标签:
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库。NoSQL数据库的四大分类

键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。 举例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB.
列存储数据库。
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra, HBase, Riak.
文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。如:CouchDB, MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。
图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。如:Neo4J, InfoGrid, Infinite Graph.
NoSQL数据库在以下的这几种情况下比较适用:1、数据模型比较简单;2、需要灵活性更强的IT系统;3、对数据库性能要求较高;4、不需要高度的数据一致性;5、对于给定key,比较容易映射复杂值的环境。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets)和有序集合(sorted sets)等类型。

Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
官网:redis.io
github:https://github.com/MSOpenTech/redis
下载地址:https://github.com/MSOpenTech/redis/releases
打开redis在github上的网站:https://github.com/MSOpenTech/redis/releases,选择下载最新版的Redis,写该文字时最新版本是3.2.1版。
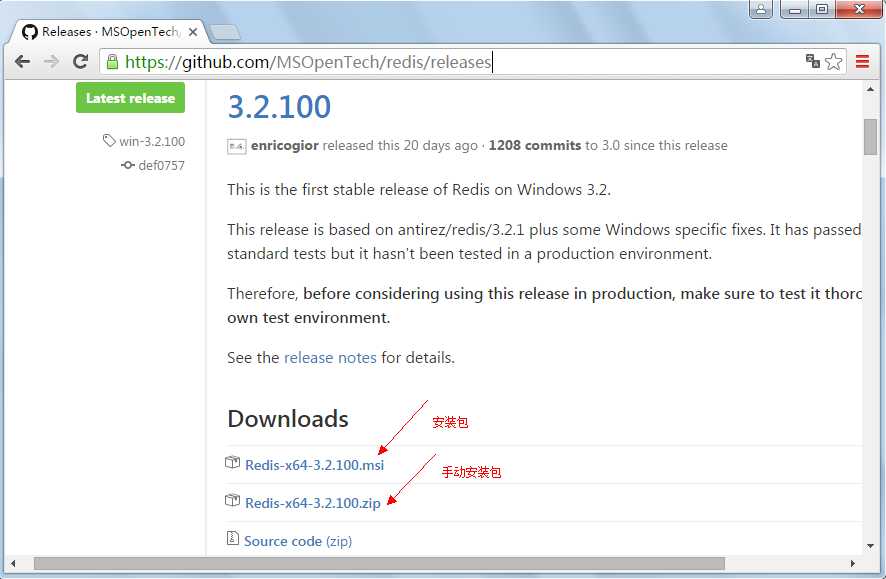
这里我们选择下载手动安装包Redis-x64-3.2.100.zip。如果是32位的可以下载源代码后自己编译出32位的版本,在https://github.com/dmajkic/redis/downloads可以下载到32的安装文件,不过版本有点旧了。
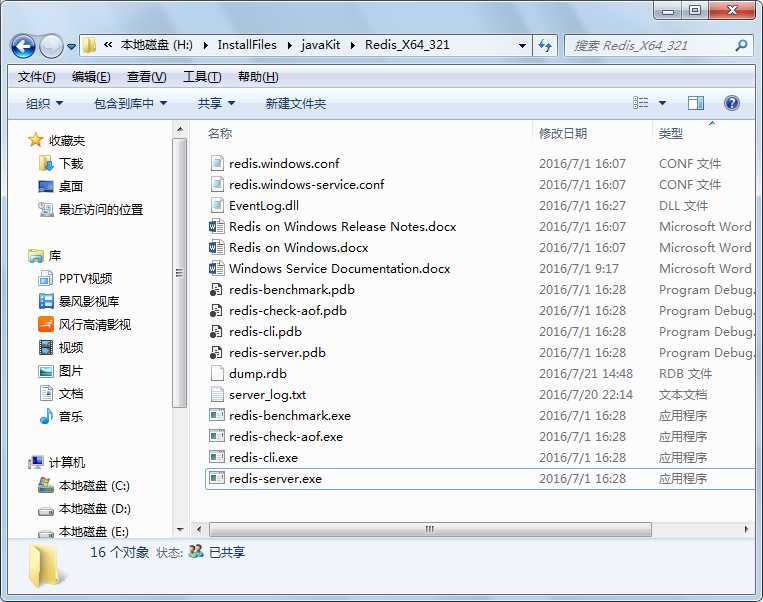
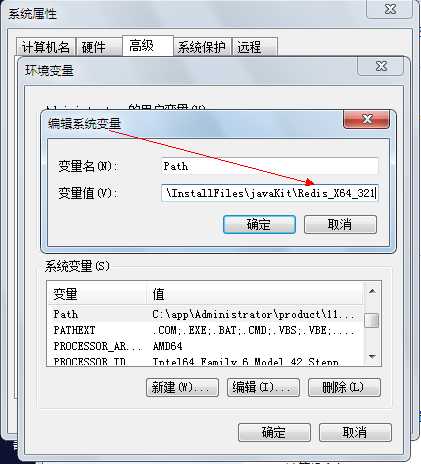
将下载后的安装包解压到磁盘中,最好是没有中文路径,没有特殊字符的目录下,比如:d:\redis目录下。为了更加方便的使用Redis,可以添加环境变量,在“系统环境变量”中的“Path”变量下添加redis路径,如下所示:
确定后启动cmd,运行redis-server测试。
在命令模式下运行:redis-server.exe redis.windows.conf,如果运行提示未找到conf文件,则把参数中的配置文件路径加上,如:
