标签:
core/common_runtime/simple_placer_test.cc测试片段如下
1 //////////////////////////////////////////////////////////////////////////////// 2 // 3 // A SimplePlacerTest method has three phases: 4 // 5 // 1. Build a TensorFlow graph, with no (or partial) device assignments. 6 // 2. Attempt to compute a placement using the SimplePlacer. 7 // 3. EITHER: test that the constraints implied by the graph are respected; 8 // or that an appropriate error was reported. 9 // 10 //////////////////////////////////////////////////////////////////////////////// 11 class SimplePlacerTest : public ::testing::Test { 12 protected: 13 SimplePlacerTest() { 14 // Build a set of 10 GPU and 10 CPU devices. 15 // NOTE: this->local_devices_ owns the device objects; 16 // this->devices_ contains borrowed pointers to the device 17 // objects. 18 for (int i = 0; i < 10; ++i) { // 添加了10 cpu和10 gpu的fake devices 19 local_devices_.emplace_back(FakeDevice::MakeCPU( 20 strings::StrCat("/job:a/replica:0/task:0/cpu:", i))); 21 devices_.AddDevice(local_devices_.back().get()); 22 // Insert the GPUs in reverse order. 23 local_devices_.emplace_back(FakeDevice::MakeGPU( 24 strings::StrCat("/job:a/replica:0/task:0/gpu:", 9 - i))); 25 devices_.AddDevice(local_devices_.back().get()); 26 } 27 } 28 ... 29 } 30 ... 31 // Test that a graph with no constraints will successfully assign nodes to the 32 // "best available" device (i.e. prefer GPU over CPU). 33 TEST_F(SimplePlacerTest, TestNoConstraints) { 34 Graph g(OpRegistry::Global()); 35 { // Scope for temporary variables used to construct g. // 用GraphDefBuilder构建graph的结构 36 GraphDefBuilder b(GraphDefBuilder::kFailImmediately); 37 Node* input = ops::SourceOp("TestInput", b.opts().WithName("in")); 38 ops::UnaryOp("TestRelu", ops::NodeOut(input, 0), b.opts().WithName("n1")); 39 ops::UnaryOp("TestRelu", ops::NodeOut(input, 1), b.opts().WithName("n2")); 40 TF_EXPECT_OK(BuildGraph(b, &g)); // BuildGraph函数将GraphDefBuilder的图写入到Graph中 41 } 42 43 TF_EXPECT_OK(Place(&g)); // Place函数将graph中的node布放到设备列表中 44 EXPECT_DEVICE_TYPE(g, "in", DEVICE_CPU); // 期望:input节点在CPU中,n1节点在GPU中,n2节点在GPU中,故而GPU优先级大于CPU 45 EXPECT_DEVICE_TYPE(g, "n1", DEVICE_GPU); 46 EXPECT_DEVICE_TYPE(g, "n2", DEVICE_GPU); 47 }
其中BuildGraph函数将GraphDefBuilder 对象中的graph 结构定义写入到Graph中。Place函数将graph中的node布放到设备列表中,其中device assignment算法的核心在SimplePlacer::Run函数中
1 // Builds the given graph, and (if successful) indexes the node 2 // names for use in placement, and later lookup. 3 Status BuildGraph(const GraphDefBuilder& builder, Graph* out_graph) { 4 TF_RETURN_IF_ERROR(builder.ToGraph(out_graph)); 5 nodes_by_name_.clear(); 6 for (Node* node : out_graph->nodes()) { 7 nodes_by_name_[node->name()] = node->id(); 8 } 9 return Status::OK(); 10 } 11 // Invokes the SimplePlacer on "graph". If no DeviceSet is specified, the 12 // placement will use the default DeviceSet (of 10 CPU and 10 GPU devices). 13 // 14 // REQUIRES: "*graph" was produced by the most recent call to BuildGraph. 15 Status Place(Graph* graph, DeviceSet* devices, SessionOptions* options) { 16 SimplePlacer placer(graph, devices, options); 17 return placer.Run(); 18 }
SimplePlacer::Run()在core/common_runtime/simple_placer.cc文件中,具体实现分为4个步骤:
1 // 1. First add all of the nodes. Note that steps (1) and (2) 2 // requires two passes over the nodes because the graph (and hence 3 // the constraints) may not be acyclic. 这里graph可能是有环的? 4 for (Node* node : graph_->nodes()) { 5 // Skip the source and sink nodes. 6 if (!node->IsOp()) { continue; } 7 status = colocation_graph.AddNode(*node); 8 if (!status.ok()) return AttachDef(status, node->def()); 9 } 10 // 2. Enumerate the constraint edges, and use them to update the disjoint node set. // disjoint set(并查集,即不相交的节点集合),一种树型数据结构, 11 ...
