标签:
假设我们数据库中已经有了JD的SKU信息,没有SKU对应的店铺信息。这时我们需要重新完全采集所有的SKU数据吗?如果SKU是按月份分表存的看趋势,补爬的话历史数据就用不了了。因此,去京东页面上找看是否有提供相关的接口。
1. 安装 Fiddler, 并打开
2. 在谷歌浏览器中访问: http://list.jd.com/list.html?cat=1315,1343,9719
3. 在Fiddler查找一条条的访问记录,找到我们想要的接口
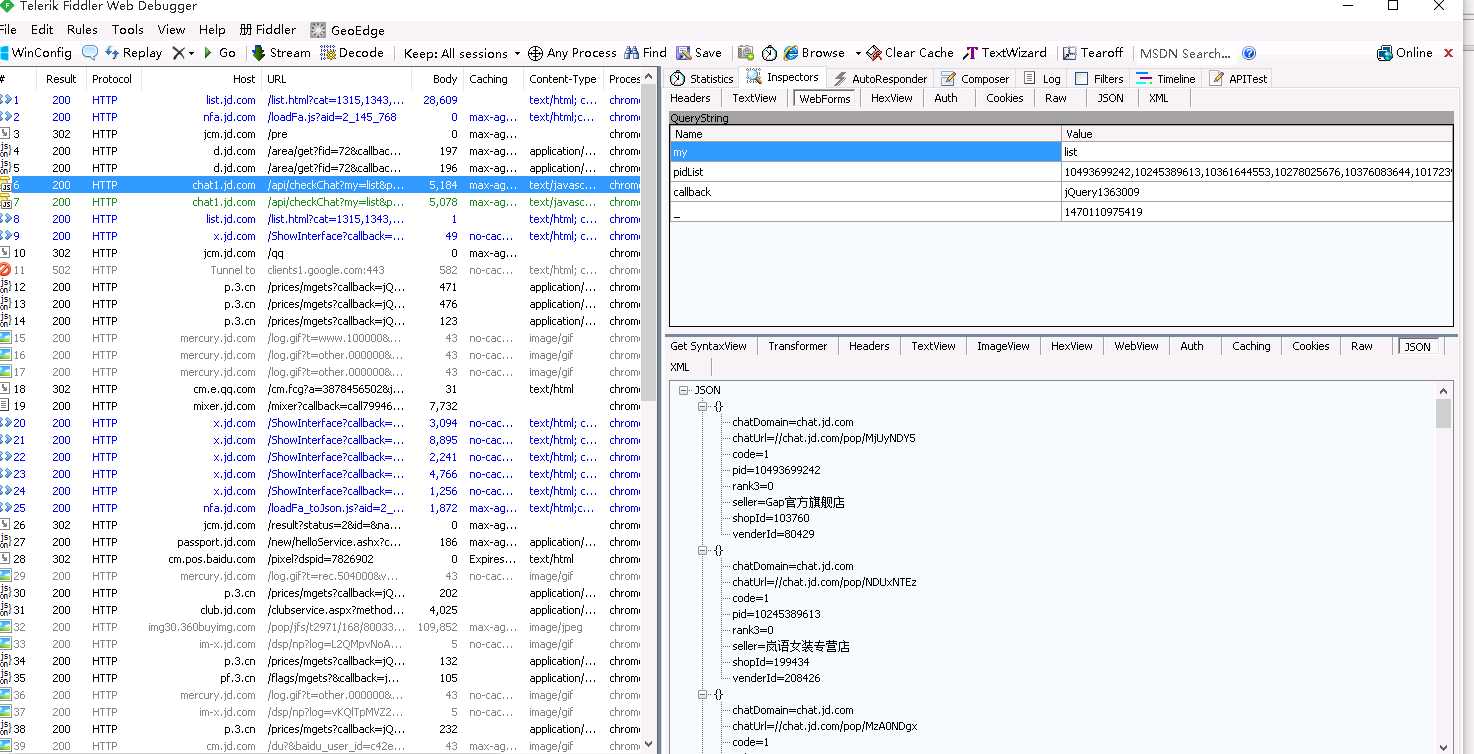
1. 由返回的数据结果,我们可以先写出数据对象的定义,需要注意的是,我们这次的爬虫是更新爬虫,就是说采集到的数据补充回原表,那么就一定要让系统知道比较的条件是什么,因此我们在数据类上添加主键的定义,如下红色部分。
[Schema("jd", "sku")] [TypeExtractBy(Expression = "$.[*]", Multi = true, Type = ExtractType.JsonPath)] [Indexes(Primary = "sku")] public class ProductUpdater : ISpiderEntity { [StoredAs("sku", DataType.String, 25)] [PropertyExtractBy(Expression = "$.pid", Type = ExtractType.JsonPath)] public string Sku { get; set; } [StoredAs("shopname", DataType.String, 100)] [PropertyExtractBy(Expression = "$.seller", Type = ExtractType.JsonPath)] public string ShopName { get; set; } [StoredAs("shopid", DataType.String, 25)] [PropertyExtractBy(Expression = "$.shopId", Type = ExtractType.JsonPath)] public string ShopId { get; set; } }
2. 定义Pipeline的类型为Update
context.AddPipeline(new MysqlPipeline { Mode= Java2Dotnet.Spider.Extension.Pipeline.PipelineMode.Update, ConnectString = "{Your mysql connect string}" });
3. 由于返回的数据中还有一个json()这样的pagging,所以需要先做一个载取操作,我们提供了PageHandler接口,用于HTML的解析前的一些处理操作,因此完整的代码如下
public class JdShopDetailSpider : SpiderBuilder { protected override SpiderContext GetSpiderContext() { SpiderContext context = new SpiderContext { SpiderName = "JD Shop details " + DateTimeUtils.MONDAY_RUN_ID, CachedSize = 1, ThreadNum = 8,
// PageHandler 接口,用于在HTML解析成数据对象前的处理 PageHandlers = new List<PageHandler> { new SubPageHandler { StartString = "json(", EndString = ");", StartOffset = 5, EndOffset = 0 } } }; context.AddStartUrl("http://chat1.jd.com/api/checkChat?my=list&pidList=10493699242,10245389613,10361644553,10278025676,10376083644,10172397660,10082510256,10225597357,10221164706,10274736920,10341185188,10122734006,10392238330,10361670431,10258063068,10235372519,10158798904,10224986782,10391644503,10235651476,10274430258,10471911266,10355674641,10204027715,10391945534,10380714047,10355670276,10366170425,10402927469,10274137897&callback=json&_=1470119523482");
// you can add more url here
