标签:
RDD的缓存
Spark速度非常快的原因之一,就是在不同操作中在内存中持久化(或缓存)一个数据集。当持久化一个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此数据集(或者衍生出的数据集)进行的其他动作(action)中重用。这使得后续的动作变得更加迅速(通常快10倍)。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
通过persist()或cache()方法可以标记一个要被持久化的RDD,一旦首次被触发,该RDD将会被保留在计算节点的内存中并重用。实际上,cache()是使用persist()的快捷方法,它们的实现如下:
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */ def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) /** Persist this RDD with the default storage level (`MEMORY_ONLY`). */ def cache(): this.type = persist()
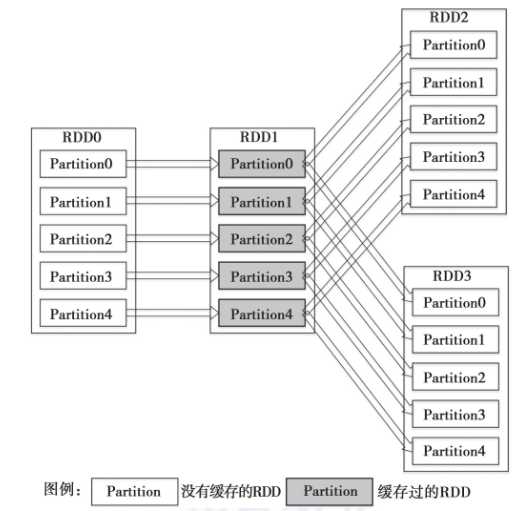
图4中,假设首先进行了RDD0→RDD1→RDD2的计算作业,那么计算结束时,RDD1就已经缓存在系统中了。在进行RDD0→RDD1→RDD3的计算作业时,由于RDD1已经缓存在系统中,因此RDD0→RDD1的转换不会重复进行,计算作业只须进行RDD1→RDD3的计算就可以了,因此计算速度可以得到很大提升。
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除。RDD的缓存的容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列的转换,丢失的数据会被重算。RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
标签:
原文地址:http://www.cnblogs.com/zlslch/p/5723756.html