标签:
本节内容
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,让我们先来象征性的学2个简单的。
sys

1 #!/usr/bin/env python
2
3 # -*- coding: utf-8 -*-
4
5
6
7 import sys
8
9
10
11 print(sys.argv)
12
13
14
15
16
17 #输出
18
19 $ python test.py helo world
20
21 [‘test.py‘, ‘helo‘, ‘world‘] #把执行脚本时传递的参数获取到了
os
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 import os
5
6 os.system("df -h") #调用系统命令
完美结合一下
1 import os,sys
2
3 os.system(‘‘.join(sys.argv[1:])) #把用户输入的参数当作一条命令交给os.system执行
自己写个模块
python tab补全模块
1 1 #!/usr/bin/env python
2
3 2 # python startup file
4
5 3 import sys
6
7 4 import readline
8
9 5 import rlcompleter
10
11 6 import atexit
12
13 7 import os
14
15 8 # tab completion
16
17 9 readline.parse_and_bind(‘tab: complete‘)
18
19 10 # history file
20
21 11 histfile = os.path.join(os.environ[‘HOME‘], ‘.pythonhistory‘)
22
23 12 try:
24
25 13 readline.read_history_file(histfile)
26
27 14 except IOError:
28
29 15 pass
30
31 16 atexit.register(readline.write_history_file, histfile)
32
33 17 del os, histfile, readline, rlcompleter
写完保存后就可以使用了,但是自己写的tab.py模块只能在当前目录下导入,如果想在系统的何何一个地方都使用怎么办呢? 此时你就要把这个tab.py放到python全局环境变量目录里啦,基本一般都放在一个叫 Python/2.7/site-packages 目录下,这个目录在不同的OS里放的位置不一样,用 print(sys.path) 可以查看python环境变量列表。
c是compiled的缩写。
1、解释型语言和编译型语言
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言,最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
2、Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
3、简述Python的运行过程
我们先来说两个概念,PyCodeObject和pyc文件。我们看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
1、数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~
自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
2、布尔值
真或假
1 或 0
算数运算:
比较运算:
赋值运算:
逻辑运算:
成员运算:
身份运算:
位运算:
1. 列表、元祖操作
列表:列表是我们以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作。
定义列表
names = [‘Tom‘,"Jack",‘Rose‘]
通过下标访问列表中的元素,下标从0开始计数
1 >>> names[0] 2 3 ‘Tom‘ 4 5 >>> names[2] 6 7 ‘Rose‘ 8 9 >>> names[-1] 10 11 ‘Rose‘ 12 13 >>> names[-2] #还可以倒着取 14 15 ‘Jack‘
切片:取多个元素
1 >>> names = [‘Tom‘,‘Jack‘,‘Rose‘,‘Lucy‘,‘Lilei‘,‘Green‘] 2 3 >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4 4 5 [‘Jack‘, ‘Rose‘, ‘Lucy‘] 6 7 >>> names[1:-1] #取下标1至-1的值,不包括-1 8 9 [‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘] 10 11 >>> names[0:3] 12 13 [‘Tom‘, ‘Jack‘, ‘Rose‘] 14 15 >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 16 17 [‘Tom‘, ‘Jack‘, ‘Rose‘] 18 19 >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 20 21 [‘Lucy‘, ‘Lilei‘, ‘Green‘] 22 23 >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 24 25 [‘Tom‘, ‘Rose‘, ‘Lilei‘] 26 27 >>> names[::2] #和上句效果一样 28 29 [‘Tom‘, ‘Rose‘, ‘Lilei‘]
