其他Slave
应用从Master保存的二进制日志事件
提升一个Slave为新的Master
使其他的Slave连接新的Master进行复制
MariaDB Replication Manager (MRM)
只支持MariaDB with GTID based replication topologies
二、MHA
今天主要说下MHA。MHA可以说是强一致的主从切换工具 ,而且切换间隔小于30s,非常适合在线上使用。
具体原理
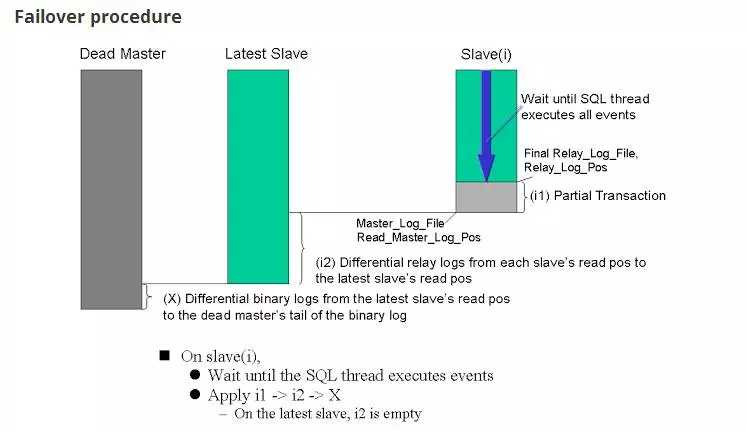
从宕机崩溃的Master保存二进制日志事件(binlogevent)
识别含有最新更新的Slave
应用差异的中继日志(relaylog)到其他Slave
应用从Master保存的二进制日志事件
提升一个Slave为新的Master
使其他的Slave连接新的Master进行复制
MHA组成
rpm -ql MHA4MySQL-manager-0.56-0.el6.noarch
1、管理节点

2、数据节点

3、MySQL的配置要点
安装配置MHA
1)MySQL主从
MySQL一主两从(一个candidate_master)
master:
slave:
MySQL主从搭建 (一主两从)
1)MySQL主从配置
创建用户

备份
MySQLdump --master-data=2 --single-transaction -A > bk.sql (我们生产上不允许使用函数和存储过程)
Tips:如果不是新建db,建议使用mydumper(slave)或者innobackupex(master) 备份
从库执行
a.将bk.sql 在从库恢复
b.执行
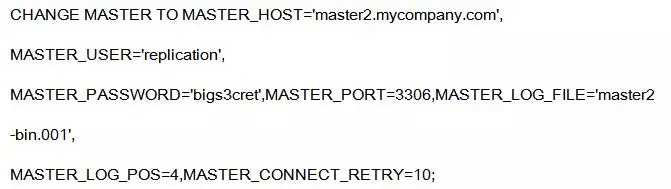
c.如果开启GTID

Tips:
1、降低数据丢失风险
innodb_flush_log_at_trx_commit=1
innodb_support_xa=1
sync_binlog =1
gtid
半同步复制或者5.7的增强半同步
binlog_format 为RBR
2、主从一致检测
pt-table-checksum
pt-table-sync
pt-online-schema-change 虽然5.6 支持ddl online ,我还是建议使用pt-osc ,但是注意:如果binlog_format为SBR , 使用pt-osc 会有主键冲突的风险
4、MHA配置
1)ssh 配置
ansible 来做
2)安装MHA
yum install -y --nogpgcheck MHA4MySQL-*(已经下载好了) 在每个节点都执行
3)编辑文件


4)清理relay log
slave上的relay_log_purge是关闭的,在MHA环境中,failover时,会用到relay log来对比差异日志,将差异日志发送到其他slave上,进行回放

5、MHA环境监测
检查MHA环境

启动MHA manager

6、MHA切换测试
1)模拟实例cresh
/etc/init.d/MySQL stop
2)模拟主机cresh
echo a > /proc/sysrq-trigger
3)使用iptables
iptables -A INPUT -p tcp -m iprange --src-range 192.168.10.1-192.168.10.241 --d port 3306 -j DROP
PS.可以在master节点跑sysbench,在压测的过程中来做以上测试
Tips:
MHA默认没有arping,这个要自己加上,否则服务器会自动等到vip缓存失效,期间VIP会有一定时间的不可用
masterha_manager 命令行中加入--ignore_last_failover 否则再次切换会失败,除非删除app1.failover.complete文件
vip 我们没有使用keepalive,是在两个主机上插网线, 如eth1,将vip加到 master 的eth1上
要将备主的对应网卡激活
report_script=/usr/bin/send_report 发邮件的功能要加上
slave不要延迟过长,延迟越久,切换也越久
secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.10.100 -s 192.168.10.101 --user=root --master_host=maven119 --master_ip=192.168.10.88 --master_port=3306 这样只有当两个manager都ping不通才会切换,防止数据不一致(注意修改masterha_secondary_check 中ssh的端口号,他是写死的22)
grep -i ‘change master‘ manager.log 可以找到change master to 语句 ,可以在切换后旧的主库上执行
设置 ignore_fail = 1 这样即使slave 有错误,也会切换
设置ssh 的 timeout 防止ssh连接慢时,MHA发生切换
7、MHA manager 管理多实例