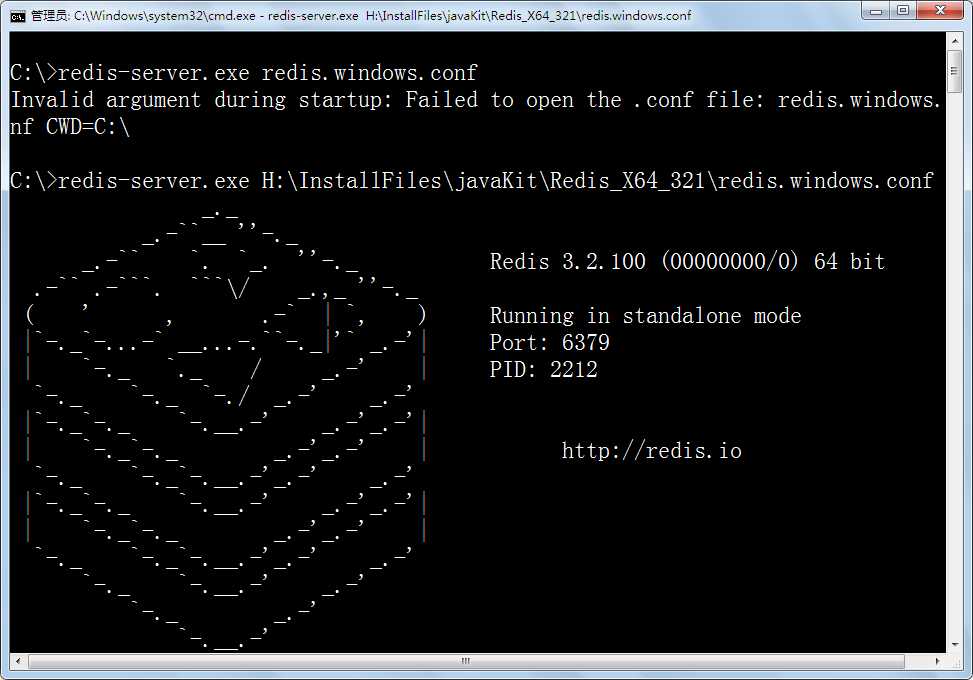
启动成功后会有一个字符界面,提示连接的端口号是:6379,请不要关闭该服务器,等待客户端连接;这里也可以把redis作成windows服务,不过redis多数情况会在linux平台使用。
再用cmd开启一个命令容器,输入命令:redis-cli -h 127.0.0.1 -p 6379,执行成功后如下所示:
-h用于指定服务器位置,-p用于指定端口号;如果想改变该内容可以修改.conf文件。
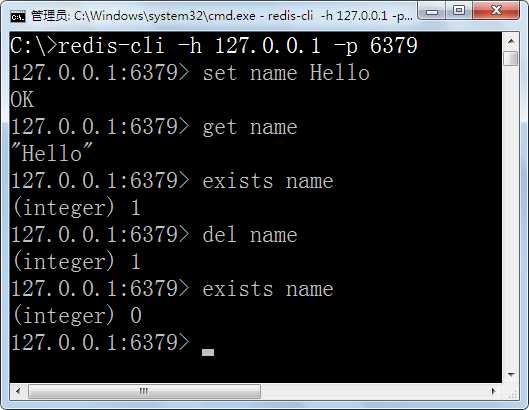
添加数据:set <key> <value>
获得数据:get <key>
是否存在:exists <key>
删除数据:del <key>
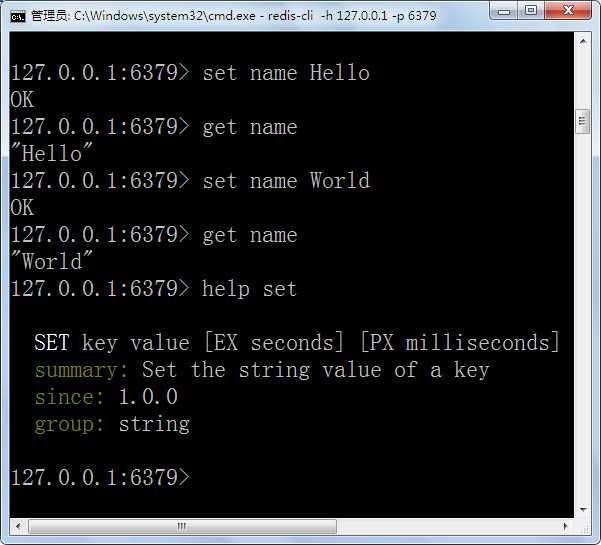
修改数据:set <key> <value>
帮助命令:help <命令名称>
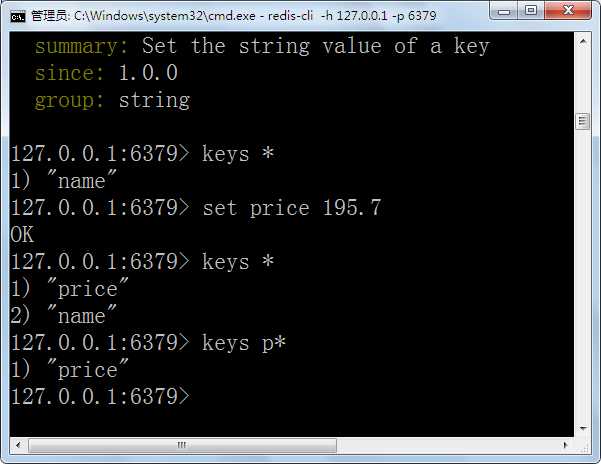
查找键:keys <名称能配符>
设置过期时间:expire <key> <秒数>
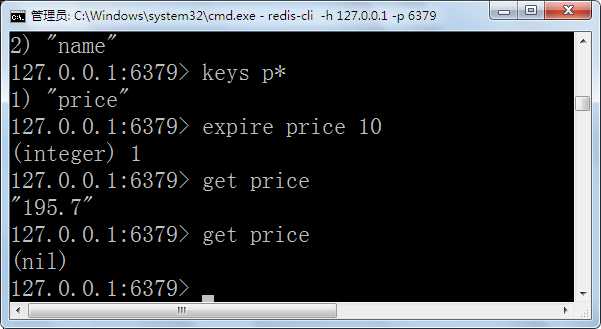
删除过期时间:persist <key>
info
服务器基本信息
monitor
实时转储收到的请求
config get
获取服务器的参数配置
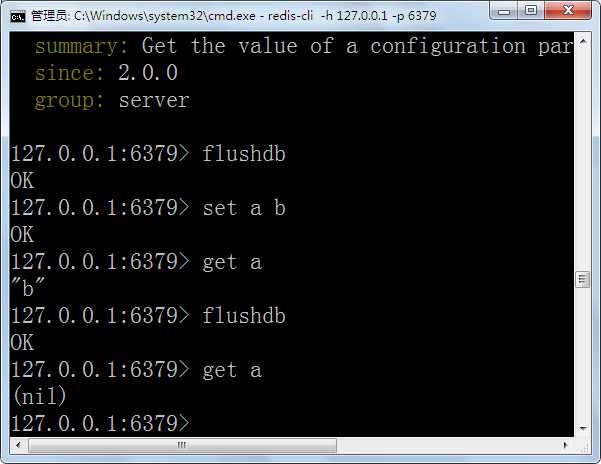
flushdb
清空当前数据库
flushall
清除所有数据库
更多命令:http://doc.redisfans.com/
三、常用命令
1)连接操作命令
quit:关闭连接(connection)
auth:简单密码认证
help cmd: 查看cmd帮助,例如:help quit
2)持久化
save:将数据同步保存到磁盘
bgsave:将数据异步保存到磁盘
lastsave:返回上次成功将数据保存到磁盘的Unix时戳
shundown:将数据同步保存到磁盘,然后关闭服务
3)远程服务控制
info:提供服务器的信息和统计
monitor:实时转储收到的请求
slaveof:改变复制策略设置
config:在运行时配置Redis服务器
4)对value操作的命令
exists(key):确认一个key是否存在
del(key):删除一个key
type(key):返回值的类型
keys(pattern):返回满足给定pattern的所有key
randomkey:随机返回key空间的一个
keyrename(oldname, newname):重命名key
dbsize:返回当前数据库中key的数目
expire:设定一个key的活动时间(s)
ttl:获得一个key的活动时间
select(index):按索引查询
move(key, dbindex):移动当前数据库中的key到dbindex数据库
flushdb:删除当前选择数据库中的所有key
flushall:删除所有数据库中的所有key
5)String