追加
1 >>> names = [‘Tom‘,‘Jack‘,‘Rose‘,‘Lucy‘,‘Lilei‘,‘Green‘] 2 3 >>>names.append(“NEW”) 4 5 >>>names 6 7 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘NEW‘]
插入
>>>names [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘NEW‘] >>>names.insert(2,"从Jack后面插入") >>>names [‘Tom‘, ‘Jack‘, ‘从Jack后面插入‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘NEW‘] >>>names.insert(7,"再从Green后面插入") >>>names [‘Tom‘, ‘Jack‘, ‘从Jack后面插入‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘再从Green后面插入‘, ‘NEW‘]
修改
1 >>>names 2 3 [‘Tom‘, ‘Jack‘, ‘从Jack后面插入‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘再从Green后面插入‘, ‘NEW‘] 4 5 >>> names[2] = "该换人了" 6 7 >>> names 8 9 [‘Tom‘, ‘Jack‘, ‘该换人了‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘再从Green后面插入‘, ‘NEW‘]
删除
1 >>> del names[2] 2 3 >>> names 4 5 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘再从Green后面插入‘, ‘NEW‘] 6 7 >>> names.remove(""再从Green后面插入"") #删除指定元素 8 9 >>> names 10 11 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘NEW‘] 12 13 >>> names.pop() #删除列表最后一个值 14 15 ‘NEW’ 16 17 >>>names 18 19 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘]
扩展
1 >>> del names[2] 2 3 >>> names 4 5 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘再从Green后面插入‘, ‘NEW‘] 6 7 >>> names.remove(""再从Green后面插入"") #删除指定元素 8 9 >>> names 10 11 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘NEW‘] 12 13 >>> names.pop() #删除列表最后一个值 14 15 ‘NEW’ 16 17 >>>names 18 19 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘]
拷贝
1 >>> names 2 3 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, 1, 2, 3] 4 5 >>> name_copy = names.copy() 6 7 >>> name_copy 8 9 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, 1, 2, 3]
上面这种copy叫浅copy,深入了解一下浅copy
1 names = [‘Tom‘,‘Jack‘,[‘Rose‘,‘James‘],‘Lucy‘,‘Lilei‘,‘Green‘] 2 3 names_copy = names.copy() 4 5 print(names) 6 7 print(names_copy) 8 9 names[1] = "苍老师" 10 11 names[2][0] = "乔丹" 12 13 print(names) 14 15 print(names_copy)
程序输出:
