标签:
Very Deep Convolutional Networks for Large-Scale Image Recognition
针对原始论文ImageNet classification with deep convolutional neural networks[2]里的框架,目前主要的改进有:
文献[3]:utilised smaller receptive window size and smaller stride of the first convolutional layer.
文献[4]:dealt with training and testing the networks densely over the whole image and over multiple scales.
To measure the improvement brought by the increased ConvNet depth in a fair setting, all our ConvNet layer configurations are designed using the same principles come from [1].
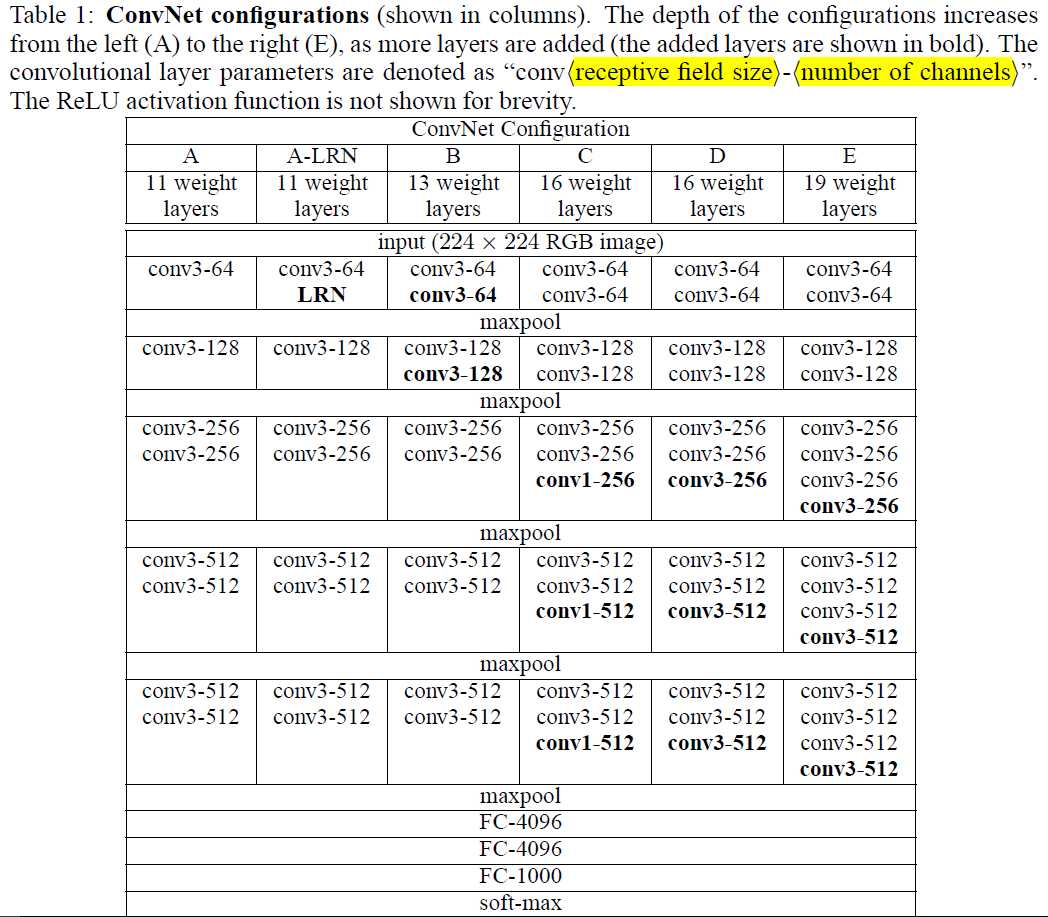
首先, 三层比一层更具有判别性.(First, we incorporate three non-linearrectification layers instead of a single one, which makes the decision function more discriminative.)
其次, 假设同样的通道数C, 那么三层3×3的参数数目为3×(3×3)C×C=27C×C, 一层7×7参数数目为7×7×C×C=49C×C, 大大减少了参数数目.
a) implicit regularisation imposed by greater depth and smaller conv. filter sizes
b) pre-initialisation of certain layers.
a). 在不同的尺度下, 训练多个分类器, 参数为S, 参数的意义就是在做原始图片上的缩放时的短边长度. 论文中训练了S=256和S=384两个分类器, 其中S=384的分类器的参数使用S=256的参数进行 初始化, 且使用一个小的初始学习率10e-3.
b). 另一种方法是直接训练一个分类器, 每次数据输入时, 每张图片被重新缩放, 缩放的短边 S 随机从[min, max]中选择, 本文中使用区间[256,384], 网络参数初始化时使用S=384时的参数.
a). 将全连接层转换为卷积层,第一个全连接转换为7×7的卷积,第二个转换为1×1的卷积。
b). Resulting net is applied to the whole image by convolving the filters in each layer with the full-size input. The resulting output feature map is a class score map with the number channels equal to the number of classes, and the variable spatial resolution, dependent on the input image size.
c). Finally, class score map is spatially averaged(sum-pooled) to obtain a fixed-size vector of class scores of the image.