set(key, value):给数据库中名称为key的string赋予值value
get(key):返回数据库中名称为key的string的value
getset(key, value):给名称为key的string赋予上一次的value
mget(key1, key2,…, key N):返回库中多个string的value
setnx(key, value):添加string,名称为key,值为value
setex(key, time, value):向库中添加string,设定过期时间time
mset(key N, value N):批量设置多个string的值
msetnx(key N, value N):如果所有名称为key i的string都不存在
incr(key):名称为key的string增1操作
incrby(key, integer):名称为key的string增加integer
decr(key):名称为key的string减1操作
decrby(key, integer):名称为key的string减少integer
append(key, value):名称为key的string的值附加value
substr(key, start, end):返回名称为key的string的value的子串
6)List
rpush(key, value):在名称为key的list尾添加一个值为value的元素
lpush(key, value):在名称为key的list头添加一个值为value的 元素
llen(key):返回名称为key的list的长度
lrange(key, start, end):返回名称为key的list中start至end之间的元素
ltrim(key, start, end):截取名称为key的list
lindex(key, index):返回名称为key的list中index位置的元素
lset(key, index, value):给名称为key的list中index位置的元素赋值
lrem(key, count, value):删除count个key的list中值为value的元素
lpop(key):返回并删除名称为key的list中的首元素
rpop(key):返回并删除名称为key的list中的尾元素
blpop(key1, key2,… key N, timeout):lpop命令的block版本。
brpop(key1, key2,… key N, timeout):rpop的block版本。
rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
7)Set
sadd(key, member):向名称为key的set中添加元素member
srem(key, member) :删除名称为key的set中的元素member
spop(key) :随机返回并删除名称为key的set中一个元素
smove(srckey, dstkey, member) :移到集合元素
scard(key) :返回名称为key的set的基数
sismember(key, member) :member是否是名称为key的set的元素
