标签:
本文主要记录《Machine Learning In Action》中第二章的内容。书中以两个具体实例来介绍kNN(k nearest neighbors),分别是:
通过“约会对象”功能,基本能够了解到kNN算法的工作原理。“手写数字识别”与“约会对象预测”使用完全一样的算法代码,仅仅是数据集有变化。
主人公“张三”喜欢结交新朋友。“系统A”上面注册了很多类似于“张三”的用户,大家都想结交心朋友。“张三”最开始通过自己筛选的方式在“系统A”上面挑选感觉不错的人,然后约出来吃饭,但结果不总是如“张三”所愿,他自己筛选出来的对象中,有些是真的跟他志趣相投,而有些则完全跟他不是一路人。“张三”希望“系统A”能自动给他推荐一些跟他志趣相投的朋友,提高他能约到“志趣相投”的朋友的概率。
系统不能凭空为“张三”推荐朋友,必须拿一些“已有东西”作为依据和参考。这个“已有”的东西就是“张三”约会的历史纪录。
每次约会的对象,使用三个属性来标记:
相当于使用这三个属性,代表一个人。不同的人,三个属性值各不相同。使用向量[feature1, feature2, feature3]来表示一个约会对象。约会的结果,有三种可能:不满意,还可以,很满意。使用class来表示约会结果。这样一来,每条历史约会纪录可以表示为向量[feature1, feature2, feature3, class],其中:
目前为止,“张三”有很多条类似于[feature1, feature2, feature3, class]这样的约会纪录,系统要实现的功能就是:对于一个“张三”没有约会过的对象[feature1, feature2, feature3],结合张三的历史约会纪录[feature1, feature2, feature3, class],系统预测一个约会结果,如果预测结果是“很满意”,就可以将这个“陌生人”推荐给“张三”。
明确了需求,就可以使用machine learning的大致套路来实现。
拿到“张三”的历史约会数据[feature1, feature2, feature3, class]。《Machine Learning In Action》的作者已经为我们准备好了数据,git地址:
https://github.com/pbharrin/machinelearninginaction/tree/master/Ch02
datingTestSet.txt和datingTestSet2.txt就是数据文件。主要区别是,两个数据文件中,对约会结果的表示形式不同。datingTestSet.txt中使用字符串,datingTestSet2.txt中使用数字,本质上是一样的。例如在datingTestSet2.txt中,数据为:
9868 2.694977 0.432818 2 18333 3.951256 0.333300 2 3780 9.856183 0.329181 2 18190 2.068962 0.429927 2 11145 3.410627 0.631838 2 68846 9.974715 0.669787 1 26575 10.650102 0.866627 3 48111 9.134528 0.728045 3 43757 7.882601 1.332446 3
有了数据,需要把数据都到计算机程序里面,才能继续处理
将文件转换为程序需要的数据结构:
def file2matrix(filename): fr = open(filename) numberOfLines = len(fr.readlines()) returnMat = zeros((numberOfLines, 3)) classLabelVector = [] fr = open(filename) index = 0 for line in fr.readlines(): line = line.strip() listFromLine = line.split(‘\t‘) returnMat[index, :] = listFromLine[0:3] classLabelVector.append(int(listFromLine[-1])) index += 1 return returnMat, classLabelVector
里面使用了numpy的Array来保存数据
文件的前三列,每列数据对应一个属性,而属性的取值范围各不相同,这将导致后面计算“距离”的时候,取值范围大的属性,对结果影响度较大。假设所有属性的重要性是相同的,因此需要对属性进行归一化处理。代码如下:
def autoNorm(dataSet): minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals normDataSet = zeros(shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - tile(minVals, (m, 1)) normDataSet = normDataSet / tile(ranges, (m, 1)) return normDataSet, ranges, minVals