1 [‘Tom‘, ‘Jack‘, [‘Rose‘, ‘James‘], ‘Lucy‘, ‘Lilei‘, ‘Green‘] 2 3 [‘Tom‘, ‘Jack‘, [‘Rose‘, ‘James‘], ‘Lucy‘, ‘Lilei‘, ‘Green‘] 4 5 [‘Tom‘, ‘苍老师‘, [‘乔丹‘, ‘James‘], ‘Lucy‘, ‘Lilei‘, ‘Green‘] 6 7 [‘Tom‘, ‘Jack‘, [‘乔丹‘, ‘James‘], ‘Lucy‘, ‘Lilei‘, ‘Green‘]
对,只copy了一层列表的元素,列表中如果再有列表的话,copy前后的两个列表的内层列表指向的是同一个内存地址,即 将names的Rose改成 乔丹 后,names_copy的Rose也跟着改了。
再来看看深copy
1 import copy 2 3 names = [‘Tom‘,‘Jack‘,[‘Rose‘,‘James‘],‘Lucy‘,‘Lilei‘,‘Green‘] 4 5 names_copy = copy.deepcopy(names) 6 7 print(names) 8 9 print(names_copy) 10 11 names[1] = "苍老师" 12 13 names[2][0] = "乔丹" 14 15 print(names) 16 17 print(names_copy)
程序输出:
1 [‘Tom‘, ‘Jack‘, [‘Rose‘, ‘James‘], ‘Lucy‘, ‘Lilei‘, ‘Green‘] 2 3 [‘Tom‘, ‘Jack‘, [‘Rose‘, ‘James‘], ‘Lucy‘, ‘Lilei‘, ‘Green‘] 4 5 [‘Tom‘, ‘苍老师‘, [‘乔丹‘, ‘James‘], ‘Lucy‘, ‘Lilei‘, ‘Green‘] 6 7 [‘Tom‘, ‘Jack‘, [‘Rose‘, ‘James‘], ‘Lucy‘, ‘Lilei‘, ‘Green‘]
看出区别了吧,深copy是将内层列表也copy了,深copy在创建联合账号时可以用到。
统计
1 >>>names = [‘Tom‘,‘Jack‘,‘Rose‘,‘Tom‘,‘Lucy‘,‘Tom‘,‘Lilei‘,‘Green‘] 2 3 >>>names.count("Tom")
排序&翻转
1 >>> names = [‘Tom‘,‘Jack‘,‘Rose‘,‘Lucy‘,‘Lilei‘,‘Green‘,1,2,3] 2 3 >>> names.sort() #排序 4 5 Traceback (most recent call last): 6 7 File "<stdin>", line 1, in <module> 8 9 TypeError: unorderable types: int() < str() #3.0里不同数据类型不能放在一起排序了,擦 10 11 >>> names[-3] = ‘1‘ 12 13 >>> names[-2] = ‘2‘ 14 15 >>> names[-1] = ‘3‘ 16 17 >>>names 18 19 [‘Tom‘, ‘Jack‘, ‘Rose‘, ‘Lucy‘, ‘Lilei‘, ‘Green‘, ‘1‘, ‘2‘, ‘3‘] 20 21 >>> names.sort() 22 23 >>>names 24 25 [‘1‘, ‘2‘, ‘3‘, ‘Green‘, ‘Jack‘, ‘Lilei‘, ‘Lucy‘, ‘Rose‘, ‘Tom‘] 26 27 >>>names.reverse() 28 29 [‘3‘, ‘2‘, ‘1‘, ‘Green‘, ‘Lilei‘, ‘Lucy‘, ‘Rose‘, ‘Jack‘, ‘Tom‘]
获取下标
1 >>>names = [‘Tom‘,‘Jack‘,‘Rose‘,‘Lucy‘,‘Lilei‘,‘Green‘,1,2,3] 2 3 >>>names.index("Jack")
元组:元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
语法
names = ("tom","jack","rose")
它只有2个方法,一个是count,一个是index,完毕。
2. 字符串操作
a.count() #判断某元素在字符串中的个数
1 >>>a = ‘abacdaefg’ 2 3 >>>a.count(‘a’)
a.capitalize() #把字符串首字母变为大写
1 >>>a = ‘abacdaefg’ 2 3 >>>a. capitalize () 4 5 ‘Abacdaefg’
a.casefold() #汉语 & 英语环境下面,继续用 lower()没问题;要处理其它语言且存在大小写情况的时候再用casefold()
1 >>>a = "this is A testing" 2 3 >>>a.casefold() 4 5 this is a testing 6 a.center() # 7 8 a = "this is A testing" 9 print(a.center(40,"-")) 10 11 -----------this is A testing------------ 12 a.encode() #默认是UTF-8格式 13 14 msg = " 好好学习,天天向上" 15 #print(msg.encode().decode(encoding=‘utf-8‘)) 16 print(msg.encode()) 17 print(msg.encode().decode()) 18 19 b‘\xe5\xa5\xbd\xe5\xa5\xbd\xe5\xad\xa6\xe4\xb9\xa0\xef\xbc\x8c\xe5\xa4\xa9\xe5\xa4\xa9\xe5\x90\x91\xe4\xb8\x8a‘#编码 20 21 好好学习,天天向上 #解码
