标签:
1. 整体架构
GraphX 的整体架构(如图 1所示)可以分为三部分。
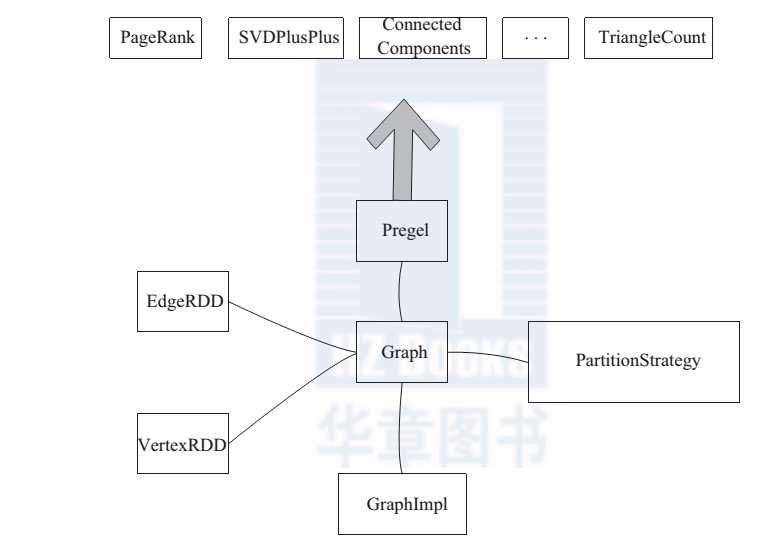
图 1 GraphX 架构
存储和原语层: Graph 类是图计算的核心类。内部含有 VertexRDD、 EdgeRDD 和RDD[EdgeTriplet] 引用。 GraphImpl 是 Graph 类的子类,实现了图操作。
? 接口层:在底层 RDD 的基础之上实现了 Pregel 模型, BSP 模式的计算接口。
? 算法层:基于 Pregel 接口实现了常用的图算法。包括: PageRank、 SVDPlusPlus、TriangleCount、 ConnectedComponents、 StronglyConnectedConponents 等算法。
2. 存储结构
在正式的工业级的应用中,图的规模极大,上百万个节点是经常出现的。为了提高处理速度和数据量,希望能够将图以分布式的方式来存储、处理图数据。图的分布式存储大致有两种方式,边分割( Edge Cut)和点分割( Vertex Cut),如图 2所示。最早期的图计算的框架中,使用的是 Edge Cut(边分割)的存储方式。而 GraphX 的设计者考虑到真实世界中的大规模图大多是边多于点的图,所以采用点分割方式存储。点分割能够减少网络传输和存储开销。底层实现是将边放到各个节点存储,而在进行数据交换时将点在各个机器之间广播进行传输。对边进行分区和存储的算法主要基于 PartitionStrategy中封装的分区方法。这里面的几种分区方法分别是对不同应用情景的权衡,用户可以根据具体的需求进行分区方式的选择。用户可以在程序中指定边的分区方式。例如:
val g = Graph(vertices, partitionBy(edges, PartitionStrategy.EdgePartition2D))
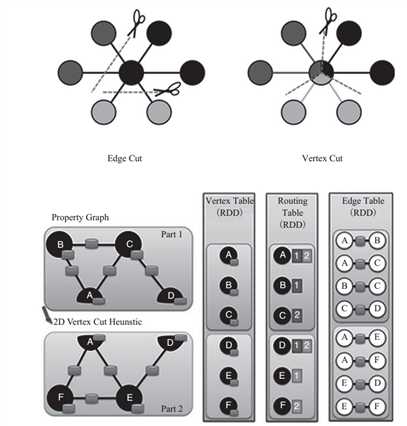
图 2 GraphX 存储模型
一旦边已经在集群上分区和存储,大规模并行图计算的关键挑战就变成了如何将点的属性连接到边。 GraphX 的处理方式是集群上移动传播点的属性数据。由于不是每个分区都需要所有的点属性(因为每个分区只是一部分边), GraphX 内部维持一个路由表(routing table),这样当需要广播点到需要这个点的边的所在分区时就可以通过路由表映射,将需要的点属性传输到指定的边分区。
点分割的好处是在边的存储上是没有冗余数据的,而且对于某个点与它的邻居的交互操作,只要满足交换律和结合律。例如,求顶点的邻接顶点权重的和,可以在不同的节点进行并行运算,最后把每个节点的运行结果进行汇总,网络开销较小。代价是每个顶点属性可能要冗余存储多份,更新点数据时要有数据同步开销。
3. 使用技巧
采样观察可以通过不同的采样比例,先从小数据量进行计算、观察效果、调整参数,再逐步增加数据量进行大规模的运算。可以通过 RDD 的 sample 方法进行采样。同
时通过 Web UI 观察集群的资源消耗。
1)内存释放:保留旧图对象的引用,但是尽快释放不使用的图的顶点属性,节省空间占用。通过 unPersistVertices 方法进行顶点释放。
2) GC 调优,请读者参考性能调优章节介绍。
3)调试:在各个时间点可以通过 graph.vertices.count() 进行调试,观测图现有状态。进行问题诊断和调优。
GraphX 通过提供简洁的 API 以及优化的图数据管理,简化了用户开发分布式图算法的复杂度。在大数据分析中更多的应用场景是进行机器学习。
Spark 之上的 MLlib 进行复杂的机器学习。详细见 http://www.cnblogs.com/zlslch/p/5726346.html
标签:
原文地址:http://www.cnblogs.com/zlslch/p/5726325.html