标签:
BloomFilter算法及其适用场景
BloomFilter是利用类似位图或者位集合数据结构来存储数据,利用位数组来简洁的表示一个集合,并且能够快速的判断一个元素是不是已经存在于这个集合。因为基于Hash来计算数据所在位置,所以BloomFilter的添加和查询操作都是O(1)的。因为存储简洁,这种数据结构能够利用较少的内存来存储海量的数据。那么,还有这种时间和空间两全其美的算法?当然不是,BloomFilter正是它的高效(使用Hash)带来了它的判断不一定是正确的,也就是说准确率不是100%。因为再好的Hash都是存在冲突的,这样的话同一个位置可能被多次置1。这样再判断的时候,有可能一个不存在的数据就会误判成存在。但是判断存在的数据一定是存在的。这里需要注意的是这里的Hash和HashMap不同,HashMap可以使用开放定址发、链地址法来解决冲突,因为HashMap是有Key-Value结构的,是可逆的,可以定位。但是Hash是不可逆的,所以不能够解决冲突。虽然BloomFilter不是100%准确,但是可以通过调节参数,使用Hash函数的个数,位数组的大小来降低失误率。这样调节完全可以把失误率降低到接近于0。可以满足大部分场景了。
关于BloomFilter的理论请参考:
http://blog.csdn.net/jiaomeng/article/details/1495500
https://en.wikipedia.org/wiki/Bloom_filter
适用场景:BloomFilter一般适用于大数据量的对精确度要求不是100%的去重场景。
爬虫链接的去重:大的爬虫系统有成千上万的链接需要去爬,而且需要保证爬虫链接不能循环。这样就需要链接列表的去重。把链接Hash后存放在BitSet中,然后在爬取之前判断是否存在。
网站UV统计:一般同一个用户的多次访问是要过滤掉的,一般大型网站的UV是巨大的,这样使用BloomFilter就能较高效的实现。
结合Redis
前面说的BloomFilter算法是单机的,可以使用JDK自带的BitSet来实现。但是拥有大数据量的系统绝不是一台服务器,所以需要多台服务器共享。结合Redis的BitMap就能够完美的实现这一需求。利用redis的高性能以及通过pipeline将多条bit操作命令批量提交,实现了多机BloomFilter的bit数据共享。唯一需要注意的是redis的bitmap只支持2^32大小,对应到内存也就是512MB,数组的下标最大只能是2^32-1。不过这个限制我们可以通过构建多个redis的bitmap通过hash取模的方式分散一下即可。万分之一的误判率,512MB可以放下2亿条数据。
实践
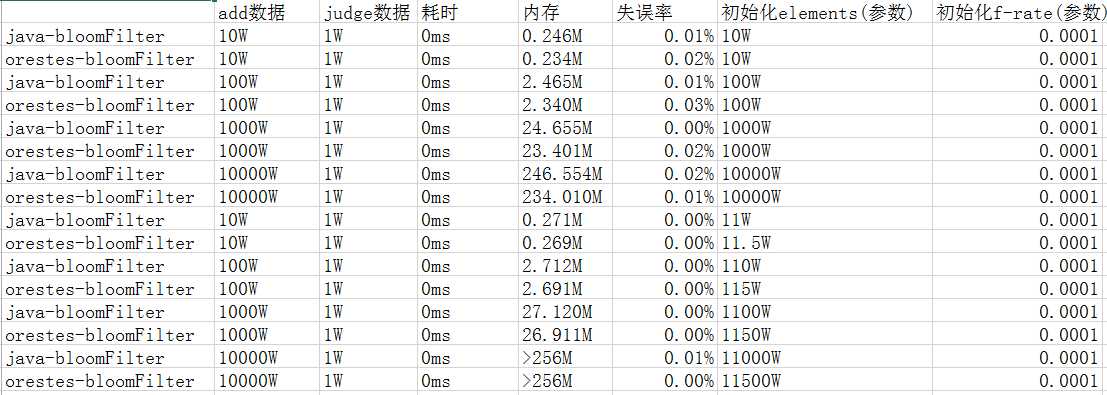
使用了Github上两个开源的实现测试了一下,是基于JDK BitSet实现的。
开源代码:https://github.com/MagnusS/Java-BloomFilter
https://github.com/Baqend/Orestes-Bloomfilter
测试结果(在本地测试,耗时是每条数据的耗时):
然后在java-bloomFilter的基础上修改了源代码,在有5个节点的Redis集群上做了一下测试。
测试结果:
初始化:173070
插入数据:173070
查询数据:173070
耗时:350261ns
内存:326KB
失误率:0.00%
可以看到结合Redis的BloomFilter算法的性能还是比较好的。
Redis+BloomFilter测试源代码:https://github.com/wxisme/redis-bloomFilter
标签:
原文地址:http://www.cnblogs.com/wxisme/p/5742456.html