书中没有讲到当各个属性的重要性不同时,该如果处理,感觉可以在这步,返回normDataSet之前,乘以一个系数来代表影响因子。
这步主要通过pyplot将数据画出来,通过图形,可以对数据有一个直观的感觉,可以大致判断最开始选择的三个feature跟class之间是否有一定的规律性的联系。画图的代码:
def plotDatingData(): datingDataMat, datingLabels = file2matrix("datingTestSet2.txt") normMat, ranges, minVals = autoNorm(datingDataMat) datingDataMat = normMat fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15.0*array(datingLabels), 10.0*array(datingLabels)) plt.xlabel("Flyier Miles Earned Per Year") plt.ylabel("Time Spend Playing Video Games") plt.title("Dating History") plt.legend() plt.show()
效果图:
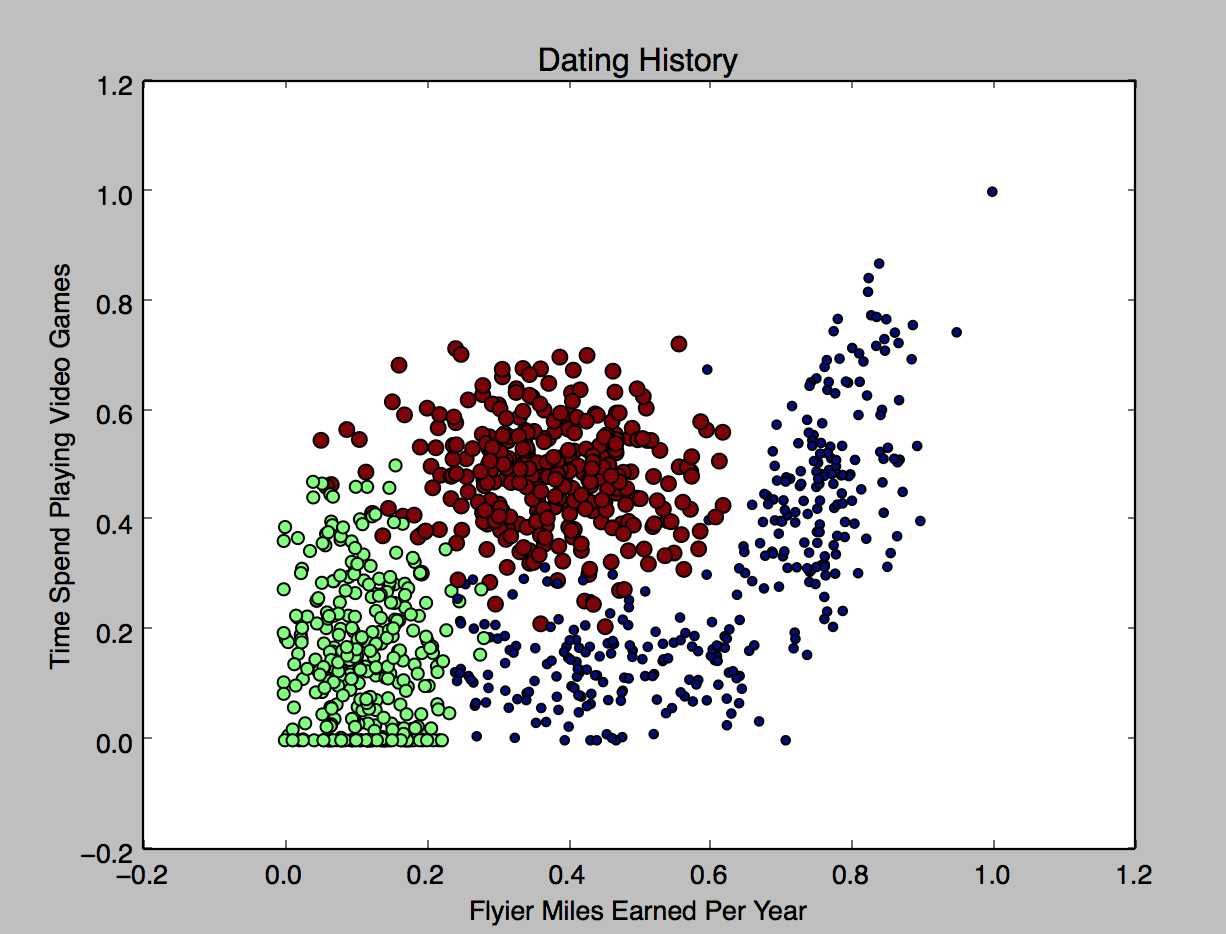
上面代码只使用了“飞行里程数”和“打游戏的时间”两个feature。其中:
从图中可以看出,3个结果都有一个大致的分配区域,说明可以使用这两个feature来做预测。
对于给定的一个向量,与已有数据集中的所有向量计算“向量距离”,距离越近,表示两个向量越相似。从已有数据集中,找出与给定向量距离最近的前k个向量。这前k个向量,每个都对应一个结果class,采用少数服从多数的方式,出现次数最多的class,就是预测的结果class。
代码如下:
def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] diffMat = tile(inX, (dataSetSize, 1)) - dataSet sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() classCount = {} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 sortedClassCount = sorted( classCount.iteritems(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0]
上面使用的“约会历史数据”,相当于训练数据。基于训练数据集,产生了上面的预测方法。检测这个预测方法到底好不好,可以使用“历史数据”中的前10%作为测试数据集,只使用后90%作为训练数据集。用测试数据集中的数据,在上面的预测方法中跑出结果后,跟实际的结果进行比较,如果一样,就说明预测对了,否则,说明预测错误。最后可以得出一个错误率,错误率越低,说明预测方法越好。代码如下:
def datingClassTest(): hoRatio = 0.10 datingDataMat, datingLabels = file2matrix("datingTestSet2.txt") normMat, ranges, minVals = autoNorm(datingDataMat) m = normMat.shape[0] numTestVecs = int(m * hoRatio) errorCount = 0.0 for i in range(numTestVecs): classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3) print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]) if (classifierResult != datingLabels[i]): errorCount += 1.0 print "the total error rate is: %f" % (errorCount / float(numTestVecs))
到现在为止,就可以使用上面完成的预测方法进行“约会对象预测”了。代码如下:
