标签:
集合是一个无序的,不重复的数据组合,它的主要作用如下:
>>> s = set([3,5,9,10]) #创建一个数值集合
>>> t = set("Hello") #创建一个唯一字符的集合
>>> s
{9, 10, 3, 5}
>>> t
{‘e‘, ‘H‘, ‘l‘, ‘o‘} #集和自动去重
>>> type(s),type(t)
(<class ‘set‘>, <class ‘set‘>) #集和类型
>>> len(s) #集和长度
4
>>> s==t
False
>>> s1=s
>>> s1
{9, 10, 3, 5}
>>> s1==s
True
由于集合本身是无序的,所以不能为集合创建索引或切片操作,只能循环遍历或使用in、not in来访问或判断集合元素。
>>> t
{‘e‘, ‘H‘, ‘l‘, ‘o‘}
>>> "e" in t
True
>>> "a" in t
False
>>> "a " not in t
True
>>> for i in t:
print(i)
e
H
l
o
可使用以下内建方法来更新:
s.add()
s.update()
s.remove()
注意只有可变集合(set创建的集和,frozense创建的集和是不可变集和)才能更新:
>>> s
{9, 10, 3, 5}
>>> t
{‘e‘, ‘H‘, ‘l‘, ‘o‘}
>>> s.add(1) #添加一个元素
>>> s
{9, 10, 3, 5, 1}
>>> s.update([0,2,4]) #添加多个元素
>>> s
{0, 1, 2, 3, 4, 5, 9, 10}
>>> t.add(‘python‘)
>>> t
{‘e‘, ‘H‘, ‘l‘, ‘python‘, ‘o‘}
>>> t.update(‘python‘) #添加一个字符会拆成多个
>>> t
{‘e‘, ‘y‘, ‘n‘, ‘h‘, ‘t‘, ‘p‘, ‘o‘, ‘python‘, ‘H‘, ‘l‘}
>>> t.remove(‘python‘) #删除一个元素
>>> t
{‘e‘, ‘y‘, ‘n‘, ‘h‘, ‘t‘, ‘p‘, ‘o‘, ‘H‘, ‘l‘}
x in s
测试 x 是否是 s 的成员
x not in s
测试 x 是否不是 s 的成员
s.issubset(t)
s <= t
测试是否 s 中的每一个元素都在 t 中
s.issuperset(t)
s >= t
测试是否 t 中的每一个元素都在 s 中
s.union(t)
s | t # t 和 s的并集
返回一个新的 set 包含 s 和 t 中的每一个元素
s.intersection(t)
s & t # t 和 s的交集
返回一个新的 set 包含 s 和 t 中的公共元素
s.difference(t)
s - t # 求差集(项在s中,但不在t中)
返回一个新的 set 包含 s 中有但是 t 中没有的元素
s.symmetric_difference(t)
s ^ t # 对称差集(项在t或s中,但不会同时出现在二者中)
返回一个新的 set 包含 s 和 t 中不重复的元素
s.copy()
返回 set “s”的一个浅复制
del:删除集和本身,如“del t”
>>> s and t #取t
{‘e‘, ‘y‘, ‘n‘, ‘h‘, ‘t‘, ‘p‘, ‘o‘, ‘H‘, ‘l‘}
>>> s or t #取s
{0, 1, 2, 3, 4, 5, 6, 9, 10}
>>> type(s)
<class ‘set‘>
>>> list(s) #转化为列表模式
[0, 1, 2, 3, 4, 5, 6, 9, 10]
>>> str(s) #转化为字符串模式
‘{0, 1, 2, 3, 4, 5, 6, 9, 10}‘
>>> type(str(s))
<class ‘str‘>
>>> tuple(s) #转化为元组
(0, 1, 2, 3, 4, 5, 6, 9, 10)

1 我越无所适从
2 越会事与愿违
3 在交错的时空
4 灵魂加速下坠
5 Here we are, here we are, here we are
f=open("haproxy.txt",encoding="utf-8") #默认读取模式
print(f) #不加参数,直接打印
‘‘‘
<_io.TextIOWrapper name=‘haproxy.txt‘ mode=‘r‘ encoding=‘utf-8‘>
‘‘‘
print(f.read()) #read参数,读取文件所有内容
‘‘‘
我越无所适从
越会事与愿违
在交错的时空
灵魂加速下坠
Here we are, here we are, here we are
‘‘‘
print(f.readline()) #readline,只读取文章中的一行内容
‘‘‘我越无所适从‘‘‘
print(f.readlines()) #readlines,把文章内容以换行符分割,并生成list格式,数据量大的话不建议使用
#[‘我越无所适从\n‘, ‘越会事与愿违\n‘, ‘在交错的时空\n‘, ‘灵魂加速下坠\n‘, ‘Here we are, here we are, here we are\n‘]
f.close() #关闭文件
f= open("har.txt",encoding="utf-8")
for index,line in enumerate(f.readlines()): #先把文件内容以行为分割生成列表,数据量大不能用
if index == 3:
print("-----我是分割线-------")
continue
print(line.strip())
count = 0
for line in f: #建议使用方法,每读取一行,内存会把之前的空间清空,不会占用太多内存,强推!!!
