标签:
?
| ? | ? | ? | ? |
阿里:ACE | majia######@1 | 139****3496 | |
谷歌:GAE | ? | ? | ? |
盛大:CAE | majia###### | 139****3496 | |
腾讯:CEE | ? | ? | ? |
新浪: | hebinn@###### | | |
百度: | ? | ? | ? |
网易云信:im | ? | ? | ? |
?
?

?
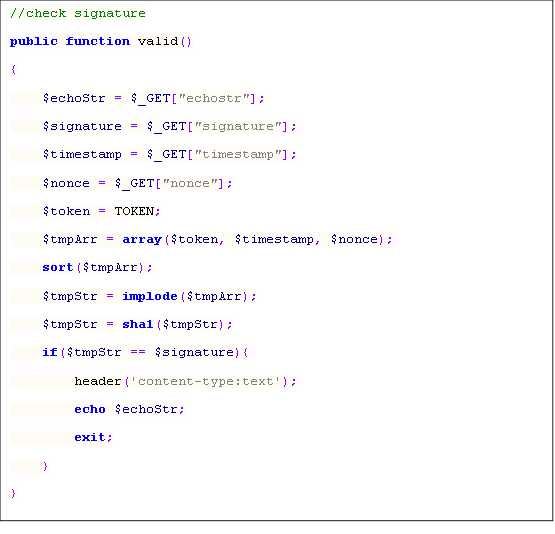
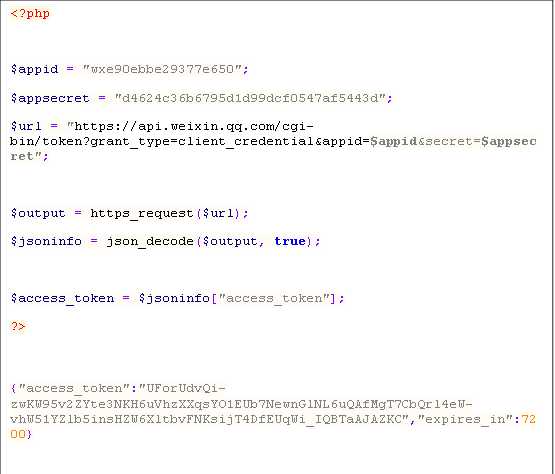
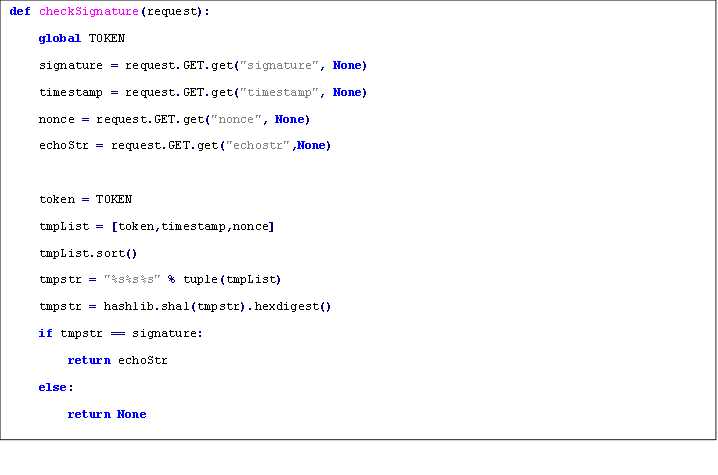
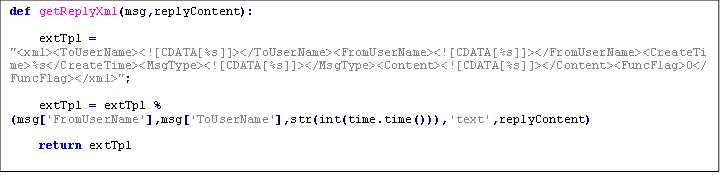
微信公众平台验证接口,会发送GET请求到指定的URL,并带上四个参数,分别是signature微信加密签名,timestamp时间戳,nonce随机数,echostr随机字符串,通过检验signature来判断该请求是否来自微信服务器,这里会用到一个自己设参数token,相 当与一个加密密钥,通过这个可以防止第三方伪造请求,如果判断成功就原样返回echostr那么就接入成功。