sinter(key1, key2,…key N) :求交集
sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合
sunion(key1, (keys)) :求并集
sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合
sdiff(key1, (keys)) :求差集
sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合
smembers(key) :返回名称为key的set的所有元素
srandmember(key) :随机返回名称为key的set的一个元素
8)Hash
hset(key, field, value):向名称为key的hash中添加元素field
hget(key, field):返回名称为key的hash中field对应的value
hmget(key, (fields)):返回名称为key的hash中field i对应的value
hmset(key, (fields)):向名称为key的hash中添加元素field
hincrby(key, field, integer):将名称为key的hash中field的value增加integer
hexists(key, field):名称为key的hash中是否存在键为field的域
hdel(key, field):删除名称为key的hash中键为field的域
hlen(key):返回名称为key的hash中元素个数
hkeys(key):返回名称为key的hash中所有键
hvals(key):返回名称为key的hash中所有键对应的value
hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
如果不添加windows服务,redis-server.exe程序一直要以GUI的形式开启在任务栏,有时候不小心会被关闭,其实也可以像其它数据库如Oracle一样将redis做成一个服务,以服务的形式运行,注册服务的方法如下:
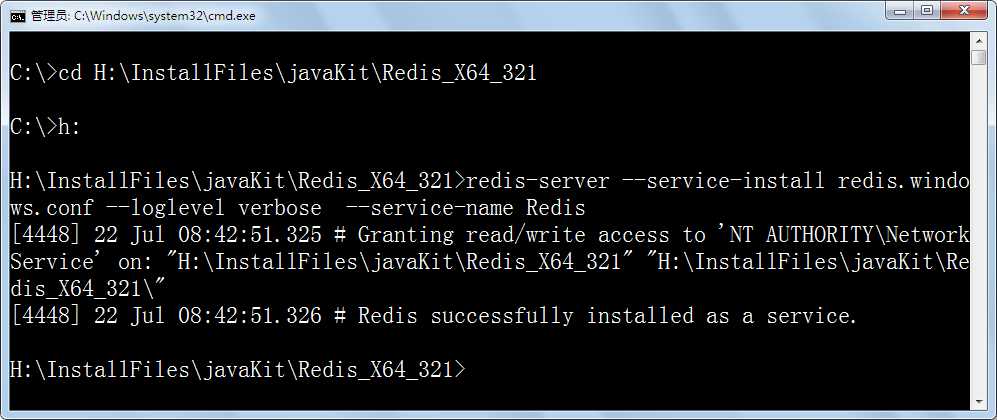
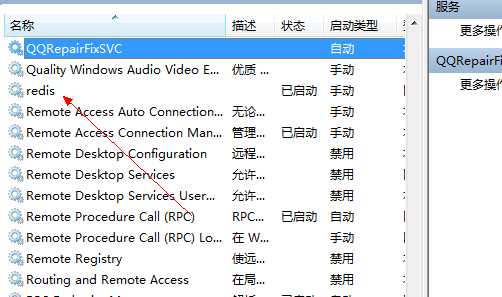
在windows服务列表中就可以看到redis服务了,可以将自动启动修改为手动启动:
如果电脑上安装了很多的服务,每次打开服务界面启动不是很方便,可以使用一个批处理完成。批处理脚本ServiceManager.bat如下:
@echo off :a echo 请选择要执行批处理命令: echo ------------------------------------------------------ echo 1 开启MSSQLServer echo 2 关闭MSSQLServer echo 3 开启Oracle echo 4 关闭Oracle echo 5 快速关机 echo 6 开启MySQL echo 7 关闭MySQL echo 8 开启Redis echo 9 关闭Redis