count +=1
if count == 4:
print("-----我是分割线-------")
continue
print(line.strip())
#我越无所适从
#越会事与愿违
#在交错的时空
#-----我是分割线-------
#Here we are, here we are, here we are
f= open("har.txt",encoding="utf-8") #文件句柄
data = f.read() #默认光标在起始位置,.read()读取完后,光标停留到文件末尾
data2 = f.read() #data2读取到的内容为空
print(data)
print("--------",data2)
f.close() #关闭文件
#我越无所适从
#越会事与愿违
#在交错的时空
#灵魂加速下坠
#Here we are, here we are, here we are
#--------
#用seek移动光标位置
f= open("har.txt",encoding="utf-8")
print(f.tell()) #tell 获取当前的光标位
print(f.readline().strip())
print(f.readline().strip())
print(f.readline().strip())
print(f.tell())
f.seek(0) #seek 移动光标到文件首部
print(f.readline().strip()) #从文件首部开始打印
f.close() #关闭文件
#0
#我越无所适从
#越会事与愿违
#在交错的时空
#60
#我越无所适从
3.模拟进度条
import sys,time #加载模块
for i in range(20):
sys.stdout.write("》")
sys.stdout.flush() #flush 强制刷新缓存到内存的数据写入硬盘
time.sleep(0.5)
#如果不用flush刷新会等全部》写如内存之后再写入硬盘,效果就是一次出来20个》,用的话就像进度读条一样了,不信试试看。
三、字符编码与转码
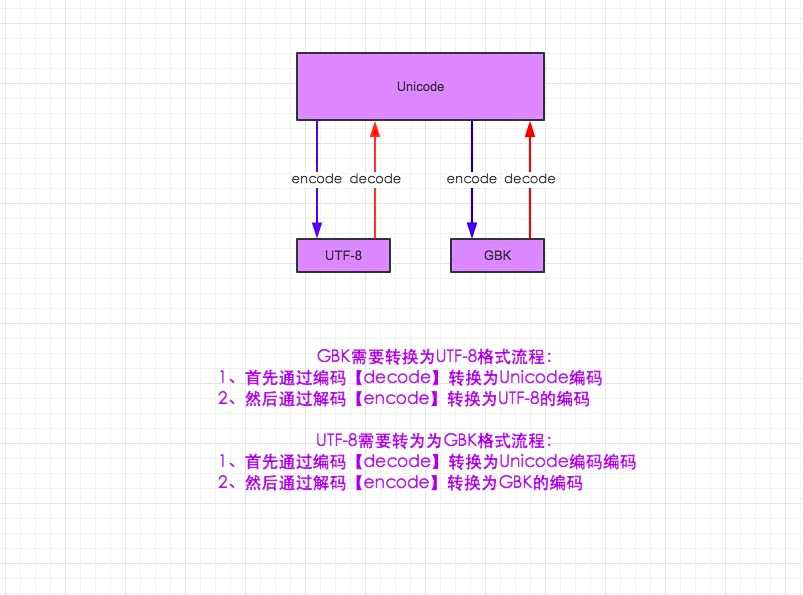
#同志们注意了上图非常牛b
import sys
print(sys.getdefaultencoding()) #显示字符编码
a_unicode="夫风起于青萍之末" #这个是unicode格式
print(a_unicode)
a_gbk=a_unicode.encode(‘gbk‘) #默认是unicode格式,转化为gbk格式
print(a_gbk)
a_gb2312=a_gbk.decode(‘gbk‘).encode(‘gb2312‘) #先decode转化为unicode格式,括号里告诉自己是gbk格式的,再encode转化,括号里写要转化的格式。
print(a_gb2312) #gbk是gb2312升级版,常用汉字的编码基本相同
a_unicode2=a_gbk.decode(‘gbk‘) #转化为unicode格式
print(a_unicode2)
‘‘‘
#执行结果在这里:
utf-8
夫风起于青萍之末
b‘\xb7\xf2\xb7\xe7\xc6\xf0\xd3\xda\xc7\xe0\xc6\xbc\xd6\xae\xc4\xa9‘
b‘\xb7\xf2\xb7\xe7\xc6\xf0\xd3\xda\xc7\xe0\xc6\xbc\xd6\xae\xc4\xa9‘
夫风起于青萍之末
‘‘‘
终于到函数了。。。下面是多方总结:
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
特性:
你可以定义一个由自己想要功能的函数,以下是简单的规则:
def sayhi():#函数名
print("Hello, I‘m nobody!")