加密方式不复杂,文档里这样介绍的
加密/校验流程:
1. 将token、timestamp、nonce三个参数进行字典序排序
2. 将三个参数字符串拼接成一个字符串进行sha1加密
3. 开发者获得加密后的字符串可与signature对比,标识该请求来源于微信
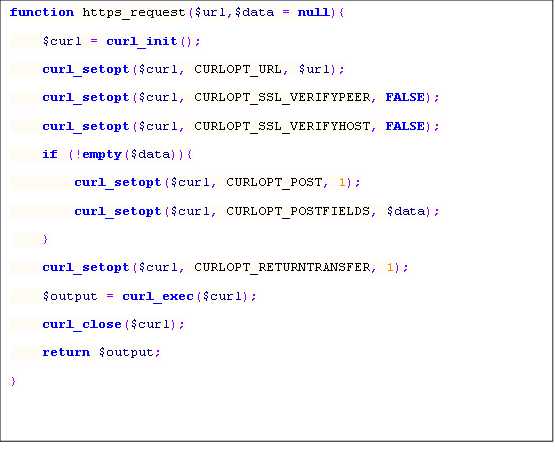
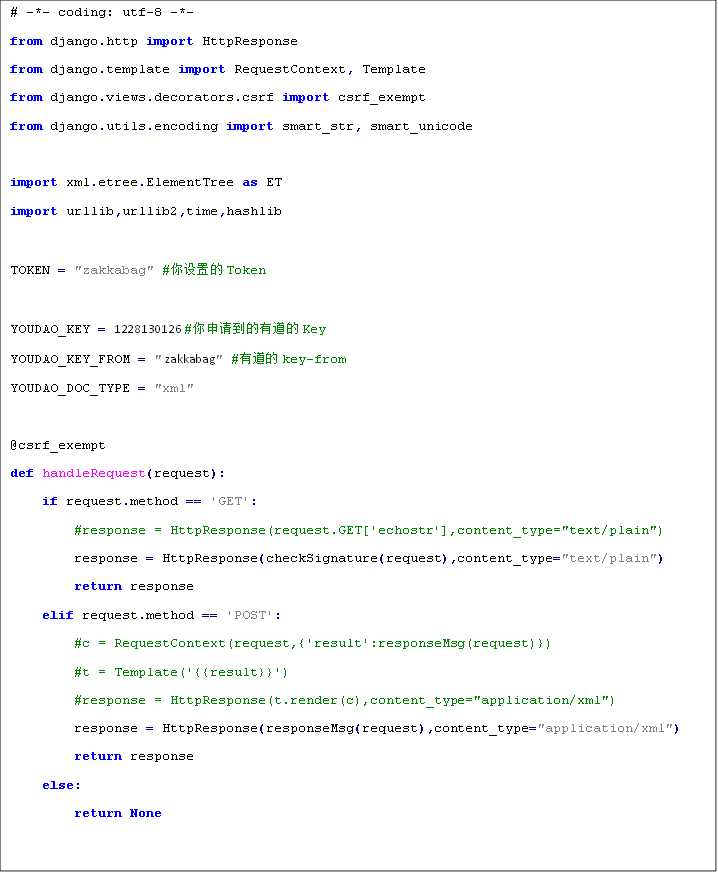
根据这个流程我们实现这样一个验证函数,通过python强大的标准库
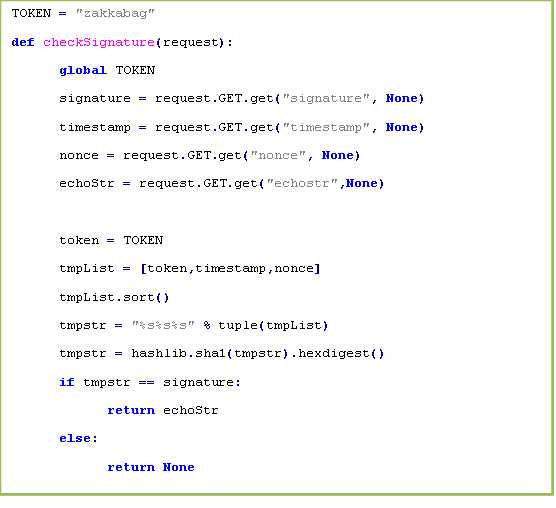
打开zakkabag中的views.py编写如下代码正确响应微信接入信号
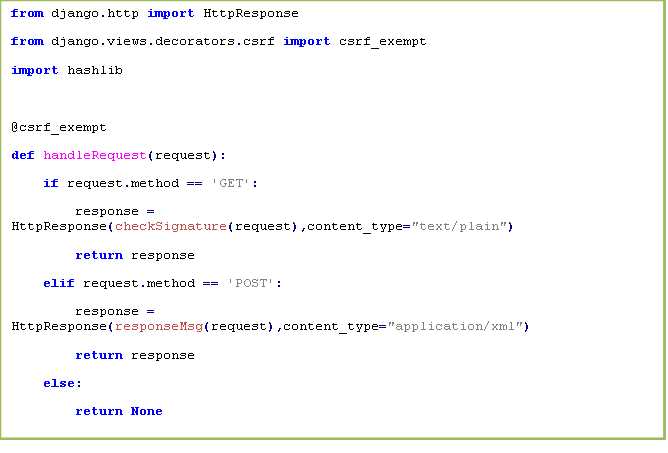
在zakkabag目录下新建一个urls.py代码如下:
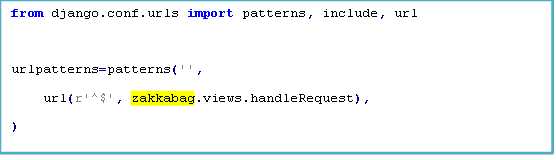
然后在总urls里面添加