使用图1中的CNN结构进行实验,在C/D/E网络结构上进行多尺度的训练,注意的是,该组实验的测试集只有一个尺度。如下图所示:
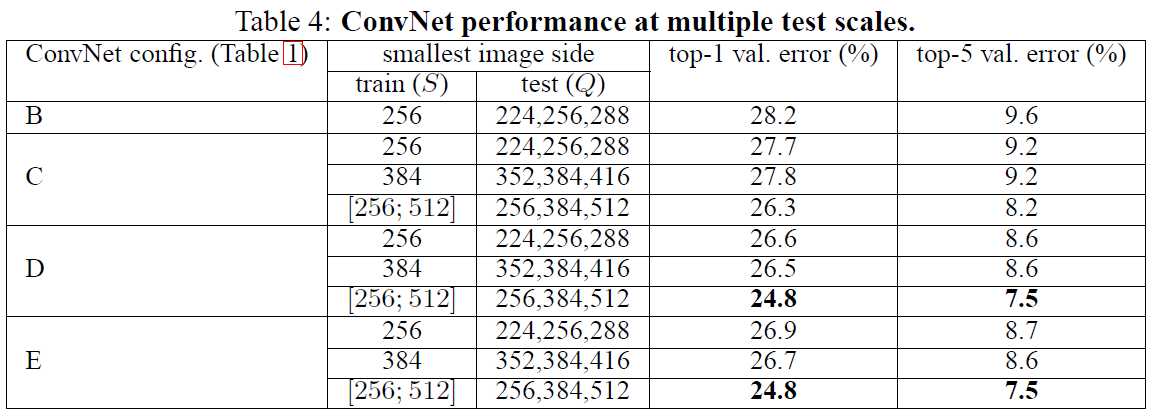
测试集多尺度,且考虑到尺度差异过大会导致性能的下降,所以测试集的尺度Q在S的上下32内浮动。对于训练集是区间尺度的,测试集尺度为区间的最小值、最大值、中值。
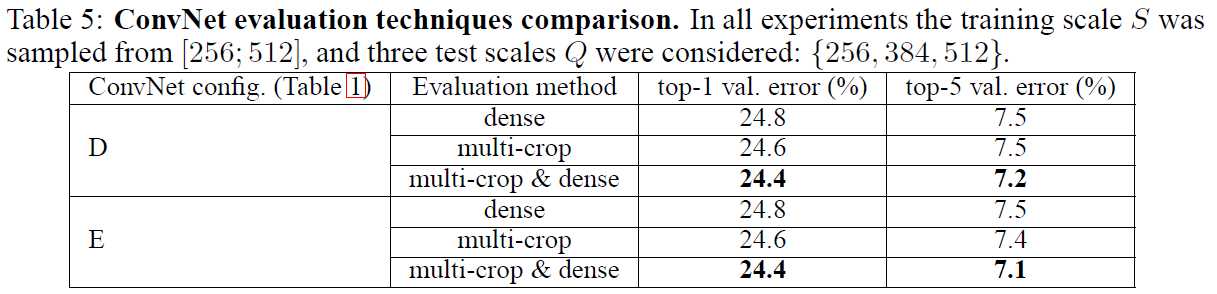
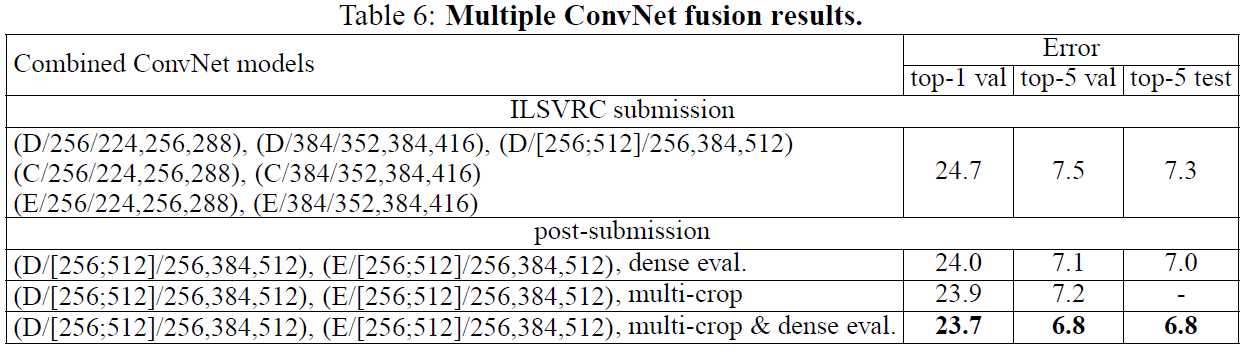
模型融合,方法是取其后验概率估计的均值。融合图3和图4中两个最好的model可以达到更好的值,融合七个model会变差。
[1]. Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[2]. Krizhevsky, A., Sutskever, I., and Hinton, G. E. ImageNet classification with deep convolutional neural networks. In NIPS, pp. 1106–1114, 2012.
[3]. Zeiler, M. D. and Fergus, R. Visualizing and understanding convolutional networks. CoRR, abs/1311.2901, 2013. Published in Proc. ECCV, 2014.
[4]. Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., and LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. In Proc. ICLR, 2014.
[5]. Lin, M., Chen, Q., and Yan, S. Network in network. In Proc. ICLR, 2014.
深度学习笔记(二)Very Deep Convolutional Networks for Large-Scale Image Recognition
标签:
原文地址:http://www.cnblogs.com/xuanyuyt/p/5743758.html