a.endswith() #判断字符串是否以指定字符或子字符串结尾,常用于判断文件类型
1 a = "this is A testing" 2 3 print(a.endswith("ing")) 4 5 True
a.expandtabs() #把字符串中的 tab 符号(‘\t‘)转为空格,返回字符串中的 tab 符号(‘\t‘)转为空格后生成的新字符串
1 a = "---\tthis is A testing" 2 print(a) 3 print(a.expandtabs()) 4 5 --- this is A testing 6 7 --- this is A testing
a.format() #格式化字符串
1 a = "this is A testing" 2 print("----->{test}".format(test=a))
a.find() #返回参数在字符串中首次出现的位置
1 a = "this is A testing" 2 print(a.find("s"))
a.format_map() #传入的参数是字典
a.index() #同find()方法
a.isalnum() #检测字符串是否由字母和数字组成
a.isalpha() #检测字符串是否只由字母组成
a.isdigit() #判断字符串是不是数字
a.isidentifier() #判断字符串是否是合法的标识符
a.islower() #判断是不是小写
a.isnumeric() #检测字符串是否只由数字组成
a.isspace() #判断字符串是否仅包含空格或制表符。注意:空格字符与空白是不同的
a.istitle() #判断字符串是不是标题格式
a.isupper() #判断是不是大写
a.join() #连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
a.ljust() #返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。
a.lower() #把大写转成小写
a.lstrip() #去掉字符串左边的空格
a.maketrans() #将左右参数对应,用右边参数替换左边参数
a.replace() #把字符串中的 old(旧字符串) 替换成 new(新字符串)
a.rfind() #返回字符串最后一次出现的位置,如果没有匹配项则返回-1
a.rindex() #返回子字符串 str 在字符串中最后出现的位置
a.rjust() #返回一个原字符串右对齐,并使用空格填充至指定长度的新字符串
a.rsplit() #去掉右边空格或换行符
a.rstrip() #去掉字符串右边的空格
a.strip() #去掉字符串中的空格
a.split() #字符串切片
a.splitlines() #按行分隔,返回一个包含各行作为元素的列表,如果 num 指定则仅切片 num 个行.
a.startswith() #判断是不是以参数中内容开头
a.swapcase() #对字符串的大小写字母进行转换
a.title() #把字符串转成标题格式
1 a = "MY NAME Is TOM" 2 3 print(a.title()) 4 5 My Name Is Tom 6 a.translate() #
a.translate() # 根据参数table给出的表(包含 256 个字符)转换字符串的字符, 要过滤掉的字符放到 del 参数中
a.upper() #把小写转成大写
3. 字典操作
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
语法:
1 a = "MY NAME Is TOM" 2 3 print(a.title()) 4 5 My Name Is Tom 6 a.translate() #
字典的特性:
增加
1 >>> info["stu04"] = "苍老师" 2 3 >>> info 4 5 {‘stu04‘: ‘苍老师‘, ‘stu01‘: ‘Tom‘, ‘stu02‘: ‘Jack‘, ‘stu03‘: ‘Rose‘}
修改
1 >>> info[‘stu01‘] = "Lily" 2 3 >>> info 4 5 {‘stu02‘: ‘Jack‘, ‘stu01‘: ‘Lily‘, ‘stu04‘: ‘苍老师‘, ‘stu03‘: ‘Rose‘}
删除
1 >>> info 2 3 {‘stu01‘: ‘Tom‘, ‘stu03‘: ‘Rose‘, ‘stu04‘: ‘Lilei‘, ‘stu02‘: ‘Jack‘} 4 5 >>>info.pop(‘stu02’) #标准删除 6 7 >>>info 8 9 {‘stu01‘: ‘Tom‘, ‘stu04‘: ‘Lilei‘, ‘stu03‘: ‘Rose‘} 10 11 >>>del info[‘stu01‘] #另外一种删除方式 12 13 >>>info 14 15 {‘stu02‘: ‘Jack‘, ‘stu03‘: ‘Rose‘, ‘stu04‘: ‘Lilei‘} 16 17 >>> info.popitem() #随机删除