再setting中启用wechat,尝试下在公众平台中验证下,地址就是你自己配置的URL,token填写自己设的token,应该很快可以验证通过,这样你就拥有了微信公众平台的开发权限了
?
?

Token 可任意值,跟app里一致即可
?
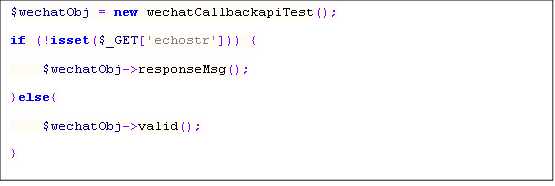

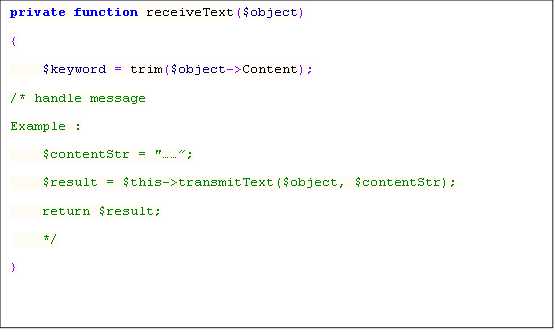
Handle WeChat request with XML format. simplexml_load_string load data to object
?