echo ------------------------------------------------------ Set/p var1=请输入您要执行的指令:[1/2/3/4/5] if %var1% ==1 goto C1 if %var1% ==2 goto C2 if %var1% ==3 goto C3 if %var1% ==4 goto C4 if %var1% ==5 goto C5 if %var1% ==6 goto C6 if %var1% ==7 goto C7 if %var1% ==8 goto C8 if %var1% ==9 goto C9 echo. cls goto a: echo. :C1 net Start MSSQLServer /Y goto EndApp echo. :C2 net Stop MSSQLServer /Y goto EndApp echo. :C3 net Start OracleServiceORCL /Y net Start OracleOraDb11g_home1TNSListener /Y goto EndApp echo. :C4 net stop OracleServiceORCL /Y net stop OracleOraDb11g_home1TNSListener /Y goto EndApp echo. :C5 shutdown -s -f -t 0 goto EndApp echo. :C6 net Start MySQL /Y goto EndApp echo. :C7 net Stop MySQL /Y goto EndApp echo. :C8 net Start redis /Y goto EndApp echo. :C9 net Stop redis /Y goto EndApp echo. :EndApp Set/p var3=是否继续操作:[y/n] If %var3% == y goto a:
运行效果:
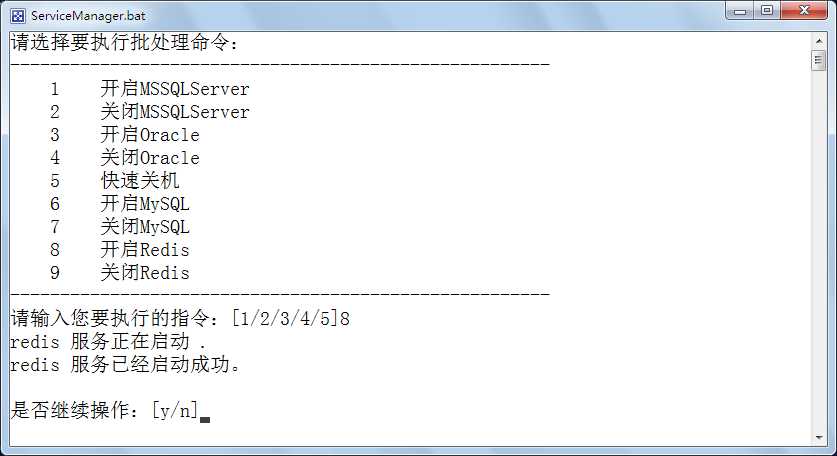
上面这部分可省略。
Jedis是redis的java版的客户端实现,在java程序中我们可以通过Jedis访问Redis数据库,源代码地址(https://github.com/xetorthio/jedis),实现访问的方法如下:
4.1.1、如果使用Maven,修改pom.xml文件,添加Jedis的依赖,修改后的pom.xml文件如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.zhangguo</groupId> <artifactId>JedisDemo</artifactId> <version>0.0.1</version> <dependencies> <!-- Jedis --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.8.1</version> </dependency> </dependencies> </project>
引用成功后的结果:
