标签:
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟。除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略。
(1)内存列式存储与内存缓存表
Spark SQL 可以通过 cacheTable 将数据存储转换为列式存储,同时将数据加载到内存进行缓存。 cacheTable 相当于在分布式集群的内存物化视图,将数据进行缓存,这样迭代的或者交互式的查询不用再从 HDFS 读数据,直接从内存读取数据大大减少了 I/O 开销。列式存储的优势在于 Spark SQL 只需要读出用户需要的列,而不需要像行存储那样需要每次将所有列读出,从而大大减少内存缓存数据
量,更高效地利用内存数据缓存,同时减少网络传输和 I/O 开销。数据按照列式存储,由于是数据类型相同的数据连续存储,能够利用序列化和压缩减少内存空间的占用。
(2)列存储压缩
为了减少内存和硬盘空间占用, Spark SQL 采用了一些压缩策略对内存列存储数据 进 行 压 缩。 Spark SQL 的 压 缩 方 式 要 比 Shark 丰 富 很 多, 例 如 它 支 持 PassThrough,RunLengthEncoding, DictionaryEncoding, BooleanBitSet, IntDelta, LongDelta 等多种压缩方式。这样能够大幅度减少内存空间占用和网络传输开销和 I/O 开销。
(3)逻辑查询优化
Spark SQL 在逻辑查询优化(如图 1 所示)上支持列剪枝、谓词下压、属性合并等逻辑查询优化方法。列剪枝为了减少读取不必要的属性列,减少数据传输和计算开销,在查询优化器进行转换的过程中会进行列剪枝的优化。
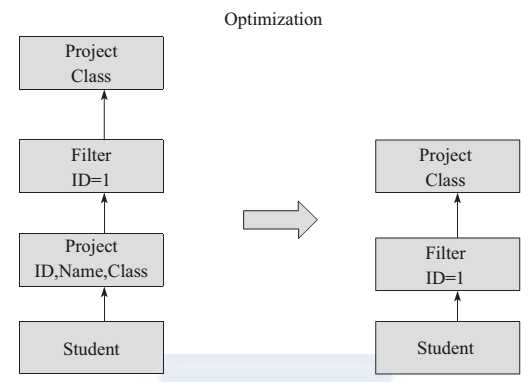
图 1 逻辑查询优化
下面介绍一个逻辑优化例子:
SELECT Class FROM (SELECT ID,Name,Class FROM STUDENT ) S WHERE S.ID=1
Catalyst 将原有查询通过谓词下压,将选择操作 ID=1 优先执行,这样过滤大部分数据,通过属性合并将最后的投影只做一次最终保留 Class 属性列。
(4) Join 优化
Spark SQL 深度借鉴传统数据库查询优化技术的精髓,同时也在分布式环境下进行特定的优化策略调整和创新。 Spark SQL 对 Join 进行了优化支持多种连接算法,现
在的连接算法已经比 Shark 丰富,而且很多原来 Shark 的元素也逐步迁移过来。例如:BroadcastHashJoin、 BroadcastNestedLoopJoin、 HashJoin、 LeftSemiJoin,等等。
下面介绍一个其中的 BroadcastHashJoin 算法思想。BroadcastHashJoin 将小表转化为广播变量进行广播,这样避免 Shuff le 开销,最后在分区内做 Hash 连接。这里用的就是 Hive 中 Map Side Join 的思想。同时用了 DBMS中的 Hash 连接算法做连接。
随着 Spark SQL 的发展,未来会有更多的查询优化策略加入进来。同时后续 SparkSQL 会 支 持 像 Shark Server 一 样 的 服 务 端、 JDBC 接 口, 兼 容 更 多 的 持 久 化 层 例 如
NoSQL,传统的 DBMS 等。一个强有力的结构化大数据查询引擎正在崛起。
标签:
原文地址:http://www.cnblogs.com/zlslch/p/5725097.html