标签:
最近听吴老的电台,收获颇多,给人映像最深的就是:学会编程 和 坚持学习;作为一名测试员,要从一名手工测试转化成 测试开发 或者资深的测试工程师,编码水平是必须具备的基本素质;吴老所说,撸1W到2W行代码算入门,其实我自己也不知道我又没有撸到1W行代码,虽然在工作中能用python编写测试脚本来辅助测试,提高自己的工作效率;为了更加巩固的加强自己的编码基础,所以买了一本 python核心编程第三版,来夯实基础。
从今天开始,我会坚持把这本书,学习完毕,并借博客园这个平台来记录学习过程和总结;为了早日成为一位牛叉的测试员,也为了 进一步提高自己的价值,当然也是为了能获得高薪了,哈哈哈!
下面的是本书的第一部分:通用应用主题,第一章:正则表达式
正则表达式总体来说有两种模式:匹配和搜索,match和search
最常用的方法有:compile、match、search、findall、split、sub
常用的模块属性:re.I 忽略大小写、re.M匹配时,根据字符串的首尾来结束,不是按照换行来确定字符串的结束
re.S “.” 能匹配所有的字符、
match:是从字符串的开始进行匹配,失败则返回None,否则返回匹配结果:
>>> s = ‘test‘
>>> re.match(‘st‘,s)
>>> result = re.match(‘st‘,s)
>>> print result
None
>>> result = re.match(‘tes‘,s)
>>> result
<_sre.SRE_Match object at 0x02D6FA30>
>>> result.group()
‘tes‘
search:直接就是在字符串里面查找,没有找到返回None
>>> s = ‘test‘
>>> result = re.search(‘ww‘,s)
>>> print result
None
>>> result = re.search(‘st‘,s)
>>> print result.group()
st
findall:这个是我以前经常用到这个,反正以前用到正则表达式的时候都用它
找到时返回一个list,如果没找到也会返回一个空的list
>>> s = ‘Just to learn‘
>>> pattern = re.compile(‘^j\w+‘)
>>> result = re.findall(pattern,s)
>>> print result
[]
>>> pattern = re.compile(‘^j\w+?‘)
>>> result = re.findall(pattern,s)
>>> print result
[]
>>> pattern = re.compile(‘^J\w+‘)
>>> result = re.findall(pattern,s)
>>> print result
[‘Just‘]
>>>
split 和 sub 这两个方法也是我今天才知道的,以前从来没用过,感觉也比较使用
>>> s = ‘Just to learn,HAHA‘
>>> result = re.split(‘\s|,‘,s)
>>> print result
[‘Just‘, ‘to‘, ‘learn‘, ‘HAHA‘]
这个split比str.split强大太多了
>>> s = ‘I love you forever!‘
>>> result = re.sub(‘\s‘,‘=>‘,s)
>>> print result
I=>love=>you=>forever!
>>>
sub 和 str.replace比较像,只是更加牛逼
正则表达式,我感觉在工作中用到的地方太多了,包括前段时间的ui自动化,和最近接口测试中,都会用到,奇妙无穷
下面这张图是在其他人那里扣出来的,我经常作为字典来用,具体从哪儿来的,我也记不清了,总之不好意思,我也要贴一下,哈哈
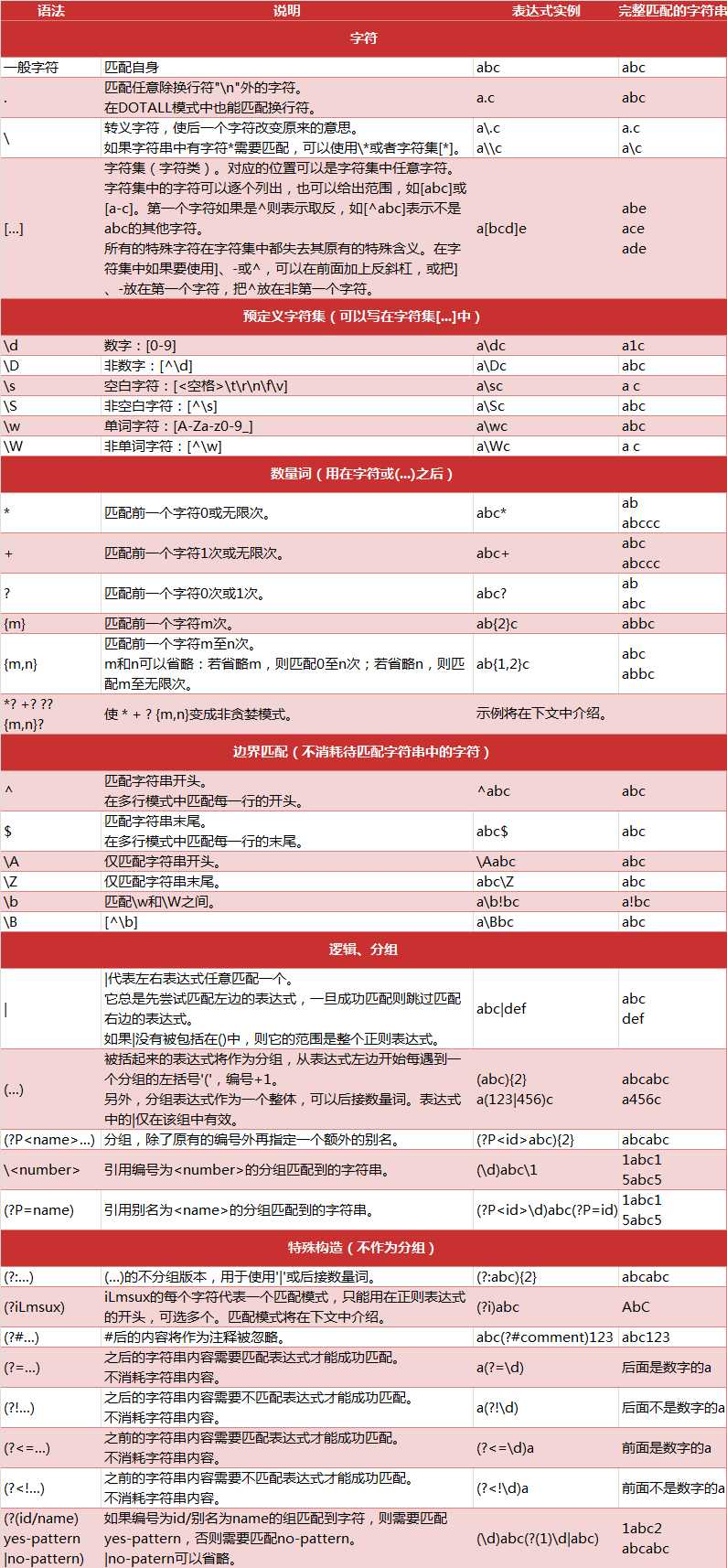
正则表达式:re--python核心编程(3),chapter 1
标签:
原文地址:http://www.cnblogs.com/xiaoshitoutest/p/5747315.html