signature = request.GET.get("signature", None)
PHP:
$signature = $_GET["signature"];
?
Python:
rawStr = smart_str(request.raw_post_data)
PHP:
$postStr = $GLOBALS["HTTP_RAW_POST_DATA"];
?
?
$postObj = simplexml_load_string($postStr, ‘SimpleXMLElement‘, LIBXML_NOCDATA);
$RX_TYPE = trim($postObj->MsgType);
?
msg = paraseMsgXml(ET.fromstring(rawStr))
queryStr = msg.get(‘Content‘,‘You have input nothing~‘)
?
进入地址 https://mp.weixin.qq.com/debug/,
?
* URL : 开发者填写URL,调试时将把消息推送到该URL上http://zakkabag.sinaapp.com/
* ToUserName : 开发者微信号 gh_d8544573f4b1
* FromUserName : 发送方帐号(一个OpenID)
* CreateTime : 消息创建时间 (整型)
* MsgType : 消息类型(文本消息为 text )
* Content : 消息类型(文本消息内容)
* MsgId : 消息类型(消息id,64位整型)
?
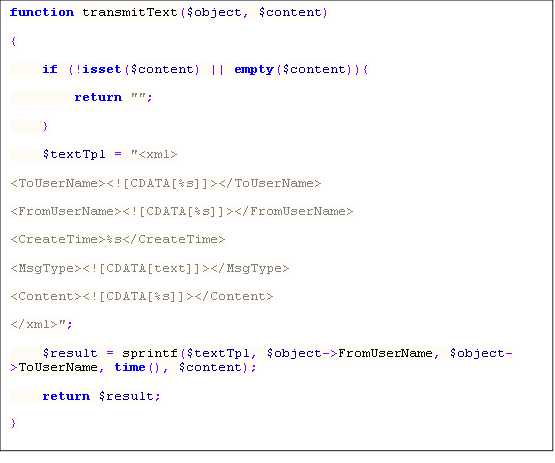
<xml>
<ToUserName><![CDATA[gh_d8544573f4b1]]></ToUserName>
<FromUserName><![CDATA[ojpX_jig-gyi3_Q9fHXQ4rdHniQs]]></FromUserName>
<CreateTime>1412079737</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[方倍工作室]]></Content>
<MsgId>6064836289959967853</MsgId>
</xml>
?
?

?

?
?
有道API
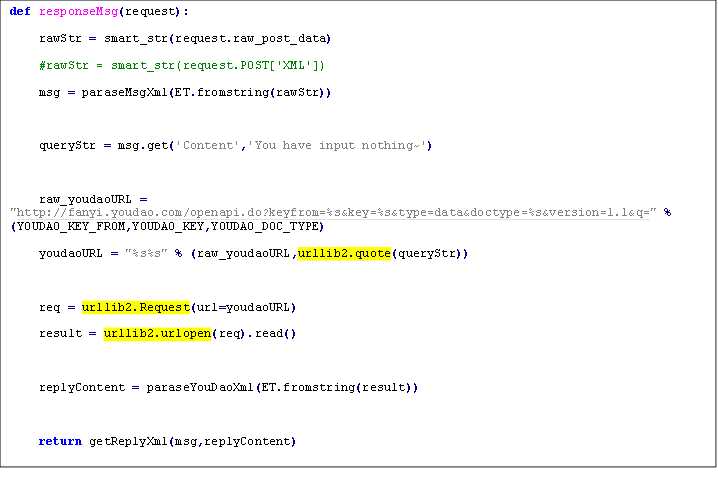
然后,去有道API申 请一个key,申请的时候网站地址随便填就行。有道API非常简单,直接以GET的形式把要翻译的文本发送到指定的url,然后它会给我们回复翻译结果, 我们可以选择xml、json等返回格式,下例是xml,接着,在浏览器里面按着指定的格式输入url,就可以看到返回结果啦:

注意,如果是对词进行翻译的话有的词还会返回一些啥网络释义,基本释义啥的,具体对这个xml解析的方法请看下面的代码。
?
有道翻译API http://fanyi.youdao.com/openapi?path=data-mode
API key:1228130126
keyfrom:zakkabag
?
服务端代码
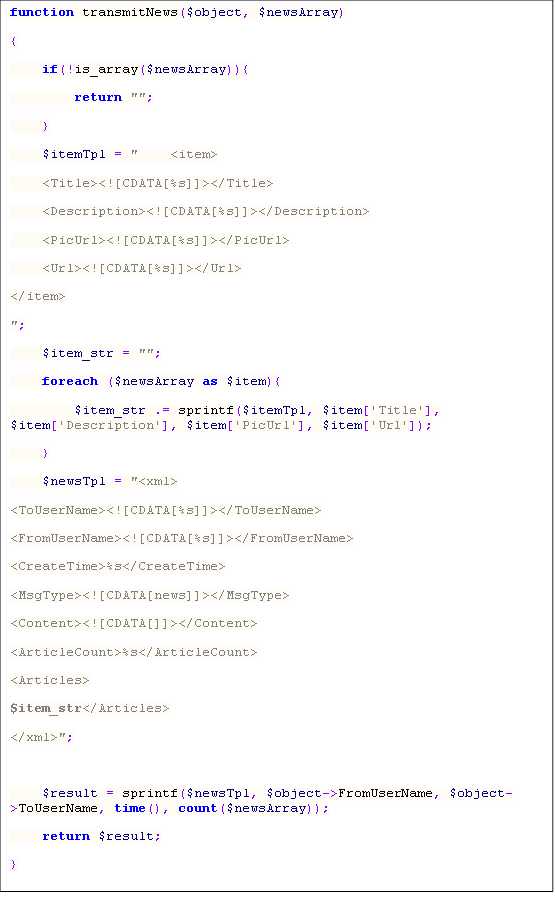
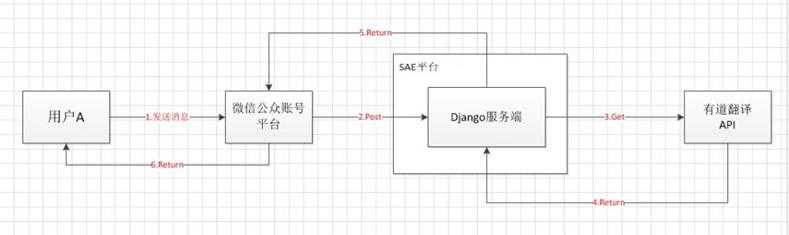
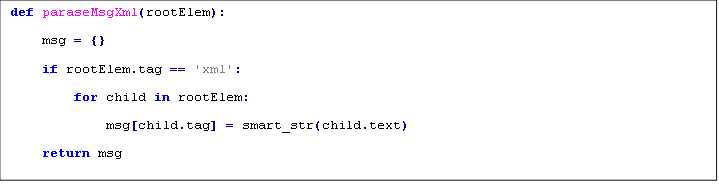
大致思想就是:用户A向公众帐号发送一条消息,微信平台会按着公众帐号预先的设置,把用户A的消息内容和一些其他信息(如创建时间等)以xml的形式post到我们预先设置好的url上(这个url的服务端就是我们要写的在SAE上 的应用),我们要做的就是每当接受到微信post请求,我们解析微信平台post过来的xml,得到用户A的消息内容,把消息内容以get的形式发送到有道API,获取有道API返回的xml(或json等),解析,之后按微信平台规定的格式构造成一个xml,作为微信平台post请求的结果给其返回,微 信平台收到结果后,会把消息自动回复给用户,用户就能收到翻译结果了。
用一个图表示上述过程如下:
?
代码解释
Django 为字符编码的转换提供了非常简洁的方法:
django.utils.encoding.smart_unicode
django.utils.encoding.smart_str
我们在需要将用户提交的数据转换为 Unicode 的时候,可以使用 smart_unicode,而在需要将程序中字符输出到非 Unicode 环境(比如 HTTP 协议数据)时可以使用 smart_str 方法。拿 DDlog 来说,也有不少地方用到了这两个方法。
1、smart_unicode 在 DDlog 中的使用
Blog 的标签(Tag)一般多少会有中文,对于服务器环境来说,不会安装系统级的 UTF-8 环境,那么浏览器请求的 URL 中包含的中文会作为经过 urllib.quote 编码转换后的 UTF-8 字符串(注意,这种情况下,Django 不会自动转换为 Unicode),这里,我们在使用这个数据之前,需要进行一定的转换。
比较原始的方法类似如下:
def post_via_tag(request, tag):
from urllib import unquote
key = unquote(unicode(tag).encode(‘UTF-8‘))
tag_as = Tag.objects.select_related().get(tag__iexact = key)
而如果使用 Django 的 smart_unicode,明显简洁得多(也更符合 DRY 原则):
def post_via_tag(request, tag):
from django.utils.encoding import smart_unicode
tag_as = Tag.objects.select_related().get(tag__iexact = smart_unicode(tag))
# ... other code
2、smart_str 在 DDlog 中的使用
DDlog 在接受评论的时候,会将评论者的姓名和邮件地址保存到 Cookie 中,以便该用户下次发表评论的时候自动显示相关信息。而评论者的姓名有可能是中文的,如果直接把中文字符串放到 Cookie 中,会引发 UnicodeEncodeError 异常。
这里需要进行去 Unicode 编码:
def post_comment(request, slug):
# ... other prepare code
response.set_cookie(‘COMMENT_AS_NAME‘, smart_str(comment_user.name), expired_at)
就这么简单便捷!
?
Python的url编码函数是在类urllib库中,使用方法是:
编码:urllib.quote(string[, safe]),除了三个符号"_.-"外,将所有符号编码,后面的参数safe是不编码的字符,
使用的时候如果不设置的话,会将斜杠,冒号,等号,问号都给编码了。
>>> import urllib
>>> print urllib.quote("http://neeao.com/index.php?id=1")
http%3A//neeao.com/index.php%3Fid%3D1
这样在使用urllib.urlopen打开编码后的网址的时候,就会报错了。
设置不编码的符号:
>>> print urllib.quote("http://neeao.com/index.php?id=1",":?=/")
http://neeao.com/index.php?id=1 这下就好了。
?
?
?