context.AddPipeline(new MysqlPipeline { Mode = Java2Dotnet.Spider.Extension.Pipeline.PipelineMode.Update, ConnectString = "{Your mysql connect string}" }); context.AddEntityType(typeof(ProductUpdater)); return context; } [Schema("jd", "sku", TableSuffix.Monday)] [TypeExtractBy(Expression = "$.[*]", Multi = true, Type = ExtractType.JsonPath)] [Indexes(Primary = "sku")] public class ProductUpdater : ISpiderEntity { [StoredAs("sku", DataType.String, 25)] [PropertyExtractBy(Expression = "$.pid", Type = ExtractType.JsonPath)] public string Sku { get; set; } [StoredAs("shopname", DataType.String, 100)] [PropertyExtractBy(Expression = "$.seller", Type = ExtractType.JsonPath)] public string ShopName { get; set; } [StoredAs("shopid", DataType.String, 25)] [PropertyExtractBy(Expression = "$.shopId", Type = ExtractType.JsonPath)] public string ShopId { get; set; } } }
1. 最简单的需求是如果我的采集URL是存在数据库的,每次编写都需要去写ORM或者ADO.NET代码去取数据吗?
2. 如何让JAVA等别的语言也可以调用我们的爬虫系统? 通过一个规范化的JSON配置文件是一个不错的选择
3. 如果将来有从WEB端定义任务,JSON配置文件也可以满足需求
我们提供了一个可配置的初始化URL的接口:PrepareStartUrls可以满足大部分的初始化需求,如果不适用可以通过context.AddStartUrl()添加所有的需要采集的URL
需要3个参数:
From 起始数值
To 结束数值
Interval 间隔数值
FormateString 用于拼接的基本字符串
假设需要采集: http://a.com/1.html, http://a.com/2.html,..., http://a.com/100.html
则可以配置对象为
var prepare = new CyclePrepareStartUrls
{
From = 1,
To = 100,
Interval = 1,
FormateString = "http://a.com/{0}.html"
};
需要5个参数:
From 起始时间
To 结束时间
IntervalDay 间隔天数
DateFormate 时间格式化字符串
FormateString 用于拼接的基本字符串
假设需要采集: http://a.com/2016-08-01.html, http://a.com/2016-08-02.html,..., http://a.com/2016-08-30.html
则可以配置对象为
new DateCyclePrepareStartUrls()
{
From = DateTime.Today.AddDays(-5),
To = DateTime.Today,
FormateString = "http://a.com/{0}.html",
DateFormate = "yyyy-MM-dd",
IntervalDay = 1
};
需要5个参数 :
Source 数据库: MySql, MSSQL ...
QueryString 查询语句
ConnectString 数据库连接字符串
Columns 用于拼接的列
FormateStrings 拼接规则定义,可以是多个
假设数据库中已经存在表table1, 数据字段是: category, brand, date 而需要采集的URL为: http://a.com/category1/brand1.html, http://a.com/category2/brand1.html...
则可以配置对象
new BaseDbPrepareStartUrls()
{
Source = DataSource.MySql,
QueryString = "SELECT `category`,`brand` FROM test.table1",
ConnectString = "{Your mysql connect string}",
Columns = new List<Column> { new Column { Name = "category" } , new Column { Name = "brand" } },
FormateStrings = new List<string> {
"https://a.com/{0}/{1}.html"
},
};
1. 下载器的异步,进一步压榨网络IO
2. 配置化重构,现在的配置化比较混乱,有一些不应该加入、有一些功能又重复了
3. 完善任务监控,设计Web管理项目,可以通过Web上传任务,配置时间调度,查看任务状态、日志,开始、停止任务等
求星: https://github.com/zlzforever/DotnetSpider
QQ群: 477731655
[开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [四] JSON数据解析与配置系统
标签:
原文地址:http://www.cnblogs.com/modestmt/p/5729253.html