这样就完成多实例的部署。
Tips:
如果觉得MHA部署麻烦,还要自己写脚本,可以使用MHA_helper
web:https://github.com/ovaistariq/MHA-helper
SQL-aware负载均衡器:
MySQL proxy:官方不维护了
MySQL Router:官方维护,比较简单
MaxScale:插件式,定制灵活,自动检测MySQL master failure
Amoeba:支持sql过滤,读写分离,sharding,不支持 MySQL Failover
Cobar:支持分库,不支持分表
MyCat:基于Cobar的二次开发
TDDL(Taobao Distributed Data Layer):阿里自研的基于client模式的读写分离的中间件
三、Maxscale
这里想要介绍的是Maxscale。
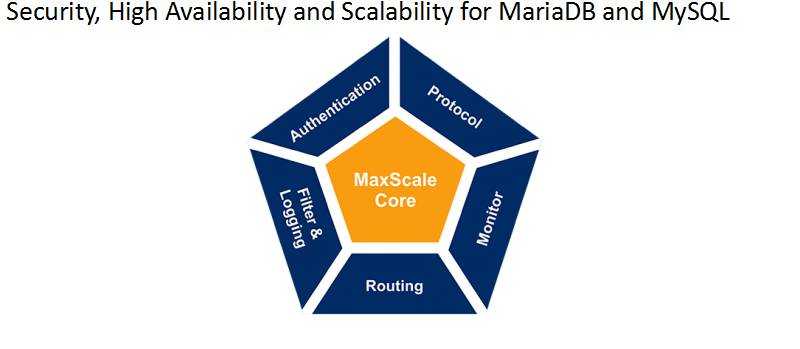
Maxscale有哪些优点呢,一句话,上面这些中间件有的优点,它基本都有。
带权重的读写分离(负载均衡)
SQL防火墙
多种路由策略(Connection based, Statement based,Schema based)
自动检测MySQL master Failover (配合MHA或者MRM)
检测主从延时
多租户sharding架构
架构比较
大多数互联网公司的db架构
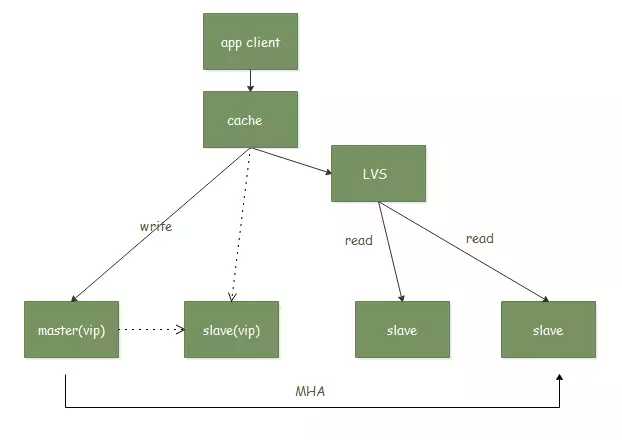
隐患:一般的互联网公司会使用MHA做Failover , 然后使用LVS在读库上做负载均衡,但是LVS走的TCP协议,当read 库挂掉,LVS也不会将其踢掉,另外LVS对长连接的应用支持的不好, 因为由于LVS的检查时长一般在30s, 但是长连接的设置一般都是30分钟,或者不设置timwout,这样,当业务端 断开连接后,LVS还认为它会死活着的, 所以 连接到db的thread却并不减少。造成thead_connected 打满,MySQL不可用。
使用Maxscale的db层架构
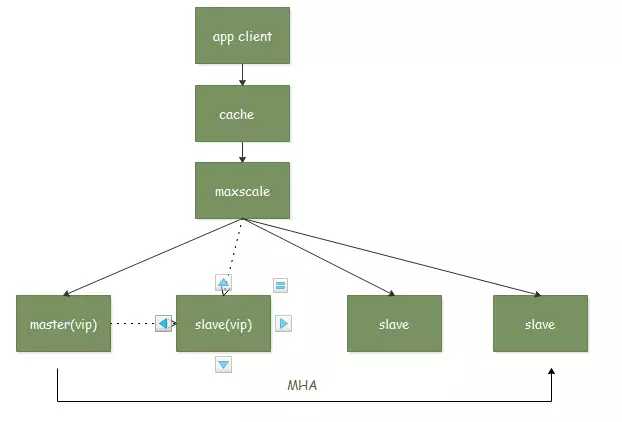
规避了使用LVS时候的长链接超时不断开问题。
Maxscale配置很简单
yum -y install Maxscale (只在Maxscale上执行)
cp MaxScale_template.cnf Maxscale.cnf
生成密码:
maxkeys /var/lib/maxscale/
maxpasswd /var/lib/maxscale/ maven119
修改配置文件
需要的单独找我吧,太长了配置文件……
通过管理命令,查看状态

