标签:

本节要介绍的是Python里面常用的几种数据结构。通常情况下,声明一个变量只保存一个值是远远不够的,我们需要将一组或多组数据进行存储、查询、排序等操作,本节介绍的Python内置的数据结构可以满足大多数情况下的需求。这一部分的知识点比较多,而且较为零散,需要认真学习。
字符串是 Python 中最常用的数据类型。我们可以使用引号(‘或")来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。例如:
var1 =‘Hello World!‘
var2 ="Python Runoob"
Python不支持单字符类型,单字符也在Python也是作为一个字符串使用。
Python访问子字符串,可以使用方括号来截取字符串,如下实例:
var1 =‘Hello World!‘
var2 ="Python Runoob"
print"var1[0]: ", var1[0]
print"var2[1:5]: ", var2[1:5]
以上实例执行结果:
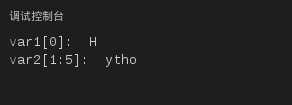
图2
你可以对已存在的字符串进行修改,并赋值给另一个变量,如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
var1 =‘Hello World!‘
print"更新字符串 :- ", var1[:6]+‘Runoob!‘
运行结果如下:
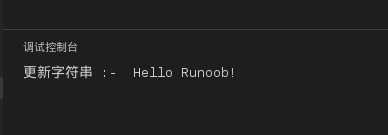
图3
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
|
转义字符 |
描述 |
|
\(在行尾时) |
续行符 |
|
\\ |
反斜杠符号 |
|
\‘ |
单引号 |
|
\" |
双引号 |
|
\a |
响铃 |
|
\b |
退格(Backspace) |
|
\e |
转义 |
|
\000 |
空 |
|
\n |
换行 |
|
\v |
纵向制表符 |
|
\t |
横向制表符 |
|
\r |
回车 |
|
\f |
换页 |
|
\oyy |
八进制数,yy代表的字符,例如:\o12代表换行 |
|
\xyy |
十六进制数,yy代表的字符,例如:\x0a代表换行 |
|
\other |
其它的字符以普通格式输出 |
下表实例变量a值为字符串"Hello",b变量值为"Python":
|
操作符 |
描述 |
实例 |
|
+ |
字符串连接 |
a + b 输出结果: HelloPython |
|
* |
重复输出字符串 |
a*2 输出结果:HelloHello |
|
[] |
通过索引获取字符串中字符 |
a[1] 输出结果 e |
|
[ : ] |
截取字符串中的一部分 |
a[1:4] 输出结果ell |
|
in |
成员运算符 - 如果字符串中包含给定的字符返回 True |
H in a 输出结果 1 |
|
not in |
成员运算符 - 如果字符串中不包含给定的字符返回 True |
M not in a 输出结果 1 |
|
r/R |
原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 |
print r‘\n‘ 输出 \n 和 print R‘\n‘输出 \n |
|
% |
格式字符串 |
请看下一章节 |
实例如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
a ="Hello"
b ="Python"
print"a + b 输出结果:", a + b
print"a * 2 输出结果:", a *2
print"a[1] 输出结果:", a[1]
print"a[1:4] 输出结果:", a[1:4]
if("H"in a):
print"H 在变量 a 中"
else:
print"H 不在变量 a 中"
if("M"notin a):
print"M 不在变量 a 中"
else:
print"M 在变量 a 中"
print r‘\n‘
print R‘\n‘
以上程序执行结果为:
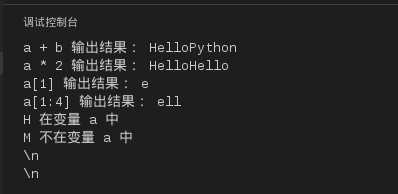
图4
Python 支持格式化字符串的输出。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
比如下面的代码:
#!/usr/bin/python
print"My name is %s and weight is %d kg!"%(‘Zara‘,21)
运行结果为:
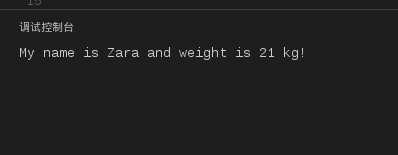
图5
python字符串格式化符号一览表:
|
符 号 |
描述 |
|
%c |
格式化字符及其ASCII码 |
|
%s |
格式化字符串 |
|
%d |
格式化整数 |
|
%u |
格式化无符号整型 |
|
%o |
格式化无符号八进制数 |
|
%x |
格式化无符号十六进制数 |
|
%X |
格式化无符号十六进制数(大写) |
|
%f |
格式化浮点数字,可指定小数点后的精度 |
|
%e |
用科学计数法格式化浮点数 |
|
%E |
作用同%e,用科学计数法格式化浮点数 |
|
%g |
%f和%e的简写 |
|
%G |
%f 和 %E 的简写 |
|
%p |
用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
|
符号 |
功能 |
|
* |
定义宽度或者小数点精度 |
|
- |
用做左对齐 |
|
+ |
在正数前面显示加号( + ) |
|
<sp> |
在正数前面显示空格 |
|
# |
在八进制数前面显示零(‘0‘),在十六进制前面显示‘0x‘或者‘0X‘(取决于用的是‘x‘还是‘X‘) |
