标签:
因为要找工作,把之前自己搞的爬虫整理一下,没有项目经验真蛋疼,只能做这种水的不行的东西。。。T T,希望找工作能有好结果。
之前爬虫使用的是requests+多线程/多进程,后来随着前几天的深入了解,才发现,对于爬虫来说,真正的瓶颈并不是CPU的处理速度,而是对于网页抓取时候的往返时间,因为如果采用requests+多线程/多进程,他本身是阻塞式的编程,所以时间都花费在了等待网页结果的返回和对爬取到的数据的写入上面。而如果采用非阻塞编程,那么就没有这个困扰。这边首先要理解一下阻塞和非阻塞的区别
1.阻塞调用是指调用结果返回之前,当前线程会被挂起(线程进入非可执行状态,在这个状态下,CPU不会给线程分配时间片,即线程暂停运行)。函数只有在得到结果之后才会返回。
2.对于非阻塞则不会挂起,直接执行接下去的程序,返回结果后再回来处理返回值。
python 3.4开始就支持异步IO编程,提供了asyncio库,但是3.4中采用的是@asyncio.coroutine和yield from这和原来的generator关键字yield不好区分,在3.5中,采用了async(表示携程)和await关键字,这样就好区分多了。
写这篇博客的目的在于,网上看了一堆资料,自己还是没有理解如何进行asyncio的编程,用到自己代码里时候,还是有各种错误,因此打算看一下asyncio的官方手册并好好梳理一下,希望时间的来的及~
https://docs.python.org/3/library/asyncio.html
这边用一个简单的官方例子来说明async和await的执行顺序。
import asyncio
async def compute(x, y):
print("Compute %s + %s ..." % (x, y))
await asyncio.sleep(1.0)
return x + y
async def print_sum(x, y):
result = await compute(x, y)
print("%s + %s = %s" % (x, y, result))
loop = asyncio.get_event_loop()
loop.run_until_complete(print_sum(1, 2))
loop.close()
如果不使用async和await,这个程序的运行顺序也很好理解
1.print_sum(1,2)将参数1,2传递给函数print_sum
2.先执行第一句,result = compute(x,y),
3.将1,2传递给compute函数,compute函数收到参数
4.先执行 print("Compute %s + %s ..." % (x, y))打印出Compute 1 + 2 ...
5.执行sleep(1.0)程序挂起一秒
6.返回1+2的值3
7.print_sum的result收到返回值3,执行print("%s + %s = %s" % (x, y, result)),打印出1 + 2 = 3
8.程序结束
如果采用异步的话,他执行顺序是怎么样的呢?
下图是他官方文档的说明:
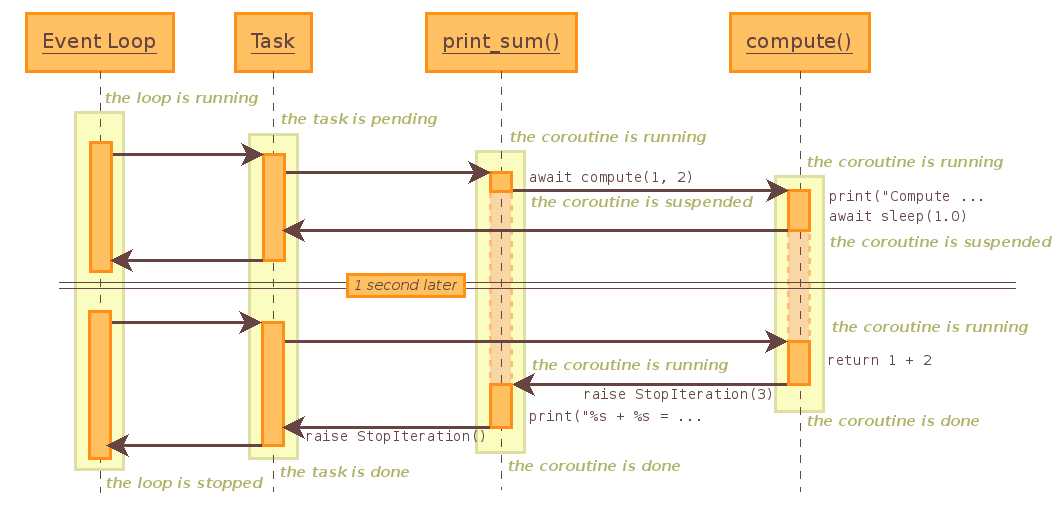
要理解上图,首先我们要理解Event_loop,feture,task等概念,详细的可以参考官方文档或者http://my.oschina.net/lionets/blog/499803
首先get_event_loop()方法让我们得到一个消息环,event loop对象包括两部分:event和loop
标签:
原文地址:http://www.cnblogs.com/rockwall/p/5750900.html