可以看到目前有两台db,以及运行状态
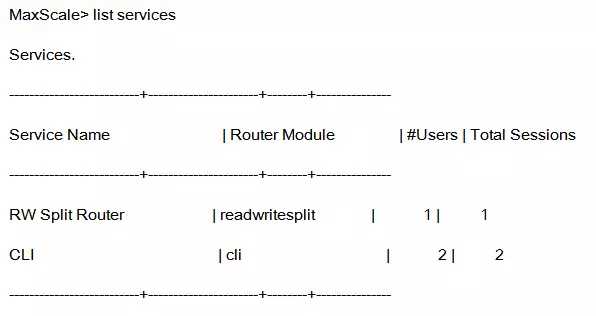
看到开启了什么服务读写分离和client
下面来做一下结单的测试:
MySQL master节点:

4 rows in set (0.00 sec)
MySQL slave节点,多增加一条记录。

发现读打在了从库。
如果想让读搭载主库上 ,可以把select语句放到事务中。

具体的读写情况可以使用general_log观察。
在 master 节点执行 :
set global general_log=1;
在Maxscale节点执行 :

发现写打在了主库上。

Tips:
如果想要在master上读
可以把select语句放到事务中begin;select;commit
Maxscale会对每个slave做健康检查,原理与pt-heartbeat一样的。主库插入时间戳,到slave与serevr时间对比。
gnoring secrets file /var/lib/maxscale/.secrets, invalid permissions .secrets的权限不对 chown maxscale:maxscale .secrets
Maxscale 1.4版本做了很多的改进
重要概念DCB

从这种图中可以看出来DCB的重要性了,callback 最后走到了 dcb.h
那么什么是DCB呢?
一个DCB(Descriptor Control Block)表示一个在MaxScale内部的连接的状态,每个来自client的连接、到后端server的连接、以及每个listener都会被分配一个DCB,这些连接的状态统计由这些DCB来完成。每个DCB并不会有特定的名字用于查询,而是直接使用具有唯一性的内存地址。
Maxscale的MHA
官方推荐使用Lsyncd或者Corosync-Pacemaker。
个人认为Maxscale的一些想法是不错的,包括Percona也生成Maxscale是目前最好的读写分离中间件。目前还不是很成熟,小项目可以试试。大型项目还是推荐TDDL这种经过生产实践的中间件。
Maxscale与MHA整合
Maxscale与MHA整合其实非常简单,一般MHA都会让 开发使用vip。master宕掉后,slave接管,对前端是透明的。
在与Maxscale结合的时候,Maxscale.conf文件不需要改变任何东西,只需要在后端将MHA部署上就可以。因Maxscale可以监控MySQL的主从变更。
总结:Maxscale与MHA整合,只需要安装MHA即可。
写在最后,对已有的MySQL主从环境上MHA和Maxscale几乎不需要更改任何配置。只需要更改开发框架中的配置 ,把原IP和端口改写为Maxscale server的IP和端口即可。
Q&A
Q1:请问,这个10.10.111.1是部署Maxscale服务器的物理IP吗,部署Maxscale的服务器是不是也需要两台服务器做HA?就一台服务器的话要是意外宕机岂不是会导致整个应用瘫痪?还是说我理解错了?
A1:官方推荐使用Lsyncd或者Corosync-Pacemaker做Maxscale的HA。
Q2:监控系统是自主研发的还是采用开源的?都是以哪些为监控指标来监控性能和稳定性的?
A2:pt-heartbeat来实时监控主从状态,pt-heartbeat可以一秒。
Q3:一直不明白挺好的东西为啥不用,非要主从之间切来切去?
A3:可能场景不同,我们一般都会有4台db做Master-slave,主要是需要扩容读库。优酷基本上是读大于写。
Q4:slave-skip-errors = 1062,1032,1060这类配置你们用吗?
A4:用。但是1062,1032这两个不能配。
好书相送
在本文微信评论区留下足以引起共鸣的真知灼见,
优酷土豆资深工程师:MySQL高可用之MaxScale与MHA
标签:
原文地址:http://www.cnblogs.com/zengkefu/p/5720831.html