?
?




?

?
?
Copy http://debug.fangbei.org/ source code
Notepad++ : Encoding->Convert to UTF-8
?
?

Python 实现……….
?
?
?
?
[X] django连接微信公众平台
[原]微信公众号开发之使用eclipse创建微信web工程并发布到BAE测试
微信机器人:小蜗牛有道翻译小助手——Django + SAE + 微信公众帐号自动回复开放接口
?
?
?
使用python一步一步搭建微信公众平台(一)----基本的验证与鹦鹉学舌功能
使用python一步一步搭建微信公众平台(二)----搭建一个中英互译的翻译工具
使用python一步一步搭建微信公众平台(三)----添加用户关注后的欢迎信息与听音乐功能
使用python一步一步搭建微信公众平台(四)----将小黄鸡引入微信自动回复
使用python一步一步搭建微信公众平台(五)----使用mysql服务来记录用户的反馈
?
?
?
我们知道,在一些编程开发的环境下,代码中的关键字是用不同的颜色标识的。但有时会需要把代码粘贴到word中,而如果直接粘贴,往往是没有颜色的。
如果你也遇到这个问题,我爱搜集网博主向你介绍的这个方法也许可以帮助你。
搞定。
如果在IDE下的话,以VS和Eclipse为例。直接复制过去就是了。
?
?
inputStr = "当前文件时UTF-8,所以你所看到的这段字符串,也是UTF-8编码的";
SyntaxError: Non-ASCII character ‘\xb5‘ in file D:\eclipse-workspace\co_python_spreading\1\zakkabag\zakkabag\encodings.py on line 7, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
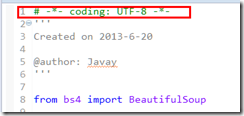
原因:Python默认是以ASCII作为编码方式的,如果在自己的Python源码中包含了中文(或者其他的语言,比如小日本的日语……),此时即使你把自己编写的Python源文件以UTF-8格式保存了;但实际上,这依然是不行的。
解决方法:在源码的第一行添加以下语句:
# -*- coding: UTF-8 -*-????
或者
#coding=utf-8
(注:此语句一定要添加在源代码的第一行)
http://www.evernote.com/l/ADNtV3K5kMNOoby8sGOea0HdtYAiMHDUIec/
?
?
?
content.decode("gbk")
UnicodeDecodeError: ‘gbk‘ codec can‘t decode bytes in position 224-225: illegal multibyte sequence
http://www.tuicool.com/articles/nEjiEv
要处理的字符串本身不是gbk编码,但是你却以gbk编码去解码
http://www.evernote.com/l/ADNtV3K5kMNOoby8sGOea0HdtYAiMHDUIec/
标签:
原文地址:http://www.cnblogs.com/2dogslife/p/5738689.html