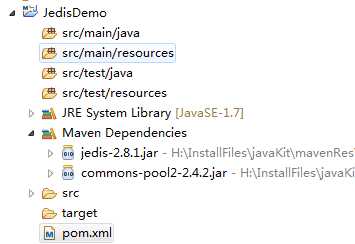
从引用的结果可以发现jedis使用了commons的连接池技术。
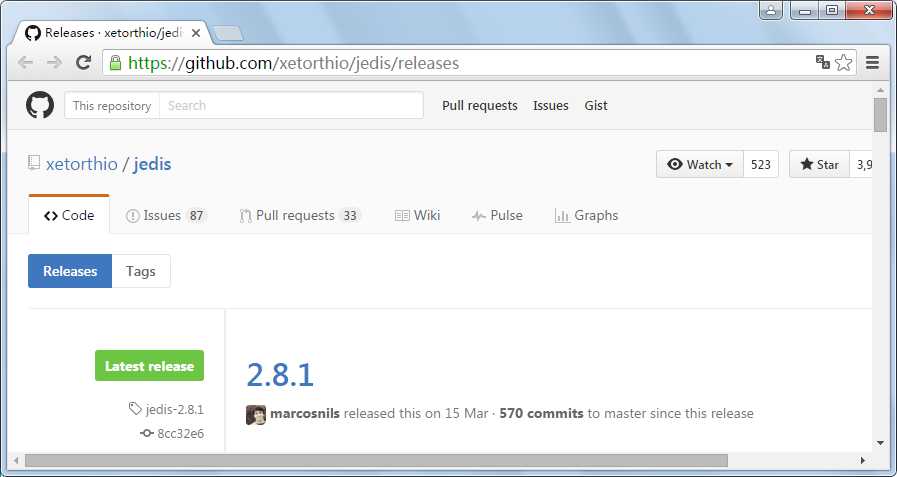
4.1.2、如果直接添加引用,可以去github下载jedis源码包自行编译,下载地址是:https://github.com/xetorthio/jedis/releases,当前最新版本2.8.1。
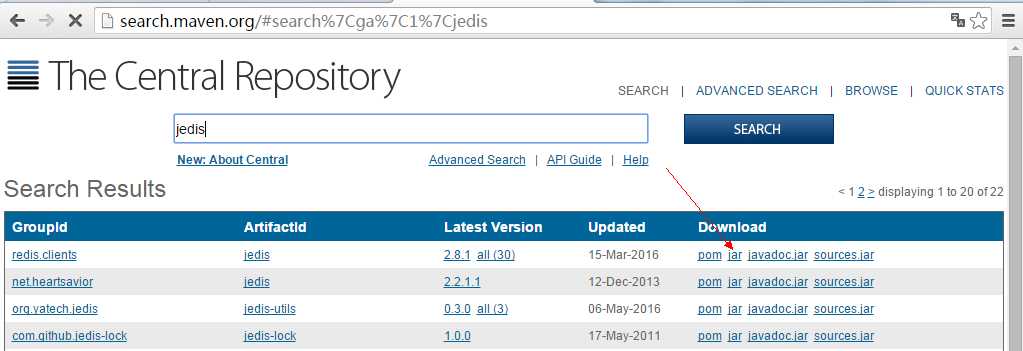
如果想直接下载jar包,可以到Maven共享资源库(http://search.maven.org/)下载,如下所示:
先开启redis数据库服务,处理监听状态,在java项目中编写如下测试代码:
package com.zhangguo.jedisdemo; import redis.clients.jedis.Jedis; public class HelloJedis { public static void main(String[] args) { //实例化一个jedis对象,连接到指定的服务器,指定连接端口号 Jedis jedis = new Jedis("127.0.0.1",6379); //将key为message的信息写入redis数据库中 jedis.set("message", "Hello Redis!"); //从数据库中取出key为message的数据 String value = jedis.get("message"); System.out.println(value); //关闭连接 jedis.close(); } }
运行结果:
Redis是一种高性能的数据库,可以选择持久化,也可以选择不持久化。如果要保存,就会存在数据同步的问题,可以简单认为一份数据放在内存中(快照),一份数据放在磁盘上,Redis提供了很灵活的持久化办法:
5.1、RDB持久化
该机制是指在指定的时间间隔内将内存中的数据集快照写入磁盘。 比如每隔15分钟有数据变化将内存中的数据与磁盘同步。
redis默认配置中就采用了该方法,如下所示:
# after 900 sec (15 min) if at least 1 key changed
15分种内如果有1个以上的内容发生了变化就执行保存
# after 300 sec (5 min) if at least 10 keys changed
5分种内如果有10个以上的内容发生了变化就执行保存
# after 60 sec if at least 10000 keys changed
1分种内如果有10000 个以上的内容发生了变化就执行保存
2). AOF持久化:
该机制将以日志的形式记录服务器所处理的每一个写操作,在Redis服务器启动之初会读取该文件来重新构建数据库,以保证启动后数据库中的数据是完整的。
3). 无持久化:
我们可以通过配置的方式禁用Redis服务器的持久化功能,这样我们就可以将Redis视为一个功能加强版的memcached了。
4). 同时应用AOF和RDB。
5.2、RDB机制的优势和劣势:
RDB存在哪些优势呢?