def classifyPerson(): resultMap = { 1: ‘not at all‘, 2: ‘in small doses‘, 3: ‘in large doses‘ } flierMiles = float(raw_input("flier miles earned per year?")) playGameTime = float(raw_input("time spent playing video games?")) iceCream = float(raw_input("liters of ice cream consumed per year?")) datingDataMat, datingLabels = file2matrix(‘datingTestSet2.txt‘) normMat, ranges, minVals = autoNorm(datingDataMat) inAttr = array([flierMiles, playGameTime, iceCream]) classifierResult = classify0((inAttr - minVals) / ranges, normMat, datingLabels, 3) print "You will probably like this person: ", resultMap[classifierResult]
这个例子与“约会对象预测”本质上是一样的,仅仅是数据集不同。数据集位于zip打包文件中,git地址:
https://github.com/pbharrin/machinelearninginaction/tree/master/Ch02
代码:
def img2vector(filename): returnVect = zeros((1, 1024)) fr = open(filename) for i in range(32): lineStr = fr.readline() for j in range(32): returnVect[0, i*32 + j] = int(lineStr[j]) return returnVect
代码:
def handwritingClassTest(): hwLabels = [] trainingFileList = os.listdir("trainingDigits") m = len(trainingFileList) trainingMat = zeros((m, 1024)) for i in range(m): fileNameStr = trainingFileList[i] fileStr = fileNameStr.split(".")[0] classNumStr = int(fileStr.split(‘_‘)[0]) hwLabels.append(classNumStr) trainingMat[i, :] = img2vector(os.path.join("trainingDigits", fileNameStr)) testFileList = os.listdir("testDigits") errorCount = 0.0 mTest = len(testFileList) for i in range(mTest): fileNameStr = testFileList[i] fileStr = fileNameStr.split(".")[0] classNumStr = int(fileStr.split("_")[0]) vectorUnderTest = img2vector(os.path.join("testDigits", testFileList[i])) classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3) print "the classifier came back with: %d, the real anwser is: %d" % (classifierResult, classNumStr) if (classifierResult != classNumStr): errorCount += 1.0 print "\nthe total number of errors is: %d" % errorCount print "\nthe total error rate is: %f" % (errorCount / float(mTest))
原理简单,很好理解。
从以上两个例子的运行结果来看,错误率很低,说明此方法很实用
将所有数据加载到内存数据结构中,数据量很大的时候,是否合适?
单次预测的时候,需要对每条数据向量计算一次距离,然后挑选出前k个,计算量太大
预测实用的特征feature该如何选取,靠经验,还是想象力?在现实的系统中是如何选feature的?希望有经验的读者能不吝解惑。
Machine Learning In Action 第二章学习笔记: kNN算法
标签:
原文地址:http://www.cnblogs.com/zc9527/p/5721943.html