查找
1 >>> info = {‘stu02‘: ‘Tom‘, ‘stu03‘: ‘Jack‘} 2 3 >>> 4 5 >>> "stu02" in info #标准用法 6 7 True 8 9 >>> info.get("stu02") #获取 10 11 ‘Tom‘ 12 13 >>> info["stu02"] #同上,但是看下面 14 15 ‘Tom‘ 16 17 >>> info["stu05"] #如果一个key不存在,就报错,get不会,不存在只返回None 18 19 Traceback (most recent call last): 20 21 File "<stdin>", line 1, in <module> 22 23 KeyError: ‘stu05‘
多级字典嵌套及操作
1 V = { 2 ‘car‘:{ 3 ‘BMW‘:[‘X5‘,‘M3‘], 4 "BenZ":[‘GLK‘,‘S300‘], 5 "Audi":[‘A8‘,‘Q7‘], 6 }, 7 ‘motorcycle‘:{ 8 "川崎":["很贵","好看"], 9 "庞巴迪":["也很贵","霸气"] 10 }, 11 ‘bike‘:{ 12 "捷安特":["不错","台湾产"], 13 "永久":["便宜","国产"] 14 } 15 } 16 17 V[‘car‘][‘BMW‘][1] += ":$500" 18 19 print(V[‘car‘][‘BMW‘][1]) 20 21 M3:$500
其它
info = { ‘stu01‘:‘Tom‘, ‘stu02‘:‘Jack‘, ‘stu03‘:‘Rose‘, ‘stu04‘:‘Lilei‘ }
#values
1 >>> info.values() 2 3 dict_values([‘Jack‘, ‘Tom‘, ‘Rose‘, ‘Lilei‘])
#keys
1 >>> info.keys() 2 3 dict_keys([‘stu01‘, ‘stu03‘, ‘stu04‘, ‘stu02‘])
#setdefault
1 >>>info.setdefault(‘stu05‘,‘Lily‘) 2 3 ‘Lily’ 4 5 >>>info 6 7 {‘stu01‘: ‘Tom‘, ‘stu02‘: ‘Jack‘, ‘stu04‘: ‘Lilei‘, ‘stu03‘: ‘Rose‘, ‘stu05‘: ‘Lily‘} 8 9 10 11 >>> info.setdefault(‘stu02‘,‘fengjie‘) #已经存在的value不会被setdefault改变 12 13 ‘jack’ 14 15 >>>info 16 17 {‘stu05‘: ‘Lily‘, ‘stu03‘: ‘Rose‘, ‘stu02‘: ‘Jack‘, ‘stu04‘: ‘Lilei‘, ‘stu01‘: ‘Tom‘}
#update
1 >>> info 2 3 {‘stu03‘: ‘Rose‘, ‘stu01‘: ‘Tom‘, ‘stu02‘: ‘Jack‘, ‘stu04‘: ‘Lilei‘} 4 5 >>> b = {1: 2, 3: 4, ‘stu02‘: ‘苍老师‘} 6 7 >>> info.update(b) 8 9 >>> info 10 11 {‘stu03‘: ‘Rose‘, 3: 4, ‘stu02‘: ‘苍老师‘, 1: 2, ‘stu04‘: ‘Lilei‘, ‘stu01‘: ‘Tom‘}
#items
1 info.items() #以列表返回可遍历的(键, 值) 元组数组 2 3 dict_items([(1, 2), (‘stu01‘, ‘Tom‘), (3, 4), (‘stu02‘, ‘苍老师‘), (‘stu03‘, ‘Rose‘), (‘stu04‘, ‘Lilei‘)])
循环dict
#方法1
1 for key in info: 2 3 print(key,info[key])
#方法2
1 for k,v in info.items(): #会先把dict转成list,数据里大时莫用 2 3 print(k,v)
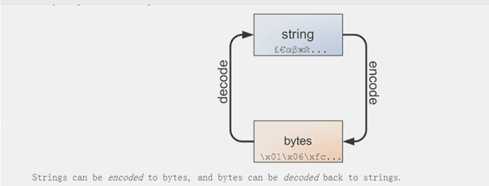
1 msg = " 好好学习,天天向上" 2 print(msg.encode(‘utf-8‘)) 3 print(msg.encode(‘utf-8‘).decode(‘utf-8‘)) 4 5 程序输出: 6 7 b‘\xe5\xa5\xbd\xe5\xa5\xbd\xe5\xad\xa6\xe4\xb9\xa0\xef\xbc\x8c\xe5\xa4\xa9\xe5\xa4\xa9\xe5\x90\x91\xe4\xb8\x8a‘ 8 好好学习,天天向上
Python自动化 【第二篇】:Python基础-列表、元组、字典
标签:
原文地址:http://www.cnblogs.com/ZhPythonAuto/p/5730415.html