1). 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2). 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。
3). 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
4). 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
RDB又存在哪些劣势呢?
1). 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2). 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
5.3、AOF机制的优势和劣势:
AOF的优势有哪些呢?
1). 该机制可以带来更高的数据安全性,即数据持久性。Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。事实上,每秒同步也是异步完成的,其效率也是非常高的,所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。而每修改同步,我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。至于无同步,无需多言,我想大家都能正确的理解它。
2). 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
3). 如果日志过大,Redis可以自动启用rewrite机制。即Redis以append模式不断的将修改数据写入到老的磁盘文件中,同时Redis还会创建一个新的文件用于记录此期间有哪些修改命令被执行。因此在进行rewrite切换时可以更好的保证数据安全性。
4). AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
AOF的劣势有哪些呢?
1). 对于相同数量的数据集而言,AOF文件通常要大于RDB文件。
2). 根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
5.4、其它
5.4.1. Snapshotting:
缺省情况下,Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开6379.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
5.4.2. Dump快照的机制:
1). Redis先fork子进程。
2). 子进程将快照数据写入到临时RDB文件中。
3). 当子进程完成数据写入操作后,再用临时文件替换老的文件。
5.4.3. AOF文件:
上面已经多次讲过,RDB的快照定时dump机制无法保证很好的数据持久性。如果我们的应用确实非常关注此点,我们可以考虑使用Redis中的AOF机制。对于Redis服务器而言,其缺省的机制是RDB,如果需要使用AOF,则需要修改配置文件中的以下条目:
将appendonly no改为appendonly yes
从现在起,Redis在每一次接收到数据修改的命令之后,都会将其追加到AOF文件中。在Redis下一次重新启动时,需要加载AOF文件中的信息来构建最新的数据到内存中。
5.4.5. AOF的配置:
在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
5.4.6. 如何修复坏损的AOF文件:
1). 将现有已经坏损的AOF文件额外拷贝出来一份。
2). 执行"redis-check-aof --fix <filename>"命令来修复坏损的AOF文件。
3). 用修复后的AOF文件重新启动Redis服务器。
5.4.7. Redis的数据备份:
在Redis中我们可以通过copy的方式在线备份正在运行的Redis数据文件。这是因为RDB文件一旦被生成之后就不会再被修改。Redis每次都是将最新的数据dump到一个临时文件中,之后在利用rename函数原子性的将临时文件改名为原有的数据文件名。因此我们可以说,在任意时刻copy数据文件都是安全的和一致的。鉴于此,我们就可以通过创建cron job的方式定时备份Redis的数据文件,并将备份文件copy到安全的磁盘介质中。
5.5、立即写入
//立即保存,同步保存 public static void syncSave() throws Exception{ Jedis jedis=new Jedis("127.0.0.1",6379); for (int i = 0; i <1000; i++) { jedis.set("key"+i, "Hello"+i); System.out.println("设置key"+i+"的数据到redis"); Thread.sleep(2); } //执行保存,会在服务器下生成一个dump.rdb数据库文件 jedis.save(); jedis.close(); System.out.println("写入完成"); }
运行结果:

这里的save方法是同步的,没有写入完成前不执行后面的代码。
5.6、异步写入
//异步保存 public static void asyncSave() throws Exception{ Jedis jedis=new Jedis("127.0.0.1",6379); for (int i = 0; i <1000; i++) { jedis.set("key"+i, "Hello"+i); System.out.println("设置key"+i+"的数据到redis"); Thread.sleep(2); } //执行异步保存,会在服务器下生成一个dump.rdb数据库文件 jedis.bgsave(); jedis.close(); System.out.println("写入完成"); }
如果数据量非常大,要保存的内容很多,建议使用bgsave,如果内容少则可以使用save方法。关于各方式的比较源自网友的博客。
通过一个简单的汽车管理示例实现使用redis数据库完成增删改查功能。
6.1、定义一个名为Car的Bean
package com.zhangguo.entities; import java.io.Serializable; /* * 汽车类 */ public class Car implements Serializable { private static final long serialVersionUID = 1L; /* * 编号 */ private int id; /* * 车名 */ private String name; /* * 车速 */ private double speed; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public double getSpeed() { return speed; } public void setSpeed(double speed) { this.speed = speed; } public Car(int id, String name, double speed) { this.id = id; this.name = name; this.speed = speed; } public Car() { } @Override public String toString() { return "Car [id=" + id + ", name=" + name + ", speed=" + speed + "]"; } }