|
0 |
显示的数字前面填充‘0‘而不是默认的空格 |
|
% |
‘%%‘输出一个单一的‘%‘ |
|
(var) |
映射变量(字典参数) |
|
m.n. |
m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
python中三引号可以将复杂的字符串进行复制,python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
三引号的语法是一对连续的单引号或者双引号(通常都是成对的用)。
例如:
#三引号
hi = ‘‘‘hi
there‘‘‘
print hi
运行结果如下:
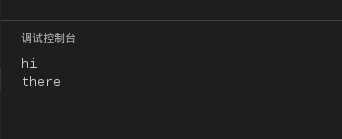
图6
Python 中定义一个 Unicode 字符串和定义一个普通字符串一样简单:
s2=u‘Hello World !‘;
print s2引号前小写的"u"表示这里创建的是一个 Unicode 字符串。如果你想加入一个特殊字符,可以使用 Python 的 Unicode-Escape 编码。如下例所示:
s3=u‘Hello\u0020World !‘
print s3
字符串方法是从python1.6到2.0慢慢加进来的——它们也被加到了Jython中。
这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
|
方法 |
描述 |
|
把字符串的第一个字符大写 |
|
|
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
|
|
返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
|
|
以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的异常,除非 errors 指定的是 ‘ignore‘ 或者‘replace‘ |
|
|
以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是‘ignore‘或者‘replace‘ |
|
|
检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
|
|
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
|
|
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
|
|
跟find()方法一样,只不过如果str不在 string中会报一个异常. |
|
|
如果 string 至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
|
|
如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
|
|
如果 string 只包含十进制数字则返回 True 否则返回 False. |
|
|
如果 string 只包含数字则返回 True 否则返回 False. |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
|
|
如果 string 中只包含数字字符,则返回 True,否则返回 False |
|
|
如果 string 中只包含空格,则返回 True,否则返回 False. |
|
|
如果 string 是标题化的(见 title())则返回 True,否则返回 False |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
|
|
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
|
|
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
|
|
转换 string 中所有大写字符为小写. |
|
|
截掉 string 左边的空格 |
|
|
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
|
|
返回字符串 str 中最大的字母。 |
|
|
返回字符串 str 中最小的字母。 |
|
|
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把字符串 string 分成一个 3 元素的元组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
|
|
把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
|
|
类似于 find()函数,不过是从右边开始查找. |
|
|
类似于 index(),不过是从右边开始. |
|
|
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
|
|
string.rpartition(str) |
类似于 partition()函数,不过是从右边开始查找. |
|
删除 string 字符串末尾的空格. |
|
|
以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串 |
|
|
按照行分隔,返回一个包含各行作为元素的列表,如果 num 指定则仅切片 num 个行. |
|
|
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
|
|
在 string 上执行 lstrip()和 rstrip() |