sayhi() #调用函数
#下面这段代码
a,b = 5,8
c = a**b
print(c)
#改成用函数写
def calc(x,y):
res = x**y
return res #返回函数执行结果
c = calc(a,b) #结果赋值给c变量
print(c)
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量。
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值。

def printinfo( name, age = 18 ): #有默认参数时,如果age不传参就用默认的值。正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
print ("名字: ", name);
print ("年龄: ", age);
return;
#调用printinfo函数
printinfo( age=23, name="cheng" );
print ("------------------------")
printinfo( name="cheng" );
‘‘‘
名字: cheng
年龄: 23
------------------------
名字: cheng
年龄: 18
‘‘‘
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数。
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式
print(name,age,args)
stu_register("Alex",22)
#输出
#Alex 22 () #后面这个()就是args,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python")
#输出
# Jack 32 (‘CN‘, ‘Python‘)
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式
print(name,age,args,kwargs)
stu_register("Alex",22)
#输出
#Alex 22 () {}#后面这个{}就是kwargs,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong")
#输出
# Jack 32 (‘CN‘, ‘Python‘) {‘province‘: ‘ShanDong‘, ‘sex‘: ‘Male‘}
局部变量只在他的作用域内其起作用,也可以声明为全局变量,不过因为写代码长的时候随便声明可能会乱,所以不推荐。
def change_name(name):
print("before change:",name)
name = "里面的局部变量"
print("after change:", name)
name=(‘外面的全局变量‘)
change_name(name)
print("在外面看看name改了么?",name)
‘‘‘
before change: 外面的变量
after change 里面的变量
在外面看看name改了么? 外面的变量
‘‘‘
要想获取函数的执行结果,就可以用return语句把结果返回。
注意:
def calc(n):
print(n)
if int(n/2) ==0:
return n
return calc(int(n/2))
calc(10)
输出:
10
5
2
1
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
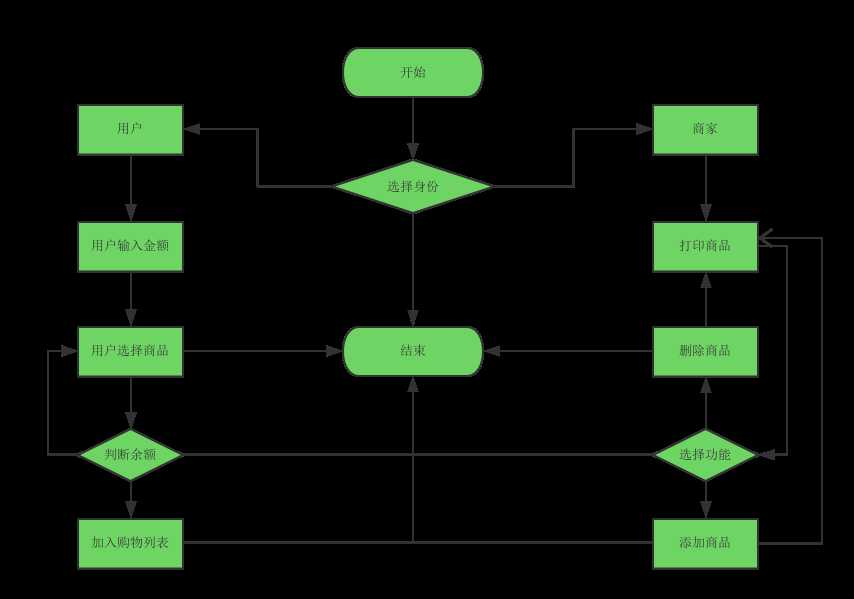
1 import random
2 shopping_list = []
3 shop_list = []
4 add = []
5 p = []
6 condition = True
7 identity_input = input(
8 "1. 用户\n"
9 "2. 商家\n"
10 "请选择对应身份序号[1|2]:")
11 if str.isdigit(identity_input):
12 identity_input = int(identity_input)
13 if identity_input == 1:
14 money_input = input("欢迎用户访问,输入购物金额:")
15 if money_input.isdigit():
16 money_input = int(money_input)
17 with open("shoplist.txt", encoding=‘utf-8‘) as file:
18 for list in file:
19 shop_list.append((list.strip().split()[0], list.strip().split()[1]))
20 while condition:
21 for index, i in enumerate(shop_list):
22 print((index+1), i)
23 choice = input("请输入选择的商品序号,选择完毕q退出:")
24 if choice.isdigit():
25 choice = int(choice)
26 if choice <= len(shop_list) and choice >= 0:
27 p = shop_list[choice-1]
28 a = int(p[1])
29 if a <= money_input: #买的起
30 shopping_list.append(p)
31 money_input -= a
32 print("增加了%s商品,你的钱剩余%s" % (p, money_input))
33 else:
34 print("余额不足,请重新选择,按q退出")
35 else:
36 print ("商品%s不存在" % choice)
37 elif choice == ‘q‘:
38 print("--------已购商品列表--------")
39 for w in shopping_list:
40 print(w)
41 print("余额为%s" % money_input)
42 exit()
43 elif identity_input == 2:
44 print("欢迎商家访问:")
45 with open("shoplist.txt", encoding=‘utf-8‘) as file:
46 for list in file:
47 shop_list.append((list.strip().split()[0], list.strip().split()[1]))
48 while True:
49 for index, i in enumerate(shop_list):
50 print((index+1), i)
51 business_input = input(
52 "1.删除\n"
53 "2.添加\n"
54 "按q退出\n"
55 "请选择删除还是添加1|2:")
56 if str.isdigit(business_input):
57 business_input = int(business_input)
58 if business_input == 1:
59 business_choice = int(input("请输入要删除的商品序号:"))
60 del shop_list[business_choice-1]
61 c = 0
62 with open(‘shoplist.txt‘, ‘w‘, encoding=‘utf-8‘) as d:
63 while c < len(shop_list):
64 d.write(shop_list[c][0])
65 d.write(‘ ‘)
66 d.write(shop_list[c][1])
67 d.write(‘\n‘)
68 c += 1
69 elif business_input == 2:
70 business_choice1 = input("请输入要添加的商品名称:")
71 business_choice2 = input("请输入要添加的商品价格:")
72 add.append(business_choice1)
73 add.append(business_choice2)
74 shop_list.append(add[-2:])
75 with open(‘shoplist.txt‘, ‘a‘, encoding=‘utf-8‘) as f:
76 f.write(business_choice1)
77 f.write(‘ ‘)
78 f.write(business_choice2)
79 f.write(‘\n‘)
80 else:
81 print("请输入正确的序号!!!!!!!!!!!!!!!!!!!!!!")
82 elif business_input == ‘q‘:
83 print("正在退出。。。 。。。")
84 exit()
85 else:
86 print("身份输入错误,程序退出。。。 。。。")
87 else:
88 print("输入错误,没有输入的身份序号。")
矿泉水 10
可乐 20
咖啡 30
橙汁 40
诸君共勉:
那些没有消灭你的东西,会使你变得更强壮。——弗里德里希·威廉·尼采
Python-Day3 Python基础进阶之集和/文件读写/函数
标签:
原文地址:http://www.cnblogs.com/cheng95/p/5752816.html