6.2、定义一个工具类,实现将序列化与反序列化功能
package com.zhangguo.utils; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.ObjectInputStream; import java.io.ObjectOutputStream; public class SerializeUitl { /** * 序列化 */ public static byte[] serialize(Object object) { ObjectOutputStream oos = null; ByteArrayOutputStream baos = null; try { baos = new ByteArrayOutputStream(); oos = new ObjectOutputStream(baos); oos.writeObject(object); byte[] bytes = baos.toByteArray(); return bytes; } catch (Exception e) { e.printStackTrace(); } return null; } /* * 反序列化 */ public static <T> T deSerialize(byte[] bytes,Class<T> clazz) { ByteArrayInputStream bais = null; try { bais = new ByteArrayInputStream(bytes); ObjectInputStream ois = new ObjectInputStream(bais); return (T)ois.readObject(); } catch (Exception e) { e.printStackTrace(); } return null; } }
6.3、定义一个CarDAO的数据访问类
package com.zhangguo.dao; import java.util.ArrayList; import java.util.List; import com.zhangguo.entities.Car; import com.zhangguo.utils.SerializeUitl; import redis.clients.jedis.Jedis; /* * 数据访问类 */ public class CarDAO { //汽车集合 private List<Car> cars; //初始化时加载所有的数据 public CarDAO() { load(); } /* * 将数据保存到redis数据库中 */ public void save() { Jedis jedis = new Jedis("127.0.0.1", 6379); jedis.set("cars".getBytes(), SerializeUitl.serialize(cars)); jedis.bgsave(); jedis.close(); } /* * 从redis数据库中加载数据 */ public void load() { Jedis jedis = new Jedis("127.0.0.1", 6379); byte[] byties = jedis.get("cars".getBytes()); if (byties != null && byties.length > 0) { cars = SerializeUitl.deSerialize(byties, Car.class); }else{ cars=new ArrayList<Car>(); } jedis.close(); } //添加 public void add(Car car){ this.cars.add(car); save(); } //获得对象通过编号 public Car getCarById(int id){ for (Car car : cars) { if(car.getId()==id){ return car; } } return null; } //移除 public void remove(int id){ cars.remove(getCarById(id)); save(); } //获得所有 public List<Car> getCars() { return cars; } //批量添加 public void setCars(List<Car> cars) { this.cars = cars; save(); } }
6.4、测试运行
package com.zhangguo.test; import java.util.ArrayList; import java.util.List; import org.junit.BeforeClass; import org.junit.Test; import com.zhangguo.dao.CarDAO; import com.zhangguo.entities.Car; public class CarTest { static CarDAO cardao; @BeforeClass public static void before(){ cardao=new CarDAO(); } /* * 批量添加 */ @Test public void testSetCars() { List<Car> cars=new ArrayList<Car>(); cars.add(new Car(1001, "Benz 600", 230)); cars.add(new Car(1002, "BMW X7+", 200)); cars.add(new Car(1003, "Audi A8", 180)); cardao.setCars(cars); } /* * 查询所有 */ @Test public void testGetCars() { for (Car car : cardao.getCars()) { System.out.println(car); } } /* * 增加一辆车 */ @Test public void testAdd() { cardao.add(new Car(1004,"BYD F8",150)); } /* * 根据编号获得一辆车 */ @Test public void testGetCarById() { System.out.println("----------获得编号为1001的车----------"); System.out.println(cardao.getCarById(1001)); } /* * 移除汽车 */ @Test public void testRemove() { System.out.println("----------移除编号为1004的车----------"); cardao.remove(1004); } }
运行结果

6.5、小结
这仅仅是一个示例,在功能与性能方面都有很大的改进空间,抛砖引玉罢了。
标签:
原文地址:http://www.cnblogs.com/best/p/5691947.html