|
|
翻转 string 中的大小写 |
|
|
返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
|
|
根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
|
|
转换 string 中的小写字母为大写 |
|
|
返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
|
|
isdecimal()方法检查字符串是否只包含十进制字符。这种方法只存在于unicode对象。 |
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
Python有6个序列的内置类型,但最常见的是列表和元组。序列都可以进行的操作包括索引,切片,加,乘,检查成员。此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 =[‘physics‘,‘chemistry‘,1997,2000];
list2 =[1,2,3,4,5];
list3 =["a","b","c","d"];
与字符串的索引一样,列表索引从0开始。列表可以进行截取、组合等。
使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符,如下所示:
#!/usr/bin/python
list1 =[‘physics‘,‘chemistry‘,1997,2000];
list2 =[1,2,3,4,5,6,7];
print"list1[0]: ", list1[0]
print"list2[1:5]: ", list2[1:5]
运行结果如下:
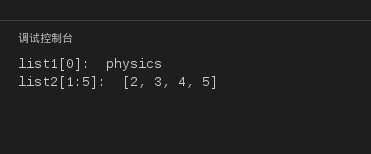
图7
你可以对列表的数据项进行修改或更新,你也可以使用append()方法来添加列表项,如下所示:
#!/usr/bin/python
list =[‘physics‘,‘chemistry‘,1997,2000];
print"Value available at index 2 : "
print list[2];
list[2]=2001;
print"New value available at index 2 : "
print list[2];
运行结果如下:
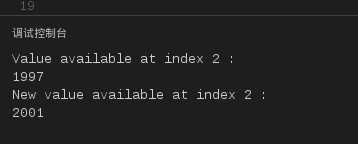
图8
可以使用 del 语句来删除列表的的元素,如下所示:
#!/usr/bin/python
list1 =[‘physics‘,‘chemistry‘,1997,2000];
print list1;
del list1[2];
print"After deleting value at index 2 : "
print list1;
运行结果如下:
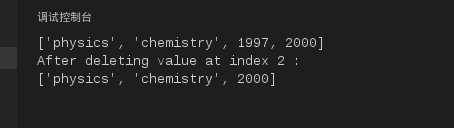
图9
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
|
Python 表达式 |
结果 |
描述 |
|
len([1, 2, 3]) |
3 |
长度 |
|
[1, 2, 3] + [4, 5, 6] |
[1, 2, 3, 4, 5, 6] |
组合 |
|
[‘Hi!‘] * 4 |
[‘Hi!‘, ‘Hi!‘, ‘Hi!‘, ‘Hi!‘] |
重复 |
|
3 in [1, 2, 3] |
True |
元素是否存在于列表中 |
|
for x in [1, 2, 3]: print x, |
1 2 3 |
迭代 |
Python的列表截取与字符串操作类型,如下所示:
L =[‘spam‘,‘Spam‘,‘SPAM!‘]
操作:
|
Python 表达式 |
结果 |
描述 |
|
L[2] |
‘SPAM!‘ |
读取列表中第三个元素 |
|
L[-2] |
‘Spam‘ |
读取列表中倒数第二个元素 |
|
L[1:] |
[‘Spam‘, ‘SPAM!‘] |
从第二个元素开始截取列表 |
Python包含以下函数:
|
序号 |
函数 |
|
1 |
cmp(list1, list2) |
|
2 |
len(list) |
|
3 |
max(list) |
|
4 |
min(list) |
|
5 |
list(seq) |
Python包含以下方法:
|
序号 |
方法 |
|
1 |
list.append(obj) |
|
2 |
list.count(obj) |
|
3 |
list.extend(seq) |
|
4 |
list.index(obj) |
|
5 |
list.insert(index,
obj) |
|
6 |
list.pop(obj=list[-1]) |
|
7 |
list.remove(obj) |
|
8 |
list.reverse() |
|
9 |
list.sort([func]) |
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
如下代码:
tup1 = (‘physics‘, ‘chemistry‘, 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d";
创建空元组
tup1 = ();
元组中只包含一个元素时,需要在元素后面添加逗号
tup1 = (50,);
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
元组可以使用下标索引来访问元组中的值,如下实例:
#!/usr/bin/python
tup1 = (‘physics‘, ‘chemistry‘, 1997, 2000);