1 ColocationGraph maintains the connected components of a colocation constraint graph, and uses this information to assign a satisfying device placement to the nodes of the graph. 2 The implementation uses the union- find algorithm to maintain the connected components efficiently and incrementally as edges (implied by ColocationGraph::ColocateNodes() invocations) are added. 3 参考:并查集wiki

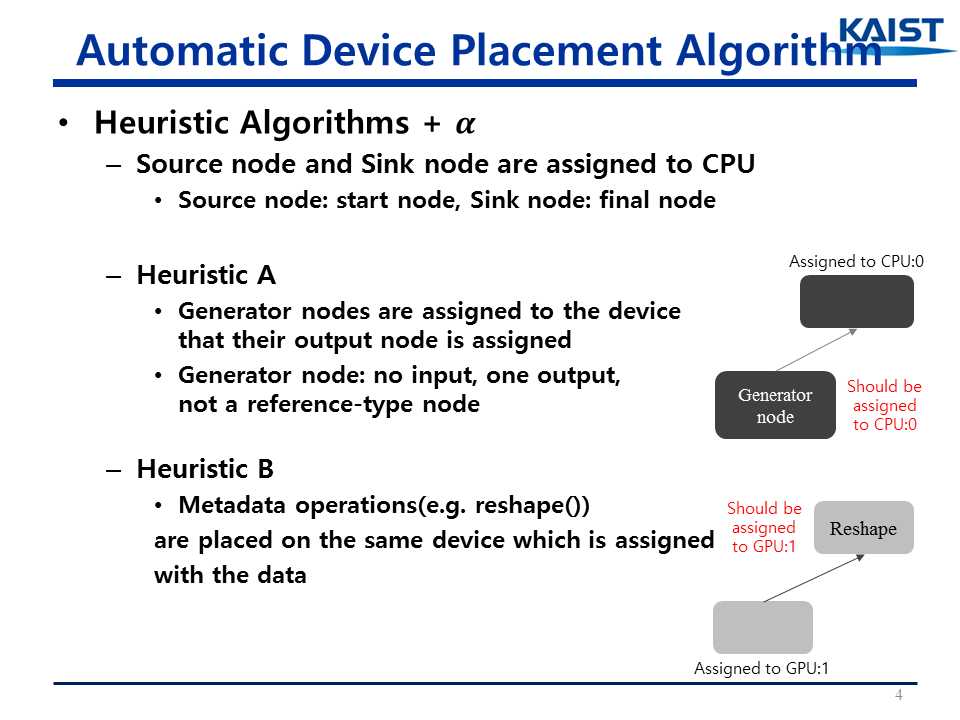
1 3. For each node, assign a device based on the constraints in thedisjoint node set. 2 std::vector<Device*> devices; 3 std::vector<Node*> second_pass; 4 for (Node* node : graph_->nodes()) { 5 // Skip the source and sink nodes. 6 if (!node->IsOp()) { 7 continue; 8 } 9 // Skip nodes that already have an assigned name. 10 if (!node->assigned_device_name().empty()) { 11 continue; 12 } 13 // Heuristic A: prefer to place "generators" with their only 14 // consumers. 15 // 16 // If this is a node with no inputs and a single (non-ref) 17 // consumer, we save this for a second pass, so that the 18 // consumer‘s placement is chosen. 19 if (IsGeneratorNode(node)) { // generator node: no input, one output, not a reference-type node 20 second_pass.push_back(node); 21 continue; 22 } 23 status = colocation_graph.GetDevicesForNode(node, &devices); 24 ... 25 // Returns the first device in sorted devices list so we will always 26 // choose the same device. 27 // 28 // TODO(vrv): Factor this assignment out into a pluggable 29 // algorithm, so that SimplePlacer is responsible for enforcing 30 // preconditions and we can experiment with other algorithms when 31 // given a choice of devices. Once we have a better idea of the 32 // types of heuristics we want to use and the information needed 33 // to perform good placement we can add an interface for this. 34 string assigned_device = devices[0]->name(); 35 // Heuristic B: If the node only operates on metadata, not data, 36 // then it is desirable to place that metadata node with its 37 // input. 38 if (IsMetadataNode(node)) { 39 // Make sure that the input device type is in the list of supported 40 // device types for this node. 41 const Node* input = (*node->in_edges().begin())->src(); 42 // TODO(vrv): if the input is empty, consider postponing this 43 // node‘s assignment to the second pass, so that we handle the 44 // case where a metadata node‘s input comes from a backedge 45 // of a loop. 46 const string& input_device_name = input->assigned_device_name(); 47 if (CanAssignToDevice(input_device_name, devices)) { 48 assigned_device = input_device_name; 49 } 50 } 51 AssignAndLog(assigned_device, node); // 将assigned_device分配个node节点,在步骤3中没有对符合Heuristic A的GeneratorNode分配设备,而是在步骤4中完成的 52 }
1 bool IsGeneratorNode(const Node* node) { 2 return node->num_inputs() == 0 && node->num_outputs() == 1 && node->out_edges().size() == 1 && !IsRefType(node->output_type(0)); 3 }
1 bool IsMetadataNode(const Node* node) { 2 const string& node_type = node->type_string(); 3 return (node_type == "Size" || node_type == "Shape" || node_type == "Rank"); 4 }
// 4. Perform a second pass assignment for those nodes explicitly skipped during the first pass. ...
部分参考:
tensorflow节点布放(device assignment of node)算法:simpler_placer
标签:
原文地址:http://www.cnblogs.com/yao62995/p/5726405.html