tup2 = (1, 2, 3, 4, 5, 6, 7 );
print "tup1[0]: ", tup1[0]
print "tup2[1:5]: ", tup2[1:5]
运行结果如下:
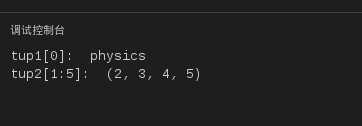
图10
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
tup1 = (12, 34.56);
tup2 = (‘abc‘, ‘xyz‘);
# 以下修改元组元素操作是非法的。
# tup1[0] = 100;
# 创建一个新的元组
tup3 = tup1 + tup2;
print tup3;
运行结果如下:
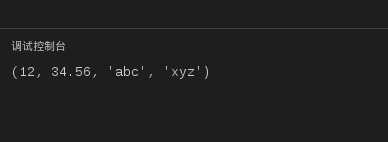
图11
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
#!/usr/bin/python
tup = (‘physics‘, ‘chemistry‘, 1997, 2000);
print tup;
del tup;
print "After deleting tup : "
print tup;
以上实例元组被删除后,运行结果如下:
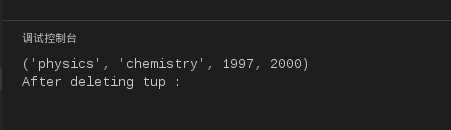
图12
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
|
Python 表达式 |
结果 |
描述 |
|
len((1, 2, 3)) |
3 |
计算元素个数 |
|
(1, 2, 3) + (4, 5, 6) |
(1, 2, 3, 4, 5, 6) |
连接 |
|
[‘Hi!‘] * 4 |
[‘Hi!‘, ‘Hi!‘, ‘Hi!‘, ‘Hi!‘] |
复制 |
|
3 in (1, 2, 3) |
True |
元素是否存在 |
|
for x in (1, 2, 3): print x, |
1 2 3 |
迭代 |
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下所示:
元组:
L = (‘spam‘, ‘Spam‘, ‘SPAM!‘)
|
Python 表达式 |
结果 |
描述 |
|
L[2] |
‘SPAM!‘ |
读取第三个元素 |
|
L[-2] |
‘Spam‘ |
反向读取;读取倒数第二个元素 |
|
L[1:] |
(‘Spam‘, ‘SPAM!‘) |
截取元素 |
任意无符号的对象,以逗号隔开,默认为元组,如下实例:
#!/usr/bin/python
print ‘abc‘, -4.24e93, 18+6.6j, ‘xyz‘;
x, y = 1, 2;
print "Value of x , y : ", x,y;
运行结果如下:
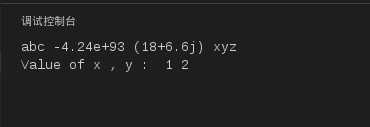
图13
Python元组包含了以下内置函数:
|
序号 |
方法及描述 |
|
1 |
cmp(tuple1, tuple2) |
|
2 |
len(tuple) |
|
3 |
max(tuple) |
|
4 |
min(tuple) |
|
5 |
tuple(seq) |
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
d ={key1 : value1, key2 : value2 }
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
一个简单的字典实例:
dict ={‘Alice‘:‘2341‘,‘Beth‘:‘9102‘,‘Cecil‘:‘3258‘}
也可如此创建字典:
dict1 ={‘abc‘:456};
dict2 ={‘abc‘:123,98.6:37};
把相应的键放入熟悉的方括弧,如下实例:
#!/usr/bin/python
dict ={‘Name‘:‘Zara‘,‘Age‘:7,‘Class‘:‘First‘};
print"dict[‘Name‘]: ", dict[‘Name‘];
print"dict[‘Age‘]: ", dict[‘Age‘];
运行结果如下:
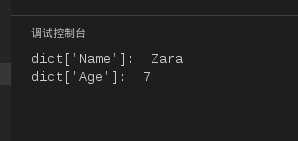
图14
如果用字典里没有的键访问数据,会输出错误:
dict = {‘Name‘: ‘Zara‘, ‘Age‘: 7, ‘Class‘: ‘First‘};
print "dict[‘Name‘]: ", dict[‘Name‘];
print "dict[‘Age‘]: ", dict[‘Age‘];
print dict[‘Xuanhun‘]
运行结果如下:
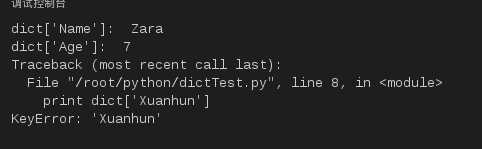
图15
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
#!/usr/bin/python
dict ={‘Name‘:‘Zara‘,‘Age‘:7,‘Class‘:‘First‘};
dict[‘Age‘]=8;# update existing entry
dict[‘School‘]="DPS School";# Add new entry
print"dict[‘Age‘]: ", dict[‘Age‘];
print"dict[‘School‘]: ", dict[‘School‘];
运行结果如下:
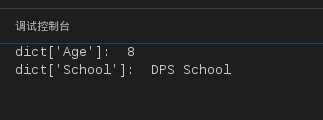
图16
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
dict ={‘Name‘:‘Zara‘,‘Age‘:7,‘Class‘:‘First‘};
del dict[‘Name‘];# 删除键是‘Name‘的条目
dict.clear(); # 清空词典所有条目
del dict ; # 删除词典
print"dict[‘Age‘]: ", dict[‘Age‘];
print"dict[‘School‘]: ", dict[‘School‘];
但这会引发一个异常,因为用del后字典不再存在:
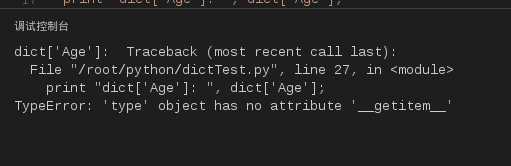
图17
字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
#!/usr/bin/python
dict ={‘Name‘:‘Zara‘,‘Age‘:7,‘Name‘:‘Manni‘};
print"dict[‘Name‘]: ", dict[‘Name‘];
以上实例输出结果:
dict[‘Name‘]: Manni
2)键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行,如下实例:
#!/usr/bin/python
dict ={[‘Name‘]:‘Zara‘,‘Age‘:7};
print"dict[‘Name‘]: ", dict[‘Name‘];
运行结果如下:
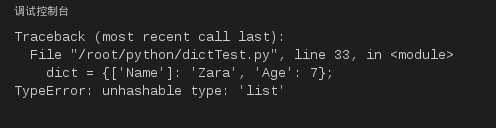
图18
Python字典包含了以下内置函数:
|
序号 |
函数及描述 |
|
1 |
cmp(dict1, dict2) |
|
2 |
len(dict) |
|
3 |
str(dict) |
|
4 |
type(variable) |
Python字典包含了以下内置方法:
|
序号 |
函数及描述 |
|
1 |
radiansdict.clear() |
|
2 |
radiansdict.copy() |
|
3 |
radiansdict.fromkeys() |
|
4 |
radiansdict.get(key, default=None) |
|
5 |
radiansdict.has_key(key) |
|
6 |
radiansdict.items() |
|
7 |
radiansdict.keys() |
|
8 |
radiansdict.setdefault(key,
default=None) |
|
9 |
radiansdict.update(dict2) |
|
10 |
radiansdict.values() |
把不同元素放在一起就组成了集合,集合的成员被称为集合元素。Python的集合和数学的结合在概念和操作上基本相同。Python提供了两种集合:可变集合和不可变集合。
我们先看下面创建集合的代码。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
s1=set(‘abcdde‘)
s2=set([1,2,3,4,5])
s3 = frozenset("xuanhun")
print type(s1)
print type(s3)
print s2
运行结果如下:
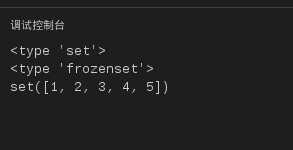
图19
由于集合本身是无序的,所以不能为集合创建索引或切片操作,只能循环遍历或使用in、not in来访问或判断集合元素。
接上面的代码,添加一个循环输出集合内容的代码,如下所示。
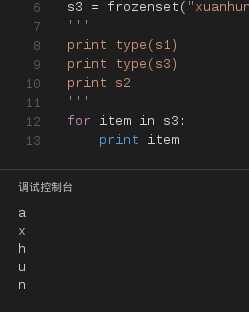
图20
从上图的结果,我们可以看到集合无序,无重复元素的特性。
可使用以下内建方法来更新(只有可变集合才能被更新):
s.add()
s.update()
s.remove()
下面的代码测试了集合的添加和删除操作:
s2=set([1,2,3,4,5])
print s2
s2.add("j")
s2.remove(3)
print s2
运行结果如下:
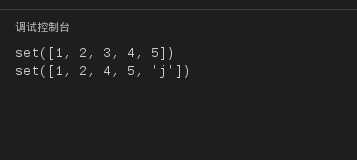
图21
联合(union)操作与集合的OR操作其实等价的,联合符号有个等价的方法,union()。
测试代码如下:
s1=set(‘abcdde‘)
s2=set([1,2,3,4,5])
s4=s1|s2
print s4
运行结果如下:
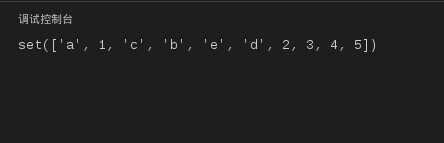
图22
与集合AND等价,交集符号的等价方法是intersection()。
>>> s1&s2
set([‘n‘])
>>> s1.intersection(s2)
set([‘n‘])
等价方法是difference()。
>>> s1-s2
set([‘i‘, ‘b‘, ‘e‘, ‘g‘])
>>> s1.difference(s2)
set([‘i‘, ‘b‘, ‘e‘, ‘g‘])
基本类型和和基本数据结构我们都介绍完毕了,是时候写点更“复杂”的代码了,下一节给大家介绍基本的条件判断和循环。
第2.4节《流程控制》已经在微信订阅号抢先发布,心急的同学进入订阅号(二维码在下方),从菜单“网络安全”—>”Python黑帽编程”进入即可。
本节视频教程获取方法,请扫描二维码,在菜单“网络安全”——>”Python黑帽编程”中找到对应的本文2.2.7节,有详细方法。
由于教程仍在创作过程中,在整套教程完结前,感兴趣的同学请关注我的微信订阅号(xuanhun521,下方二维码),我会第一时间在订阅号推送图文教程和视频教程。问题讨论请加qq群:Hacking (1群):303242737 Hacking (2群):147098303。

关注之后,回复请回复“Python”,获取更多内容。
标签:
原文地址:http://www.cnblogs.com/xuanhun/p/5733839.html